服务发布
服务发布过程依赖 ServiceConfig 的 export 方法来激活发布服务,下面分析下 export 实现:
public synchronized void export() {......if (shouldDelay()) {// 延迟发布DELAY_EXPORT_EXECUTOR.schedule(this::doExport, getDelay(), TimeUnit.MILLISECONDS);} else {// 直接发布doExport();}exported();}
可以看到,Dubbo 的延迟发布是通过使用 ScheduledExecutorService 来实现的,可以通过调用 ServiceConfig 的 setDelay 方法来设置延迟发布时间。如果没有设置延迟时间,则直接调用 doExport 方法发布服务;如果设置了延迟发布,则等时间过期后调用 doExport 方法来发布服务。doExport 方法会先对 ServiceConfig 里面的属性进行合法性检查,我们主要看其内部最后调用的 doExportUrls 方法。
private void doExportUrls() {ServiceRepository repository = ApplicationModel.getServiceRepository();// 把当前待发布的服务类型记录到ServiceRepository中ServiceDescriptor serviceDescriptor = repository.registerService(getInterfaceClass());// 把当前待发布的服务实例记录到ServiceRepository中repository.registerProvider(getUniqueServiceName(), ref, serviceDescriptor, this, serviceMetadata);// 加载所有的服务注册中心对象List<URL> registryURLs = ConfigValidationUtils.loadRegistries(this, true);for (ProtocolConfig protocolConfig : protocols) {String pathKey = URL.buildKey(getContextPath(protocolConfig).map(p -> p + "/" + path).orElse(path), group, version);repository.registerService(pathKey, interfaceClass);// 根据发布协议和注册中心信息,执行具体的服务导出逻辑doExportUrlsFor1Protocol(protocolConfig, registryURLs);}}
可以看到 Dubbo 支持多注册中心,并且支持多个协议,一个服务如果有多个协议那么就都需要暴露,比如同时支持 dubbo 协议和 hessian 协议,那么需要将这个服务用两种协议分别向多个注册中心(如果有多个的话)暴露注册。下面再详细看下 doExportUrlsFor1Protocol 方法的实现逻辑:
private void doExportUrlsFor1Protocol(ProtocolConfig protocolConfig, List<URL> registryURLs) {......// 解析MethodConfig相关配置......// 如果为泛型调用,则设置泛型类型if (ProtocolUtils.isGeneric(generic)) {map.put(GENERIC_KEY, generic);map.put(METHODS_KEY, ANY_VALUE);} else {......// 正常调用设置拼接URL的参数}// 拼接URL对象String host = findConfigedHosts(protocolConfig, registryURLs, map);Integer port = findConfigedPorts(protocolConfig, name, map);URL url = new URL(name, host, port, getContextPath(protocolConfig).map(p -> p + "/" + path).orElse(path), map);// 导出服务:本地服务、远程服务String scope = url.getParameter(SCOPE_KEY);// 如果scope为null则不导出服务if (!SCOPE_NONE.equalsIgnoreCase(scope)) {// 如果scope不为remote,则导出本地服务if (!SCOPE_REMOTE.equalsIgnoreCase(scope)) {// 本地调用方式发布服务exportLocal(url);}// 如果scope不为local,则导出远程服务if (!SCOPE_LOCAL.equalsIgnoreCase(scope)) {// 如果有服务注册中心地址if (CollectionUtils.isNotEmpty(registryURLs)) {for (URL registryURL : registryURLs) {......// 生成Invoker对象Invoker<?