前几篇文章我们介绍了线程池、Future、CompletableFuture 和 CompletionService,仔细观察你会发现这些工具类都是在帮助我们站在任务的视角来解决并发问题。对于简单的并行任务,你可以通过“线程池 +Future”的方案来解决;如果任务之间有聚合关系,无论是 AND 聚合还是 OR 聚合,都可以通过 CompletableFuture 来解决;而批量的并行任务,则可以通过 CompletionService 来解决。
分治任务模型
上面这几种任务模型基本能覆盖日常工作中的并发场景了,但还有一种分治的任务模型没有覆盖到。分治,即分而治之,是一种解决复杂问题的思维方法和模式;具体指的是把一个复杂的问题分解成多个相似的子问题,然后再把子问题分解成更小的子问题,直到子问题简单到可以直接求解。理论上来讲,解决每一个问题都对应着一个任务,所以对于问题的分治,实际上就是对于任务的分治。
分治思想在很多领域都有广泛的应用,例如算法领域有分治算法:归并排序、快速排序等;大数据领域知名计算框架 MapReduce 背后的思想也是分治。Java 并发包里提供了一种叫做 Fork/Join 的并行计算框架,就是用来支持分治这种任务模型的。
分治任务模型可分为两个阶段:一个阶段是任务分解,也就是将任务迭代地分解为子任务,直至子任务可以直接计算出结果;另一个阶段是结果合并,即逐层合并子任务的执行结果,直至获得最终结果。
在这个分治任务模型里,任务和分解后的子任务具有相似性,这种相似性往往体现在任务和子任务的算法逻辑是相同的,但计算的数据规模是不同的。具备这种相似性的问题时,我们往往采用递归算法。
Fork-Join 使用
Fork/Join 是 JDK 7 提供的一个用于并行计算的框架,主要就是用来支持分治任务模型的,这个计算框架里的 Fork 对应的是分治任务模型里的任务分解,Join 对应的是结果合并。Fork/Join 计算框架主要包含两部分,一部分是分治任务的线程池 ForkJoinPool,另一部分是分治任务 ForkJoinTask。
1. ForkJoinTask
ForkJoinTask 是一个抽象类,它的方法有很多,最核心的是 fork() 和 join() 方法,其中 fork() 方法会异步地执行一个子任务,而 join() 方法则会阻塞当前线程来等待子任务的执行结果。
public abstract class ForkJoinTask<V> implements Future<V>, Serializable {public final ForkJoinTask<V> fork() {Thread t;if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)((ForkJoinWorkerThread)t).workQueue.push(this);elseForkJoinPool.common.externalPush(this);return this;}public final V join() {int s;if ((s = doJoin() & DONE_MASK) != NORMAL)reportException(s);return getRawResult();}}
源码中,fork() 方法先判断当前线程是不是一个 ForkJoinWorkerThread 的工作线程,如果是,则将任务加入到内部队列中,否则由 ForkJoinPool 提供的内部公用的 common 线程池来执行这个任务。这个设计意味着我们可以通过调用一个 ForkJoinTask 的 fork() 方法来直接提交任务到 ForkJoinPool.common 中执行。
public static void main(String[] args) throws InterruptedException, ExecutionException {// 创建一个计算任务,计算由1加到12CountTask countTask2 = new CountTask(1, 12);// 直接在main线程中调用 fork 来提交任务,countTask2.fork();// 没有创建线程池,使用的commonPool线程池countTask2.get();}
假如你要在程序进行分治处理,但你只处理一次,以后就不会用到,而且任务不算太大,不需要设置特定的参数,那么你肯定不想为此创建一个线程池,这时默认的提供的线程池将会很有用。
在 Java 1.8 中提供的 Stream API 里面的并行流也是以 ForkJoinPool 为基础的。默认情况下所有的并行流计算都使用的 ForkJoinPool.common,这个共享的 ForkJoinPool 默认的线程数是 CPU 的核数。所以如果存在 I/O 密集型的并行流计算任务的话,那么很可能会因为一个很慢的 I/O 计算而拖慢整个系统的性能。所以建议用不同的 ForkJoinPool 执行不同类型的计算任务。
1.1 子类实现
通常情况下,我们不需要直接继承 ForkJoinTask 类,只需要继承它的子类,ForkJoinTask 提供了两个子类:RecursiveAction 和 RecursiveTask,它们都是用递归的方式来处理分治任务的,且这两个子类都定义了一个抽象方法 compute(),不过区别是 RecursiveAction 定义的 compute() 没有返回值,而 RecursiveTask 定义的 compute() 方法是有返回值的。通常我们只需要继承 ForkJoinTask 类的这两个子类,并实现对应的 compute() 方法即可。
public abstract class RecursiveAction extends ForkJoinTask<Void> {protected abstract void compute();......}public abstract class RecursiveTask<V> extends ForkJoinTask<V> {protected abstract V compute();......}
