Java 的 I/O 建立于流(stream)之上,输入流用来读取数据,输出流用来写入数据。不同的流会读、写某个特定的数据源,但所有输入、输出流都使用相同的基本方法来读取、写入数据。Reader 和 Writer 可以串链到输入流或输出流上,允许程序读、写文本(即字符)而不是字节。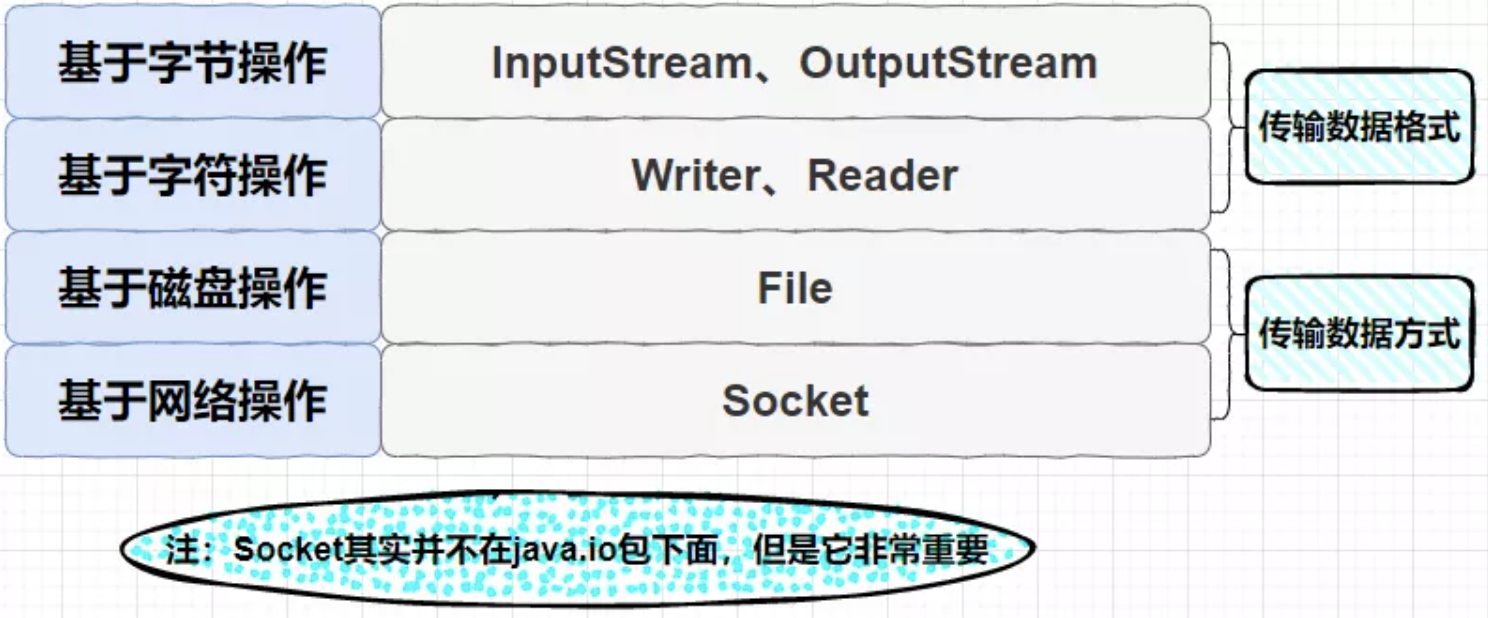
传统 IO 的交互方式是同步、阻塞的,当程序请求一个流读、写一段数据时,在读、写动作完成之前,线程会一直阻塞在那里,它们之间的调用是可靠的线性顺序。传统 IO 的好处是代码简单、直观,缺点则是 IO 效率和扩展性存在局限性,容易成为性能瓶颈。
因此在 Java 1.4 中引入了 NIO 框架,提供了 Channel、Selector、Buffer 等新的抽象,可以构建多路复用的、同步非阻塞 IO 程序,同时提供了更接近操作系统底层的高性能数据操作方式。并且在 Java 7 中 NIO 有了进一步改进,也就是 NIO 2,引入了异步非阻塞 IO 方式,也叫 AIO。AIO 基于事件和回调机制,即应用操作会直接返回,而不会阻塞在那里,当后台处理完成后,操作系统会通知相应线程进行后续工作。
字节流
字节流的基本单位为字节,一个 byte 通常为 8 位。字节流有两个基类:InputStream(输入字节流)和 OutputStream(输出字节流)。常用字节流的继承关系图如下图所示:
1. OutputStream
Java 的基本输出流是 java.io.OutputStream,这个类提供了写入数据所需的基本方法,包括:
public abstract class OutputStream implements Closeable, Flushable {public abstract void write(int b) throws IOException;public void write(byte b[]) throws IOExceptionpublic void write(byte b[], int off, int len) throws IOExceptionpublic void flush() throws IOExceptionpublic void close() throws IOException......}
OutputStream 的子类就使用这些方法向某种特定介质写入数据,例如 FileOutputStream 使用这些方法将数据写入文件,ByteArrayOutputStream 使用这些方法将数据写入可扩展的字节数组。
OutputStream 的基本方法是 write(int b),这个方法接受一个 0 到 255 之间的整数作为参数,用于将对应的字节写入到输出流中。这个方法声明为抽象方法,因为各个子类需要修改这个方法来处理特定的介质。注意,虽然这个方法接受一个 int 作为参数,但它实际上会写入一个无符号字节。Java 没有无符号字节数据类型,所以这里要使用 int 来代替。如果将一个超出 0 到 255 的 int 传入该方法,将写入这个数的最低字节,其他 3 字节将被忽略(这正是将 int 强制转换为 byte 的结果)。
一次写入 1 字节通常效率不高,如果有多字节要发送,则一次全部发送不失为一个好主意。使用 write(byte b[]) 或 write(byte b[], int off, int len) 通常比一次写入 data 数组中的 1 字节要快得多。
与在网络硬件中缓存一样,流还可以在软件中得到缓冲,可通过把 BufferedOutputStream 或 BufferedWriter 串链到底层流上来实现。因此,在写入数据完成后,刷新(flush)输出流非常重要。flush() 方法可以强迫缓冲的流发送数据,即使缓冲区还没有满。相应地,应当在关闭流之前立即刷新输出所有流。否则,关闭流时留在缓冲区中的数据可能会丢失。
