CopyOnWriteArrayList 是线程安全的 List,它的读取是完全不用加锁的,并且写入也不会阻塞读取操作,只有写入和写入之间需要进行同步等待,因此在读远大于写的场景下会有更好的性能。CopyOnWrite 的并发集合还包括 CopyOnWriteArraySet,其底层也是利用 CopyOnWriteArrayList 来实现的。
实现原理
所谓 Copy-On-Write 就是在执行写入操作时,并不修改原有的内容(这对于保证当前在读线程的数据一致性非常重要),而是进行一次自我复制,将修改的内容写入到副本中。写完之后,再用修改完的副本数据替换原来的数据,这样就可以保证写操作不会影响读了。
这样做的好处是,CopyOnWriteArrayList 利用了数组不变性原理,因为容器每次修改都是创建新副本,所以对于旧容器来说,其实是不可变的,也是线程安全的,因而无需进行同步操作。可以对 CopyOnWrite 容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素,也不会有修改。
我们可以通过以下图示来了解下 CopyOnWriteArrayList 的具体实现原理。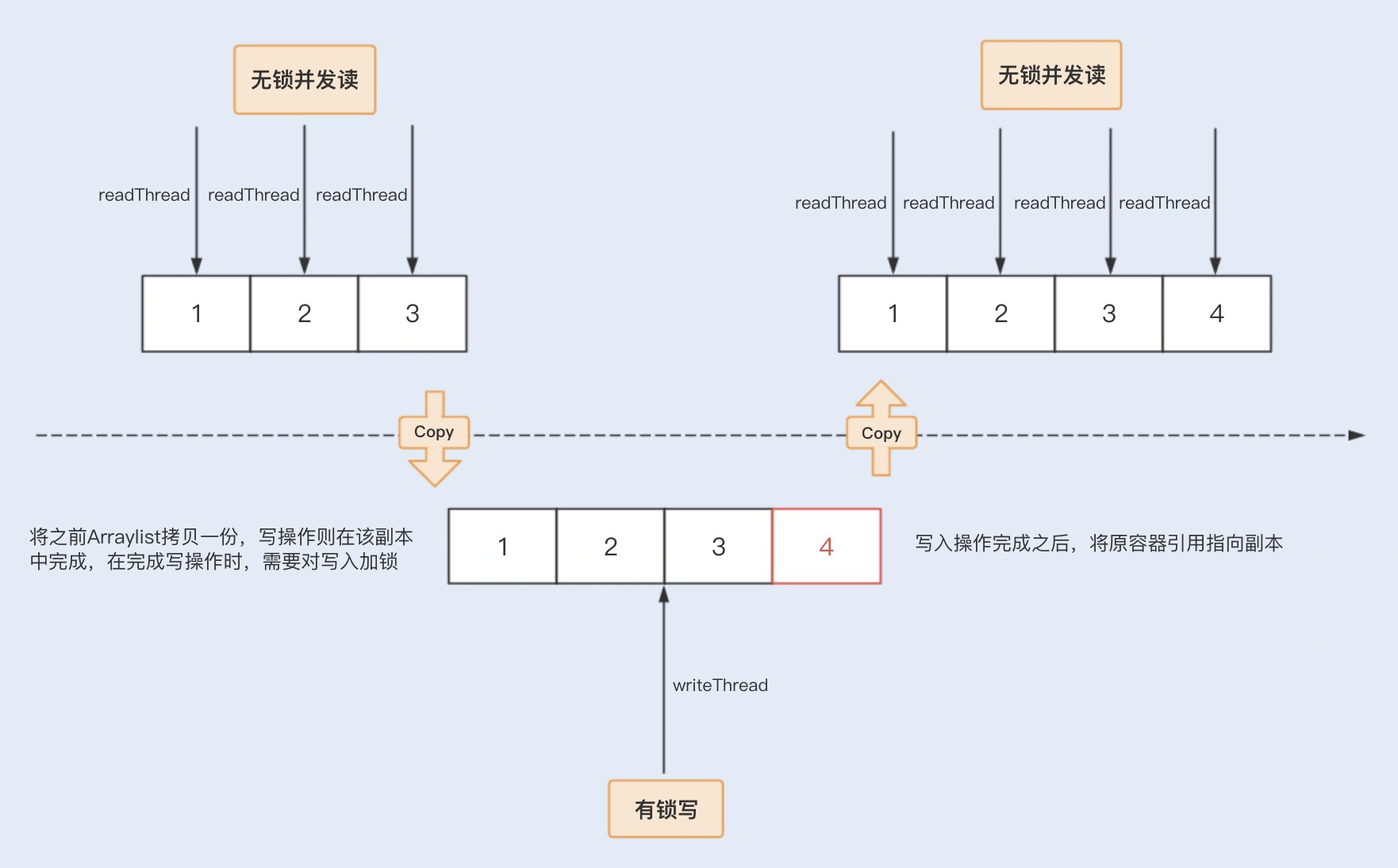
源码分析
public class CopyOnWriteArrayList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable {// 维护了一个重入锁,用于add、set、remove等修改数组的操作final transient ReentrantLock lock = new ReentrantLock();// 用于存储数据,用volatile修饰保证了写完对读线程立即可见private transient volatile Object[] array;......}
1. get
public E get(int index) {return get(getArray(), index);}private E get(Object[] a, int index) {return (E) a[index];}