> invoker = PROXY_FACTORY.getInvoker(ref, (Class) interfaceClass, registryURL.addParameterAndEncoded(EXPORT_KEY, url.toFullString()));DelegateProviderMetaDataInvoker wrapperInvoker = new DelegateProviderMetaDataInvoker(invoker, this);// 将Invoker通过具体的协议转换成Exporter// PROTOCOL是通过getAdaptiveExtension方法生成的适配器类,内部会根据URL参数调用对应实现类的export方法Exporter<?> exporter = PROTOCOL.export(wrapperInvoker);exporters.add(exporter);}} else {// 直连方式,发布服务过程Invoker<?> invoker = PROXY_FACTORY.getInvoker(ref, (Class) interfaceClass, url);DelegateProviderMetaDataInvoker wrapperInvoker = new DelegateProviderMetaDataInvoker(invoker, this);Exporter<?> exporter = PROTOCOL.export(wrapperInvoker);exporters.add(exporter);}// 元数据存储MetadataUtils.publishServiceDefinition(url);}}this.urls.add(url);}
Dubbo 服务导出分为本地导出与远程导出,本地导出使用了 injvm 协议,是一个伪协议,它不开启端口,不发起远程调用,只在 JVM 内直接关联,但执行 Dubbo 的 Filter 链。在默认情况下,Dubbo 同时支持本地导出与远程导出协议,可通过 ServiceConfig 的 setScope 方法设置,其中配置为 none 表示不导出服务,为 remote 表示只导出远程服务,为 local 表示只导出本地服务。
1. 创建 Invoker
从代码中可以看到,ProxyFactory 和 Protocol 都是扩展接口的适配器类。执行 ProxyFactory 的 getlnvoker 方法时,实际上是先执行扩展接口 ProxyFactory 的适配器类 ProxyFactory$Adaptive 的 getlnvoker 方法,其内部根据 URL 里的 proxy 的类型选择具体的代理工厂,这里默认 proxy 类型为 javassist,所以又调用了 JavassistProxyFactory 的 getlnvoker 方法获取了代理类。其实现如下:
public <T> Invoker<T> getInvoker(T proxy, Class<T> type, URL url) {final Wrapper wrapper = Wrapper.getWrapper(proxy.getClass().getName().indexOf('$') < 0 ? proxy.getClass() : type);return new AbstractProxyInvoker<T>(proxy, type, url) {@Overrideprotected Object doInvoke(T proxy, String methodName,Class<?>[] parameterTypes,Object[] arguments) throws Throwable {return wrapper.invokeMethod(proxy, methodName, parameterTypes, arguments);}};}
这里首先把服务实现类转换为 Wrapper 类,是为了减少反射的调用,这里返回的是 AbstractProxyInvoker 对象,其内部重写了 doInvoke 方法,并委托给 Wrapper 实现具体功能。到这里就完成了服务提供方实现类到
lnvoker 的转换。
2. 创建 Exporter
另外,当执行 Protocol 的 export 方法的时候,实际调用了 Protocol 的适配器类 ProtocoI$Adaptive 的 export 方法。如果为远程服务暴露,则其内部根据 URL 中 Protocol 的类型为 registry,会选择 Protocol 的实现类 RegistryProtocol。如果为本地服务暴露,则其内部根据 URL 中 Protocol 的类型为 injvm,会选择 Protocol 的实现类 InjvmProtocol。但由于 Dubbo SPI 的扩展点使用了 Wrapper 自动增强,这里还使用了
ProtocolFilterWrapper、ProtocolListenerWrapper、QosProtocoIWrapper 对其进行了增强,所以需要一层层调用才会调用到 RegistryProtocol 的 export 方法。
此时的 URL 内容为: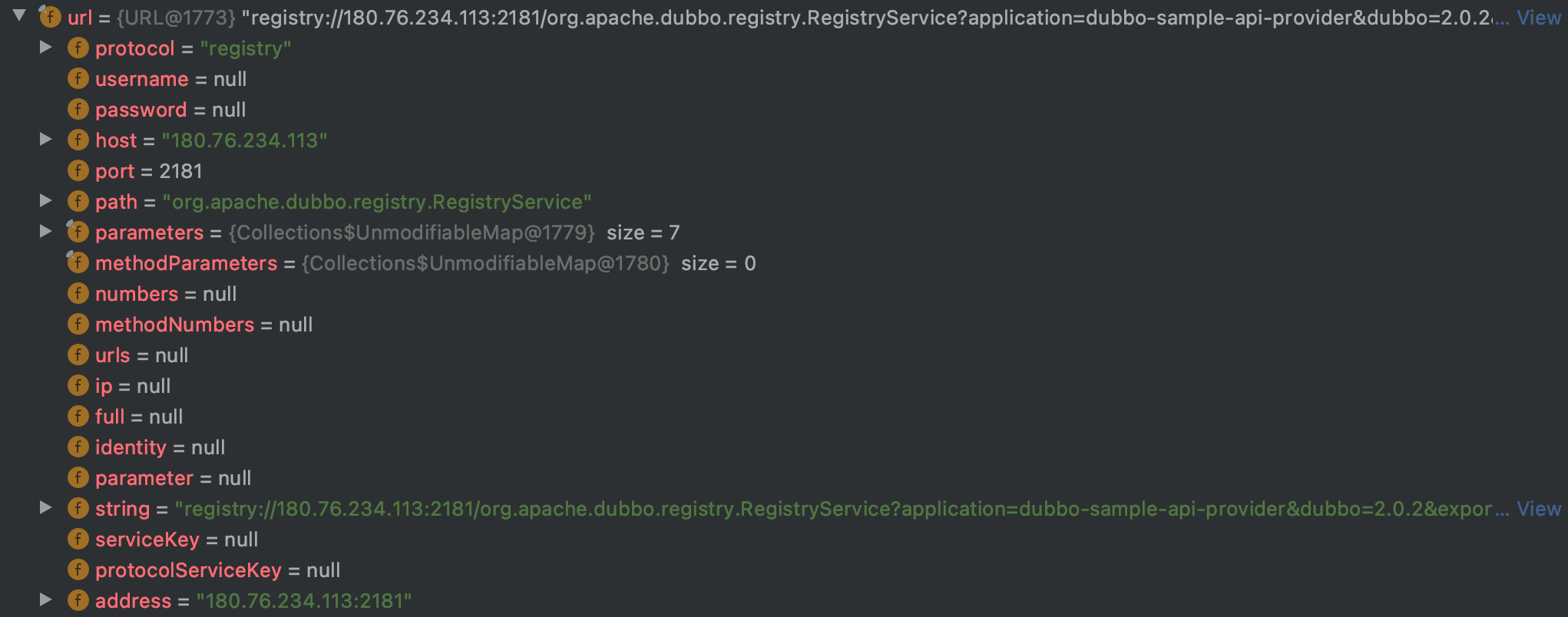
可以看到协议类型为 registry,所以这里调用的扩展接口的具体实现类就为 RegistryProtocol。
注意,RegistryProtocol 内部有一个 Protocol 属性,并为其提供了 setter 方法,根据 ExtensionLoader 创建扩展接口实例时的 IOC 特性,在创建 RegistryProtocol 实例时会自动为其注入一个 Protocol$Adaptive 实例。在 RegistryProtocol 调用其 protocol 属性的方法时,内部会再判断 URL 参数获取指定实现类。