最后,当结束一个流的操作时,要通过调用它的 close() 方法将其关闭。这会释放与这个流关联的所有资源,如文件句柄或端口。一旦输出流关闭,继续写入时就会抛出 IOException 异常。在一个长时间运行的程序中,如果未能及时关闭一个流,则可能会泄漏文件句柄、网络端口和其他资源
2. InputStream
Java 的基本输入流是 java.io.InputStream,这个类提供了将数据读取为原始字节所需的基本方法,包括:
public abstract class InputStream implements Closeable {public abstract int read() throws IOException;public int read(byte b[]) throws IOExceptionpublic int read(byte b[], int off, int len) throws IOExceptionpublic int available() throws IOExceptionpublic void close() throws IOException......}
InputStream 的子类就使用这些方法从某种特定介质中读取数据,例如 FileInputStream 使用这些方法从文件中读取数据,ByteArrayOutputStream 使用这些方法从字节数组中读取数据。
InputStream 的基本方法是没有参数的 read() 方法,这个方法从输入流的源中读取 1 字节数据,作为一个 0 到 255 的 int 返回,流的结束通过返回 -1 来表示,read() 方法会阻塞等待直到有 1 字节的数据可供读取。这个方法声明为抽象方法,因为各个子类需要修改这个方法来处理特定的介质。
与一次写入 1 字节的数据一样,一次读取 1 字节的效率也不高。因此,有两个重载的 read() 方法,可以用从流中读取的多字节的数据填充一个指定的数组:read(byte b[]) 尝试填充指定的字节数组、read(byte b[], int off, int len) 尝试填充指定的从 off 开始连续 len 字节的字节数组。注意:尝试填充有时不一定会成功,有时也只会填充部分字节,因此这些 read() 方法会返回实际读取的字节数。
下面示例从 inputStream 向数组 input 中读入 1024 个字节,注意要在循环中读取并且对 -1 进行判断:
int bytesRead = 0;int bytesToRead = 1024;byte[] input = new byte[bytesToRead];while(bytesRead < bytesToRead) {int result = inputStream.read(input, bytesRead, bytesToRead - bytesRead);if (result == -1) {break;}bytesRead += result;}
如果不想等待所需的全部字节都立即可用,可以使用 available() 方法来确定在不阻塞的情况下有多少字节可以读取。它会返回可以读取的最少字节数,事实上还能读取更多字节,但至少可以读取 available() 建议的字节数。
与输出流一样,一旦结束对输入流的操作,应当调用它的 close() 方法将其关闭。这会释放与这个流关联的所有资源,如文件句柄或端口。一旦输入流关闭,进一步读取这个流就会抛出 IOException 异常。
InputStream 还有 3 个不太常用的方法,允许程序备份和重新读取已经读取过的数据:
public synchronized void mark(int readlimit)public synchronized void reset() throws IOExceptionpublic boolean markSupported()