在 compute() 方法里,我们首先判断任务是否足够小,如果足够小就直接执行任务。否则必须分割成两个子任务,每个子任务在调用 fork 方法时,又会进入 compute 方法,看看当前子任务是否需要继续分割成子任务。如果不需要继续分割,则执行当前子任务并返回结果,之后 join 方法会等待子任务执行完并得到执行结果。
1.2 异常处理
ForkJoinTask 在执行的时候可能会抛出异常,但是我们没办法在主线程里直接捕获异常,所以 ForkJoinTask 提供了 isCompletedAbnormally() 方法来检查任务是否已经抛出异常或已经被取消了,并且可以通过 ForkJoinTask 的 getException 方法获取异常。
if (task.isCompletedAbnormally()){System.out.println(task.getException());}
getException 方法返回一个 Throwable 对象,如果任务被取消了则返回 CancellationException。如果任务没有完成或者没有抛出异常则返回 null。
2. ForkJoinPool
ForkJoinTask 需要通过 ForkJoinPool 来执行。我们知道 ThreadPoolExecutor 本质上是一个生产者-消费者模式的实现,内部有一个任务队列,这个任务队列是生产者和消费者通信的媒介;ThreadPoolExecutor 可以有多个工作线程,但是这些工作线程都共享一个任务队列。
而 ForkJoinPool 本质上也是一个生产者-消费者模式的实现,但 ForkJoinPool 内部有多个任务队列,当我们提交任务到 ForkJoinPool 时,ForkJoinPool 根据一定的路由规则把任务提交到一个任务队列中,如果任务在执行过程中会创建出子任务,那么子任务会提交到工作线程对应的任务队列中。
public class ForkJoinPool extends AbstractExecutorService {// 任务队列数组,存储了所有任务队列,包括 内部队列 和 外部队列volatile WorkQueue[] workQueues;// 一个静态常量,ForkJoinPool 提供的内部公用的线程池static final ForkJoinPool common;// 默认的线程工厂类public static final ForkJoinWorkerThreadFactory defaultForkJoinWorkerThreadFactory;......}public class ForkJoinWorkerThread extends Thread {// 线程工作的线程池,即此线程所属的线程池final ForkJoinPool pool;final ForkJoinPool.WorkQueue workQueue; // work-stealing mechanics}
如果工作线程对应的任务队列空了,ForkJoinPool 支持一种叫做“任务窃取”的机制,如果工作线程空闲了,那它可以“窃取”其他工作任务队列里的任务。ForkJoinPool 中的任务队列采用的是双端队列,工作线程正常获取任务和窃取任务分别从任务队列不同的端消费,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行,这样避免了很多不必要的数据竞争。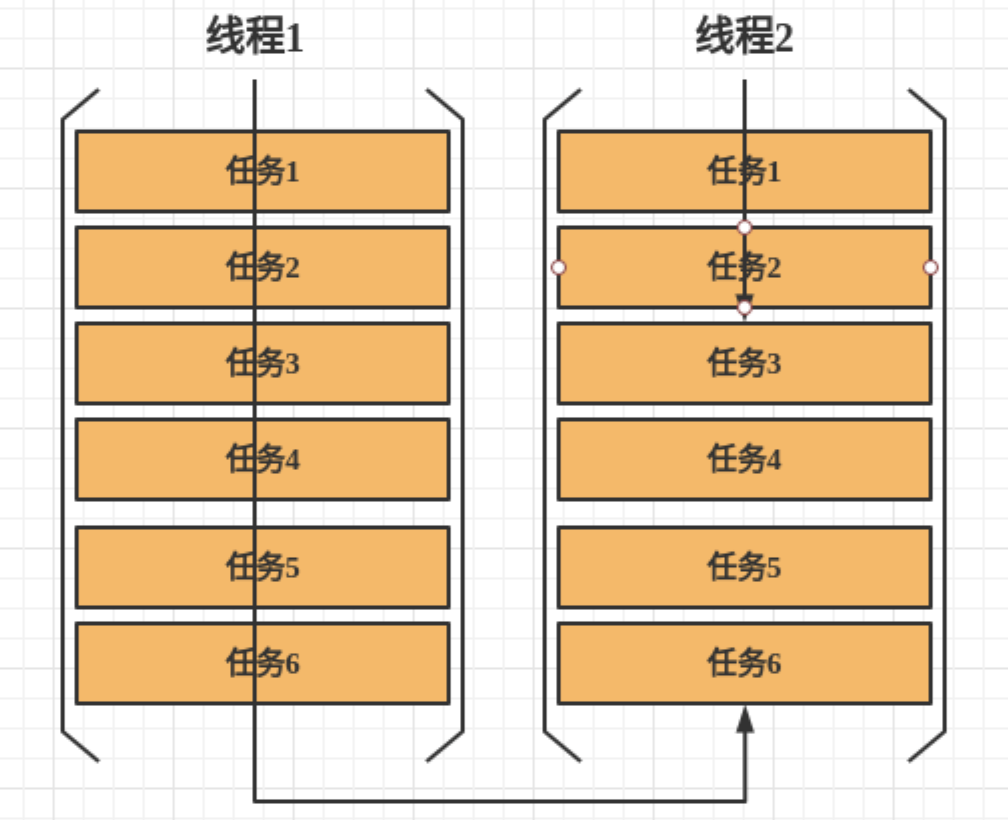
3. 代码示例
public class CountTask extends RecursiveTask<Integer> {// 任务最小分割的阈值private static final int THRESHOLD = 2;private int start;private int end;public CountTask(int start, int end) {this.start = start;this.end = end;}@Overrideprotected Integer compute() {int sum = 0;boolean canCompute = (end - start) <= THRESHOLD;if (canCompute) {// 如果任务足够小就计算任务for (int i = start; i <= end; i++) {sum += i;}} else {// 如果任务大于阈值,就分割成两个子任务进行计算int middle = (start + end) / 2;CountTask leftTask = new CountTask(start, middle);CountTask rightTask = new CountTask(middle + 1, end);// 执行子任务leftTask.fork();rightTask.fork();// 等待子任务执行完成int leftResult = leftTask.join();int rightResult = rightTask.join();sum = leftResult + rightResult;}return sum;}public static void main(String[] args) {ForkJoinPool forkJoinPool = new ForkJoinPool();CountTask task = new CountTask(1, 4);// 提交任务Future<Integer> result = forkJoinPool.submit(task);try {result.get();} catch (Exception e){}}}
参考链接:
http://gee.cs.oswego.edu/dl/papers/fj.pdf
https://www.jianshu.com/p/f777abb7b251

若有收获,就点个赞吧
0 人点赞