public class RegistryProtocol implements Protocol {// 该属性会通过 IOC 容器注入进来,注入的是Protocol$Adaptive实例protected Protocol protocol;public void setProtocol(Protocol protocol) {this.protocol = protocol;}}
下面我们分析下 RegistryProtocol 的 export 实现:
public <T> Exporter<T> export(final Invoker<T> originInvoker) throws RpcException {......// 进行Invoker到Exporter的转换,并启动NettyServer进行监听服务final ExporterChangeableWrapper<T> exporter = doLocalExport(originInvoker, providerUrl);// 创建服务注册中心final Registry registry = getRegistry(originInvoker);final URL registeredProviderUrl = getUrlToRegistry(providerUrl, registryUrl);boolean register = providerUrl.getParameter(REGISTER_KEY, true);if (register) {// 注册服务到服务注册中心registry.register(registeredProviderUrl);}......return new DestroyableExporter<>(exporter);}
2.1 发布服务
RegistryProtocol 中的 doLocalExport 方法入参中的 URL 为: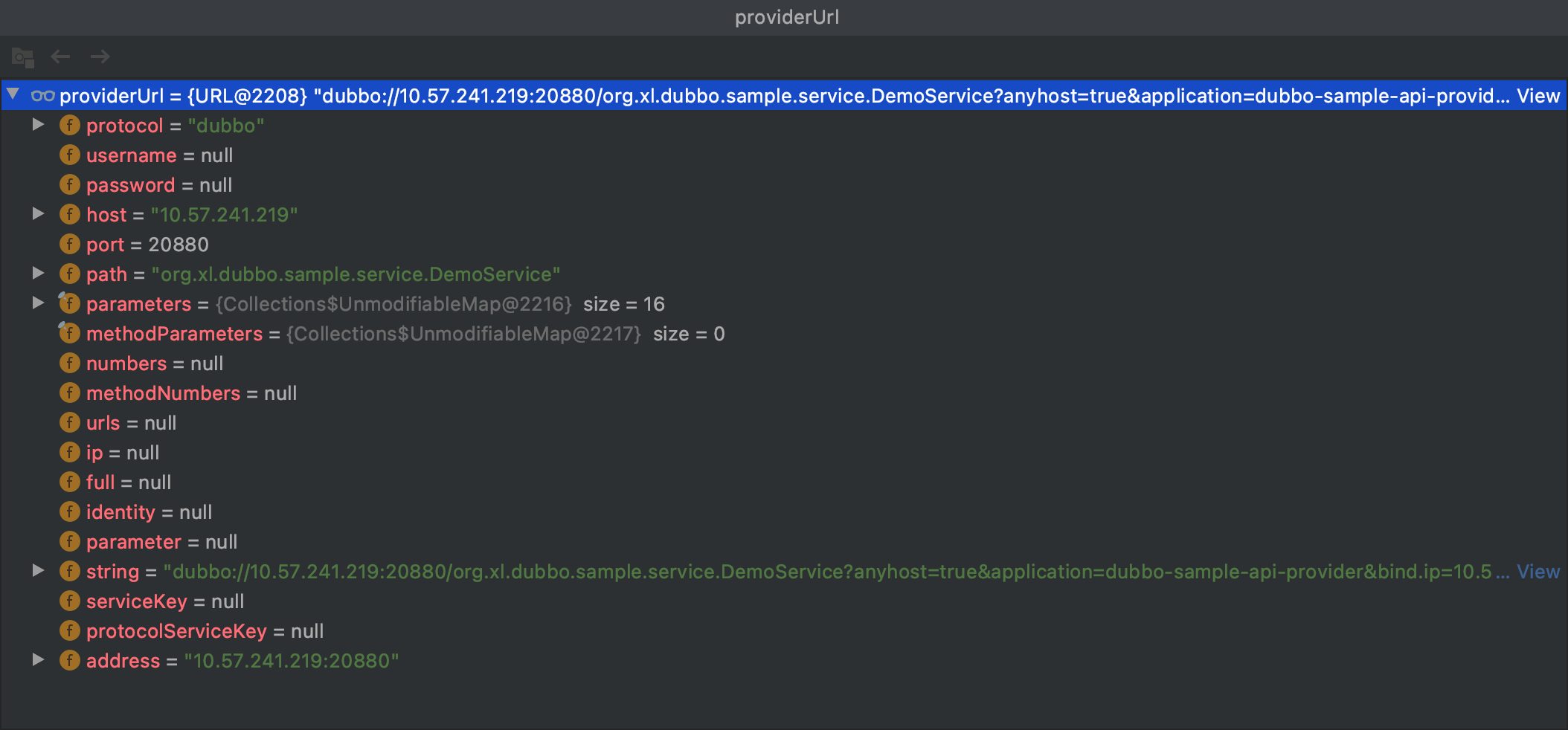
所以,在其内部调用 protocol 属性的方法时,实际上调用的是 DubboProtocol 的 export 方法,其逻辑如下:
public class DubboProtocol extends AbstractProtocol {@Overridepublic <T> Exporter<T> export(Invoker<T> invoker) throws RpcException {URL url = invoker.getUrl();// Invoker到Exporter的转换String key = serviceKey(url);DubboExporter<T> exporter = new DubboExporter<T>(invoker, key, exporterMap);exporterMap.put(key, exporter);......// 同一个机器的不同服务导出只会开启一个NettyServeropenServer(url);return exporter;}}
这里将 Invoker 转换为 DubboExporter 对象,并且把 DubboExporter 保存到了缓存 exporterMap 里(在服务提供方处理请求时会从中获取出来),然后执行 openServer 方法启动 NettyServer,其代码如下:
private void openServer(URL url) {// 服务提供者的地址,包括机器ip和portString key = url.getAddress();//只有服务提供端才会启动监听boolean isServer = url.getParameter(IS_SERVER_KEY, true);if (isServer) {// 判断是否有对应地址的ProtocolServer,没有则通过createServer方法进行创建// 所以当发布多个服务时,只有第一个会被创建,其余都是直接从缓存中返回ProtocolServer server = serverMap.get(key);if (server == null) {synchronized (this) {server = serverMap.get(key);if (server == null) {serverMap.put(key, createServer(url));}}} else {server.reset(url);}}}
在 createServer 方法中,最终会一步步调用到 Transporter 的 bind 方法,Transporter 也是扩展接口,所以也需要先经过其适配器类 Transporter$Adaptive 来根据 URL 里的参数做选择扩展实现。在默认情况下,传输扩展实现选择的是 netty,而 netty 对应的扩展为:
下面,我们就看看 NettyTransporter 的 bind 方法,其代码如下:
@Overridepublic RemotingServer bind(URL url, ChannelHandler handler) throws RemotingException {return new NettyServer(url, handler);}
NettyServer 的初始化逻辑在其父类 AbstractServer 的构造函数中,其内容如下:
public AbstractServer(URL url, ChannelHandler handler) throws RemotingException {......// 建立连接doOpen();}// doOpen在其子类NettyServer中实现@Overrideprotected void doOpen() throws Throwable {// 创建ServerBootstrapbootstrap = new ServerBootstrap();// 设置Netty的boss线程池和worker线程池bossGroup = NettyEventLoopFactory.eventLoopGroup(1, "NettyServerBoss");workerGroup = NettyEventLoopFactory.eventLoopGroup(getUrl().getPositiveParameter(IO_THREADS_KEY, Constants.DEFAULT_IO_THREADS),"NettyServerWorker");......bootstrap.group(bossGroup, workerGroup).channel(NettyEventLoopFactory.serverSocketChannelClass()).option(ChannelOption.SO_REUSEADDR, Boolean.TRUE).childOption(ChannelOption.TCP_NODELAY, Boolean.TRUE).childOption(ChannelOption.SO_KEEPALIVE, keepalive).childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT).childHandler(new ChannelInitializer<SocketChannel>() {@Overrideprotected void initChannel(SocketChannel ch) throws Exception {// 添加handler到接收连接的管线int idleTimeout = UrlUtils.getIdleTimeout(getUrl());NettyCodecAdapter adapter = new NettyCodecAdapter(getCodec(), getUrl(), NettyServer.this);if (getUrl().getParameter(SSL_ENABLED_KEY, false)) {ch.pipeline().addLast("negotiation",SslHandlerInitializer.sslServerHandler(getUrl(), nettyServerHandler));}ch.pipeline()// 编解码器.addLast("decoder", adapter.getDecoder()).addLast("encoder", adapter.getEncoder())// 心跳检查.addLast("server-idle-handler", new IdleStateHandler(0, 0, idleTimeout, MILLISECONDS))// 业务自定义.addLast("handler", nettyServerHandler);}});// 绑定本地端口,并启动监听服务ChannelFuture channelFuture = bootstrap.bind(getBindAddress());channelFuture.syncUninterruptibly();channel = channelFuture.channel();}
至此,服务提供方的 NettyServer 已经启动完成了。
2.2 服务注册
最后,我们看看在启动 NettyServer 后如何将服务注册到服务注册中心,这里我们使用 ZooKeeper 作为服务注册中心。接着 RegistryProtocol 的 export 中的实现流程,我们先看看 getRegistry 方法是如何获取服务注册中心的。getRegistry 方法通过 RegistryFactory 来获取服务注册中心,RegistryFactory 为扩展接口,所以这里通过适配器类来确定 RegistryFactory 的扩展实现为 ZookeeperRegistryFactory,然后后者内部又调用 createRegistry 方法创建了一个 ZookeeperRegistry 作为注册中心。
public class ZookeeperRegistryFactory extends AbstractRegistryFactory {@Overridepublic Registry createRegistry(URL url) {return new ZookeeperRegistry(url, zookeeperTransporter);}}
当得到注册中心后,接着 RegistryProtocol 的 export 方法分析,后续又调用了 Registry 的 registry 方法将服务注册到了 ZooKeeper 注册中心上。具体实现就是调用 zkClient 的 create 方法将服务注册到 ZK 上:
@Overridepublic void doRegister(URL url) {try {zkClient.create(toUrlPath(url), url.getParameter(DYNAMIC_KEY, true));} catch (Throwable e) {throw new RpcException("Failed to register " + url + " to zookeeper " + getUrl() + ", cause: " + e.getMessage(), e);}}