为了重新读取数据,要用 mark() 方法标记流的当前位置,在以后的某个时刻,可以用 reset() 方法把流重置到之前标记的位置,接下来的读取操作会返回从标记位置开始的数据。一个流在任何时刻都只能有一个标记,标记第二个位置会清除第一个标记。不过,不是所有输入流都支持重置,在尝试使用 mark 和 reset 之前,要先检查 markSupported() 方法是否返回 true。
读取字符串示例:
StringBuilder sb = new StringBuilder();for (int ch; (ch = inputStream.read()) != -1; ) {sb.append((char) ch);}String myString = sb.toString();
过滤器流
InputStream 和 OutputStream 是相当原始的类,为此 Java 又提供了很多过滤器类,通过装饰者模式可以附加到原始流中,在原始字节和各种格式之间来回转换。过滤器有两个版本:过滤器流以及 Reader/Writer,过滤器流主要将原始数据作为字节处理,而 Reader/Writer 用于操作字符,增加了字符编解码等功能,本质上计算机操作的都是字节,不管是网络通信还是文件读取,Reader/Writer 相当于构建了应用逻辑和原始数据间的桥梁。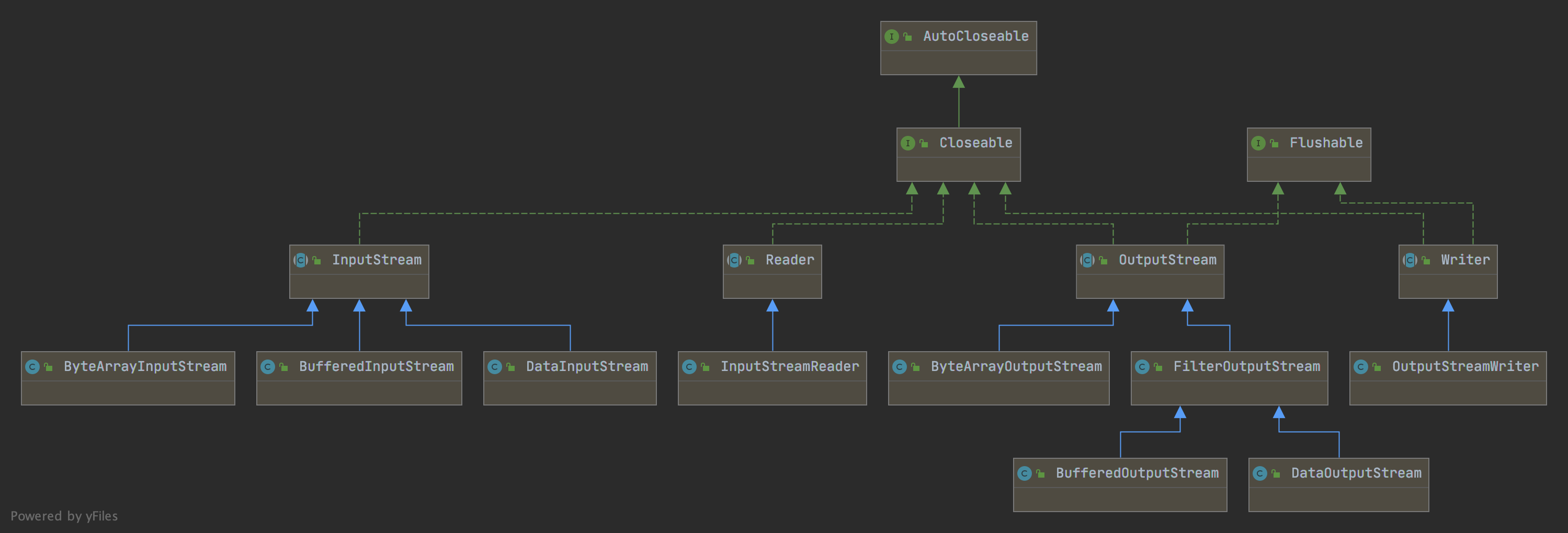
1. BufferedOutputStream
BufferedOutputStream 将写入的数据存储在缓冲区中,直到缓冲区满或刷新缓冲区,然后将数据一次性全部写入底层输出流。一次写入多个字节与多次写入少量字节相比要快得多。
对于网络连接尤其是这样,因为每个 TCP 片或 UDP 包本身都有一定数量的开销,一般约为 40 字节。这意味着,如果一次发送 1 字节,那么发送 1K 数据实际上需要发送 40K,而一次全部发送只需要发送 1K 多一点数据。大多数网卡和 TCP 实现自身都提供了一定程度的缓冲,所以实际数量不会那么夸张。但缓冲网络输出通常会带来巨大的性能提升。
public class BufferedOutputStream extends FilterOutputStream {protected byte buf[];protected int count;......}
BufferedOutputStream 没有声明自己的任何新公共方法,调用它的方法与调用任何输出流的方法是一样的。区别在于,每次写入会把数据放在缓冲区中,而不是直接放入底层的输出流。因此,需要发送数据时应用刷新输出流,这一点非常重要!
2. BufferedInputStream
BufferedInputStream 也有一个作为缓冲区的字节数组,当调用该类的 read() 方法时,它首先尝试从缓冲区获取请求的数据。只有当缓冲区没有数据时,流才从底层的源中读取数据。这时,它会从源中读取尽可能多的数据存入缓冲区,而不管是否马上需要所有这些数据。不会立即用到的数据可以在以后调用 read() 时读取。
当从本地磁盘中读取文件时,从底层流中读取几百字节的数据与读取 1 字节数据几乎一样快。因此,缓冲可以显著提升性能。对于网络连接,这种效果则不明显,在这里瓶颈往往是网络传送数据的速度,而不是网络接口向程序传送数据的速度。尽管如此,缓冲输入没有什么坏处,随着网络的速度加快会变得更为重要。
public class BufferedInputStream extends FilterOutputStream {protected volatile byte buf[];protected int count;protected int pos;protected int markpos = -1;protected int marklimit;......}