可以看到,读的时候没有任何同步控制和加锁操作,理由就是内部数组 array 不会发生修改,因为写的时候不会锁住旧的CopyOnWriteArrayList,只会被另外一个 array 替换,因此可以保证数据安全,但无法读取到最新数据,不保证强一致性。
2. add
public boolean add(E e) {final ReentrantLock lock = this.lock;lock.lock();try {Object[] elements = getArray();int len = elements.length;// 复制原有的所有元素Object[] newElements = Arrays.copyOf(elements, len + 1);// 添加新元素newElements[len] = e;// 将新数组指向内部的array属性setArray(newElements);return true;} finally {lock.unlock();}}
add 操作使用 ReentrantLock 来控制并发写入,否则并发写入时会 Copy 出 N 个副本出来。其重点在于第 8 行代码进行了内部元素的完整复制,生成了一个新的数组 newElements,并将新元素加入 newElements,然后在第 12 行使用新的数组替换老的数组,修改就完成了。整个过程不会影响读取,并且修改完后,读取线程可以立即察觉到这个修改(因为 array 变量用 volatile 关键字修饰了)。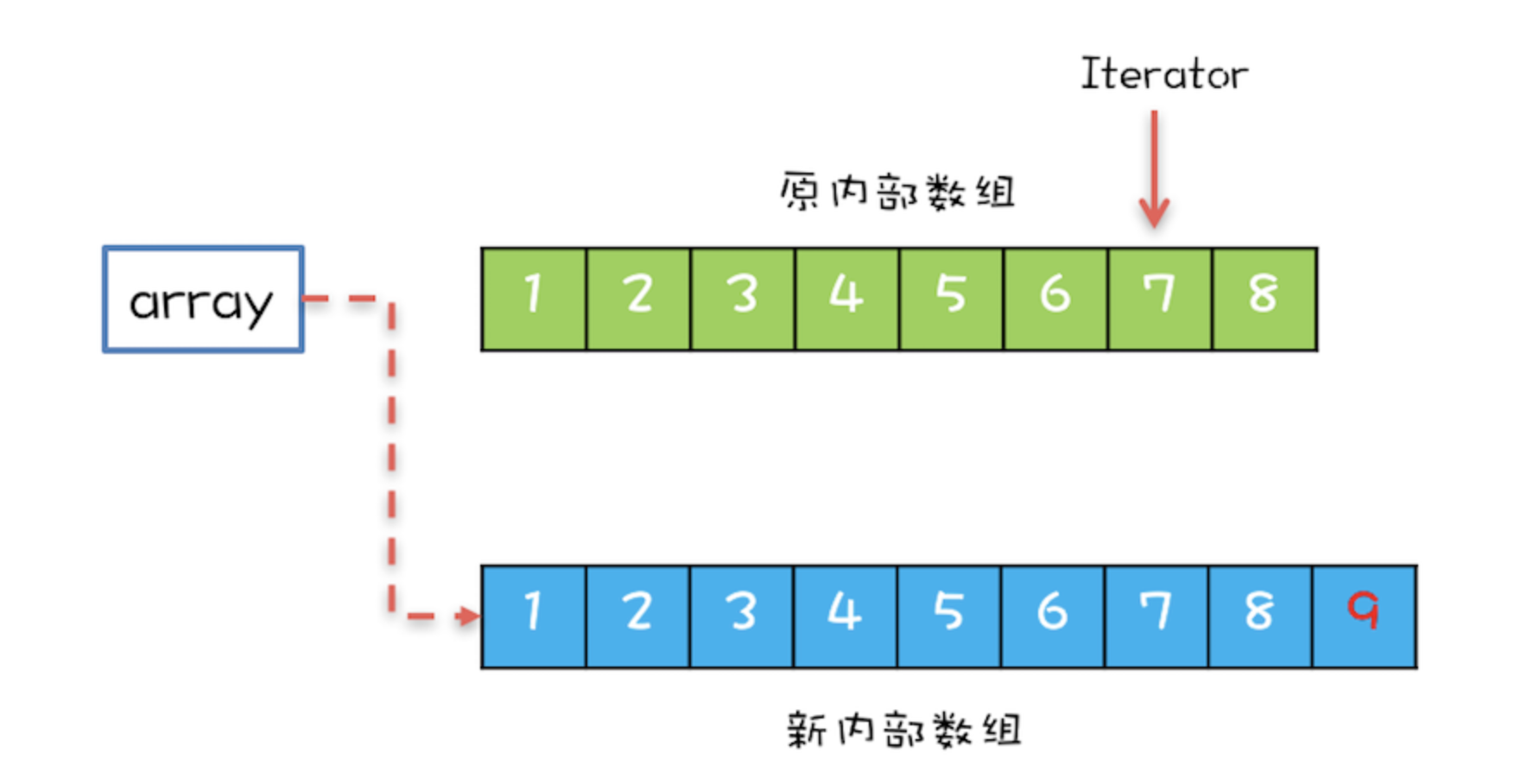
3. iterator
CopyOnWriteArrayList 还实现了 iterator 方法返回了一个自己实现的迭代器 COWIterator。
public Iterator<E> iterator() {return new COWIterator<E>(getArray(), 0);}
这个迭代器有两个重要的属性,分别是 snapshot 和 cursor。其中 snapshot 代表数组的快照,也就是创建迭代器的那个时刻的数组情况,而 cursor 则是迭代器的游标。迭代器的构造方法如下:
private COWIterator(Object[] elements, int initialCursor) {cursor = initialCursor;snapshot = elements;}
可以看到,迭代器在被创建的时候,会把当时的 elements 赋值给 snapshot,而之后的迭代器的所有操作都是基于 snapshot 数组进行的,所以在迭代期间,其它线程对原数组的修改并不会影响迭代器的执行。并且这个迭代器是只读的,因为它的 add、set、remove 方法均直接抛出 UnsupportedOperationException 异常,因此不支持在迭代过程中修改迭代器的元素。
优缺点
CopyOnWriteArrayList 对于数据的修改操作均在副本上完成,并基于 ReentrantLock 保证同一时间只有一个线程能够对底层数组执行修改操作。对于读多写少的场景来说,CopyOnWriteArrayList 能够在保证线程安全的同时媲美 ArrayList 的性能。
注意事项:
- 减少扩容开销。根据实际需要,初始化 CopyOnWriteArrayList 的大小,避免写时扩容的开销。
- 使用批量添加。因为每次添加,容器每次都会进行复制,所以减少添加次数,可以减少容器的复制次数。
线程在读取 CopyOnWriteArrayList 时都是拿到底层数组的一个最新快照,并在快照上执行读取操作,所以期间的修改结果对于读操作是不可见的,在读线程将引用重新指向原来的对象之前再次读到的数据是旧的,这也就导致了读写的弱一致性,所以 CopyOnWriteArrayList 只保证最终一致性,不适合用于数据的强一致性场合。
CopyOnWriteArrayList 容器适用于读多写少的场景。因为写操作时,需要复制一个容器,而当容器对象比较大的时候,占用的内存开销及 CPU 资源很大,可能会造成频繁的 Young GC 和 Full GC,从而使整个系统的性能下降。因此需要根据实际应用把握初始容器的大小。

若有收获,就点个赞吧
0 人点赞