服务注册到 ZooKeeper 上后,ZooKeeper 服务端的最终树形结构如下图所示: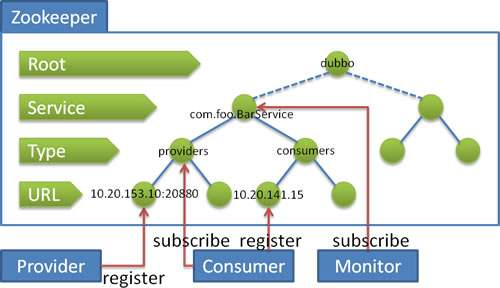
- 第一层 Root 节点说明 ZooKeeper 的服务分组为 Dubbo
- 第二层 Service 节点说明注册的服务为 com.foo.BarService 接口
- 第三层 Type 节点说明是为服务提供者注册的服务,还是为服务消费者注册的服务
- 第四层 URL 节点记录服务提供者、服务消费者的地址信息
第一个服务提供者注册时需要 ZooKeeper 服务端创建第一层的 Dubbo 节点、第二层的 Service 节点、第三层的 Type 节点,但是同一个 Service 的其他机器在注册服务时因为上面三层节点已经存在了,所以只需在 Providers 下也就是第四层插入服务提供者信息节点就可以了。
服务引用
服务引用过程依赖 ReferenceConfig 的 get 方法来引用已发布的服务,该方法内部的核心逻辑是通过 createProxy 方法创建了代理类。createProxy 方法逻辑如下:
private T createProxy(Map<String, String> map) {// 是否需要打开本地引用if (shouldJvmRefer(map)) {URL url = new URL(LOCAL_PROTOCOL, LOCALHOST_VALUE, 0, interfaceClass.getName()).addParameters(map);// 本地引用返回的 Invoker 就是服务暴露时保存在exporterMap中的对象invoker = REF_PROTOCOL.refer(interfaceClass, url);} else {urls.clear();// 用户是否指定服务提供方地址:可以是服务提供方IP地址(直连方式)if (url != null && url.length() > 0) {String[] us = SEMICOLON_SPLIT_PATTERN.split(url);if (us != null && us.length > 0) {for (String u : us) {URL url = URL.valueOf(u);if (StringUtils.isEmpty(url.getPath())) {url = url.setPath(interfaceName);}if (UrlUtils.isRegistry(url)) {// 如果是注册中心地址则将map转换为查询字符串,并作为refer参数的值添加到URL中urls.add(url.addParameterAndEncoded(REFER_KEY, StringUtils.toQueryString(map)));} else {如果是点对点,则合并url,移除服务提供者的一些配置urls.add(ClusterUtils.mergeUrl(url, map));}}}} else {// 没有配置url信息,则根据服务注册中心信息装配URL对象if (!LOCAL_PROTOCOL.equalsIgnoreCase(getProtocol())) {checkRegistry();// 加载服务注册中心信息,可以有多个。参数false表示不是providerList<URL> us = ConfigValidationUtils.loadRegistries(this, false);if (CollectionUtils.isNotEmpty(us)) {for (URL u : us) {// 如果配置了监控中心URL monitorUrl = ConfigValidationUtils.loadMonitor(this, u);if (monitorUrl != null) {map.put(MONITOR_KEY, URL.encode(monitorUrl.toFullString()));}urls.add(u.addParameterAndEncoded(REFER_KEY, StringUtils.toQueryString(map)));}}}}// 如果只有一个URL,则直接转换成Invokerif (urls.size() == 1) {invoker = REF_PROTOCOL.refer(interfaceClass, urls.get(0));} else {// 如果有多个URL,针对每个URL都创建一个Invoker实例List<Invoker<?>> invokers = new ArrayList<Invoker<?>>();URL registryURL = null;for (URL url : urls) {Invoker<?