BufferedInputStream 也没有声明自己的任何新公共方法,只重写了 InputStream 的方法,支持标记和重置。重载的 read() 方法尝试根据需要多次从底层输入流中读取数据,从而完全填充指定的字节数组。只有当字节数组完全填满、到达流的末尾或底层流阻塞而无法进一步读取时,重载的这两个 read() 方法才返回。大多数输入流都不这样做,它们在返回前只从底层流或数据源中读取一次。
读取字符串示例:
BufferedInputStream bis = new BufferedInputStream(inputStream);ByteArrayOutputStream buf = new ByteArrayOutputStream();for (int result = bis.read(); result != -1; result = bis.read()) {buf.write((byte) result);}String myString = buf.toString("UTF-8");
字符流
字符流的基本单位为 Unicode,大小为两个字节(Byte),通常用来处理文本数据。Java 提供了字符流的两个基类:java.io.Reader 指定读字符的 API、java.io.Writer 指定写字符的 API。对应输入和输出流使用字节的地方 Reader/Writer 会使用 Unicode 字符。常用字符流的继承关系图如下图所示:
Reader/Writer 最重要的具体子类是 InputStreamReader 和 OutputStreamWriter 类。把面向字节的接口改为面向字符的接口。InputStreamReader 包含一个底层输入流,可以从中读取原始字节,并根据指定的编码方式将这些字节转换为 Unicode 字符。OutputStreamWriter 从运行的程序中接收 Unicode 字符,然后使用指定的编码方式将这些字符转换为字节,再将这些字节写入底层输出流中。
1. Writer
Writer 类是 OutputStream 类的映射,它是一个抽象类,主要有 5 个 write() 方法,另外还有 flush() 和 close() 方法:
public abstract class Writer implements Appendable, Closeable, Flushable {public void write(int c) throws IOExceptionpublic void write(char cbuf[]) throws IOExceptionpublic abstract void write(char cbuf[], int off, int len) throws IOException;public void write(String str) throws IOExceptionpublic void write(String str, int off, int len) throws IOException......}
其中 write(char cbuf[], int off, int len) 是基础方法,其他四个 write() 都是根据它实现的。子类至少要重写这个方法及 flush() 和 close() 方法。
2. OutputStreamWriter
OutputStreamWriter 是 Writer 最重要的子类,它根据指定的编码方式将这些字符转换成字节,并写入底层输出流。它的构造函数指定了要写入的输出流和使用的编码方式:
public OutputStreamWriter(OutputStream out, String charsetName)throws UnsupportedEncodingException
如果没有指定编码方式,就使用平台的默认编码方式。但默认字符集可能会在出乎意料的时候导致意外的问题,如果能明确指定字符集,这往往比让 Java 为你选择一个字符集要好。
3. Reader