> referInvoker = REF_PROTOCOL.refer(interfaceClass, url);// 是否进行消费服务的检查if (shouldCheck()) {if (referInvoker.isAvailable()) {invokers.add(referInvoker);} else {referInvoker.destroy();}} else {invokers.add(referInvoker);}// 用最后一个注册中心的地址if (UrlUtils.isRegistry(url)) {registryURL = url;}}// 将多个Invoker包装到StaticDirectory,并由Cluster对多个Invoker进行合并,只暴露一个Invoker便于调用// 这个最终的Invoker实例用来执行一些集群中的降级策略以及负载均衡策略if (registryURL != null) {String cluster = registryURL.getParameter(CLUSTER_KEY, ZoneAwareCluster.NAME);invoker = Cluster.getCluster(cluster, false).join(new StaticDirectory(registryURL, invokers));} else {String cluster = CollectionUtils.isNotEmpty(invokers)? (invokers.get(0).getUrl() != null ? invokers.get(0).getUrl().getParameter(CLUSTER_KEY, ZoneAwareCluster.NAME) :Cluster.DEFAULT) : Cluster.DEFAULT;invoker = Cluster.getCluster(cluster).join(new StaticDirectory(invokers));}}}// 创建Invoker实例的代理对象return (T) PROXY_FACTORY.getProxy(invoker, ProtocolUtils.isGeneric(generic));}
1. 创建 Invoker
在上面的代码中,服务引用会调用 Protocol 扩展接口实现类的 refer 方法以生成 Invoker 实例,这里的 Protocol 也是一个适配器类,所以实际上调用的是 Protocol$Adaptive 的 refer 方法。在 Protocol$Adaptive 的 refer 方法内部,当我们设置了服务注册中心后,可以发现当前协议类型为 registry,也就是说这里要调用 RegistryProtocol 的 refer 方法,具体逻辑如下:
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {url = getRegistryUrl(url);// 获取注册中心实例Registry registry = registryFactory.getRegistry(url);Map<String, String> qs = StringUtils.parseQueryString(url.getParameterAndDecoded(REFER_KEY));......Cluster cluster = Cluster.getCluster(qs.get(CLUSTER_KEY));return doRefer(cluster, registry, type, url, qs);}
其内部主要是调用了 doRefer 方法,逻辑如下:
protected <T> Invoker<T> doRefer(Cluster cluster, Registry registry, Class<T> type, URL url, Map<String, String> parameters) {URL consumerUrl = new URL(CONSUMER_PROTOCOL, parameters.remove(REGISTER_IP_KEY), 0, type.getName(), parameters);ClusterInvoker<T> migrationInvoker = getMigrationInvoker(this, cluster, registry, type, url, consumerUrl);// 最终生成的对象为ServiceDiscoveryMigrationInvoker类型return interceptInvoker(migrationInvoker, url, consumerUrl);}
在 interceptInvoker 方法中,经过内置监听器的回调方法,最终会调用到 getServiceDiscoveryInvoker 方法:
public <T> ClusterInvoker<T> getServiceDiscoveryInvoker(Cluster cluster, Registry registry, Class<T> type, URL url) {// 新建一个DynamicDirectory对象,用来存储Invoker列表DynamicDirectory<T> directory = new ServiceDiscoveryRegistryDirectory<>(type, url);return doCreateInvoker(directory, cluster, registry, type);}protected <T> ClusterInvoker<T> doCreateInvoker(DynamicDirectory<T> directory, Cluster cluster, Registry registry, Class<T> type) {// 设置注册中心实例directory.setRegistry(registry);// 设置Protocol的适配器类 Protocol$Adaptivedirectory.setProtocol(protocol);Map<String, String> parameters = new HashMap<String, String>(directory.getConsumerUrl().getParameters());URL urlToRegistry = new URL(CONSUMER_PROTOCOL, parameters.remove(REGISTER_IP_KEY), 0, type.getName(), parameters);if (directory.isShouldRegister()) {directory.setRegisteredConsumerUrl(urlToRegistry);// 向注册中心注册服务消费者,即在 consumer 目录下创建新节点registry.register(directory.getRegisteredConsumerUrl());}// 建立路由规则链directory.buildRouterChain(urlToRegistry);// 订阅服务提供者地址directory.subscribe(toSubscribeUrl(urlToRegistry));// 封装集群容错策略到Invoker,封装directory其实就是封装多个Invokerreturn (ClusterInvoker<T>) cluster.join(directory);}
2. 订阅服务提供者地址
DynamicDirectory 实现了 NotifyListener 接口,在调用 subscribe 方法获取到服务提供者的地址列表后,会进行回调,触发其 notify 方法,具体实现在其子类 ServiceDiscoveryRegistryDirectory 中:
Map<String, Invoker<T>> newUrlInvokerMap = toInvokers(invokerUrls);private Map<String, Invoker<T>> toInvokers(List<URL> urls) {for (URL url : urls) {InstanceAddressURL instanceAddressURL = (InstanceAddressURL) url;// 这里调用Dubbo协议转换服务到InvokerInvoker<T> invoker = protocol.refer(serviceType, instanceAddressURL);}......}
在这一步,主要完成的操作是将获取到的最新的服务提供者 URL 地址,转换为具体的 Invoker 列表,也就是说每个提供者的 URL 都会被转换成一个 Invoker 对象。从上面的代码可知,将服务接口转换到 Invoker 对象是通过调用 Protocol 扩展接口的 refer 方法来完成的,这里的 protocol 对象也是 Protocol 扩展接口的适配器对象,所以实际上是调用适配器 Protocol$Adaptive 的 refer 方法。在 URL 中协议默认为是 dubbo,所以适配器里调用的应该是 DubboProtocol 的 refer 方法。
// AbstractProtocol中的refer方法实现public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {return new AsyncToSyncInvoker<>(protocolBindingRefer(type, url));}// DubboProtocol中的具体实现@Overridepublic <T> Invoker<T> protocolBindingRefer(Class<T> serviceType, URL url) throws RpcException {DubboInvoker<T> invoker = new DubboInvoker<T>(serviceType, url, getClients(url), invokers);invokers.add(invoker);return invoker;}
这段代码的重点在 getClients 方法中,在该方法中创建了服务消费端的 NettyClient 对象,该方法最终会调用到 Transporter 扩展接口的 connect 方法,前面说过 Transporter 的默认扩展实现为 NettyTransporter:
public class NettyTransporter implements Transporter {@Overridepublic Client connect(URL url, ChannelHandler handler) throws RemotingException {return new NettyClient(url, handler);}}
在创建 NettyClient 时,首先会确定 Dubbo 消费端内部的线程池模型,默认为 cached 模式。之后,会调用 doOpen 方法创建 NettyClient。最后,会调用 NettyClient 的 doConnect 方法与服务提供者建立链接。另外需要注意的是,在 NettyClient 的父类 AbstractEndpoint 中确定了编解码器,默认为 DubboCodec。
这里需要注意三点:第一点,由于同一个服务提供者机器可以提供多个服务,那么消费者机器需要与同一个服务提供者机器提供的多个服务共享连接,还是与每个服务都建立一个连接?第二点,消费端是启动时就与服务提供者机器建立好连接吗?第三点,每个服务消费端与服务提供者集群中的所有机器都有连接吗?
第一点,我们可以在 getClients 方法中找到答案,
private ExchangeClient[] getClients(URL url) {// 不同服务是否共享连接boolean useShareConnect = false;int connections = url.getParameter(CONNECTIONS_KEY, 0);List<ReferenceCountExchangeClient> shareClients = null;// 如果没配置,则默认连接是共享的,否则每个服务单独有自己的连接if (connections == 0) {useShareConnect = true;String shareConnectionsStr = url.getParameter(SHARE_CONNECTIONS_KEY, (String) null);connections = Integer.parseInt(StringUtils.isBlank(shareConnectionsStr) ? ConfigUtils.getProperty(SHARE_CONNECTIONS_KEY, DEFAULT_SHARE_CONNECTIONS) : shareConnectionsStr);// 获取共享的 NettyClientshareClients = getSharedClient(url, connections);}......return clients;}
通过上面的代码可以知道,在默认情况下当消费端引用同一个服务提供者机器上的多个服务时,这些服务复用一个 Netty 连接。下面我们从 initClient 方法里看第二个问题的答案:
private ExchangeClient initClient(URL url) {ExchangeClient client;try {// 惰性连接if (url.getParameter(LAZY_CONNECT_KEY, false)) {client = new LazyConnectExchangeClient(url, requestHandler);} else {// 立即连接client = Exchangers.connect(url, requestHandler);}} catch (RemotingException e) {throw new RpcException("Fail to create remoting client for service(" + url + "): " + e.getMessage(), e);}return client;}
可以看到,lazy 的默认值为 false,所以当消费端启动时就会与服务端机器建立连接。对于第三点,由于我们会遍历 URL 列表将其转换为 Invoker 对象,在这个过程中,服务消费端就会与服务提供者的所有机器建立连接。
最终,在 DynamicDirectory 中维护了所有服务提供者的 Invoker 列表,当消费端发起远程调用时就是根据集群容错和负载均衡算法以及路由规则从 Invoker 列表里选择一个进行调用的,当服务提供者宕机的时候,ZooKeeper 会通知更新这个 Invoker 列表。
3. 封装集群容错
下面,我们接着讲 RegistryProtocol 的 doRefer 逻辑中的 Cluster 的 join 方法是如何使用集群容错扩展将 Dubbo 协议的 Invoker 客户端转换为所需要的接口的。Cluster 扩展接口的默认实现类为 FailoverCluster,其 join 方法逻辑如下:
@Overridepublic <T> Invoker<T> join(Directory<T> directory) throws RpcException {return buildClusterInterceptors(doJoin(directory), directory.getUrl().getParameter(REFERENCE_INTERCEPTOR_KEY));}@Overridepublic <T> AbstractClusterInvoker<T> doJoin(Directory<T> directory) throws RpcException {return new FailoverClusterInvoker<>(directory);}private <T> Invoker<T> buildClusterInterceptors(AbstractClusterInvoker<T> clusterInvoker, String key) {AbstractClusterInvoker<T> last = clusterInvoker;List<ClusterInterceptor> interceptors = ExtensionLoader.getExtensionLoader(ClusterInterceptor.class).getActivateExtension(clusterInvoker.getUrl(), key);if (!interceptors.isEmpty()) {for (int i = interceptors.size() - 1; i >= 0; i--) {final ClusterInterceptor interceptor = interceptors.get(i);final AbstractClusterInvoker<T> next = last;last = new InterceptorInvokerNode<>(clusterInvoker, interceptor, next);}}return last;}
可以看到,其通过 doJoin 方法把 directory 对象包裹到了 FailoverClusterInvoker 里,并在 buildClusterInterceptors 方法中允许加载用户自定义的 ClusterInterceptor 实现类并构造成拦截器链,这主要是为了做扩展而提供的一个拦截器接口。
4. 创建代理类
在 ReferenceConfig 的 createProxy 方法的最后一行,通过 ProxyFactory 来获取代理类。这里默认调用的是 JavassistProxyFactory 的 getProxy 方法,其代码逻辑如下:
public <T> T getProxy(Invoker<T> invoker, Class<?>[] interfaces) {return (T) Proxy.getProxy(interfaces).newInstance(new InvokerInvocationHandler(invoker));}
其中,InvokerInvocationHandler 为具体的拦截器。当服务消费者执行服务方法时,实际上通过代理对象调用的就是 InvokerInvocationHandler 中的 invoke 方法。

若有收获,就点个赞吧
0 人点赞