Reader 类是 InputStream 类的映射,它是一个抽象类,主要有 3 个 read() 方法,另外还有 skip()、close()、ready()、mark()、reset() 和 markSupported() 方法:
public abstract class Reader implements Readable, Closeable {public int read() throws IOExceptionpublic int read(char cbuf[]) throws IOExceptionpublic abstract int read(char cbuf[], int off, int len) throws IOException;public long skip(long n) throws IOExceptionpublic boolean ready() throws IOExceptionpublic boolean markSupported()public void mark(int readAheadLimit) throws IOExceptionpublic void reset() throws IOExceptionpublic abstract void close() throws IOException;......}
其中 read(char cbuf[], int off, int len) 是基础方法,其他两个 read() 都是根据它实现的。子类至少要重写这个方法及 close() 方法。
read() 方法将一个 Unicode 字符作为一个 int 返回,可以是 0~65535 的一个值或在流结束时返回 -1。其他两个 read() 尝试使用字符填充字符数组,并返回实际读取的字符数或在流结束时返回 -1
skip() 方法跳过 n 个字符
mark() 和 reset() 方法允许一些 Reader 重置到字符序列中做标记的位置。markSupported() 方法告知该 Reader 是否支持标记和重置
ready() 方法与 InputStream 的 available() 的用途相同,但语义不尽相同。available() 返回一个 int 表示可以无阻塞地最少读取多少字节,但 ready() 只返回一个 boolean 表示是否可以无阻塞地读取。因为有些字符编码方式对于不同字符使用不同数量的字节,因此在实际从缓冲区读取之前,很难说有多少个字符正在网络或文件系统的缓冲区中等待。
4. InputStreamReader
InputStreamReader 是 Reader 最重要的子类,它从底层输入流中读取字节,并根据指定的编码方式将这些字节转换成字符,并返回这些字符。它的构造函数指定了要读取的输入流和使用的编码方式:
public InputStreamReader(InputStream in, String charsetName) throws UnsupportedEncodingException
读取字符串示例:
Reader in = new InputStreamReader(inputStream, "UTF-8");for (int numRead; (numRead = in.read(buffer, 0, buffer.length)) > 0; ) {out.append(buffer, 0, numRead);}String myString = out.toString();
5. BufferedReader、BufferedWriter
BufferedReader 和 BufferedWriter 是基于字符的缓冲区流,相应的,BufferedReader 和 BufferedWriter 也使用一个内部字符数组作为缓冲区。
当程序从 BufferedReader 读取时,文本会从缓冲区得到,而不是直接从底层输入流或其他文本源读取。当缓冲区清空时,将用尽可能多的文本再次填充,尽管这些文本不是全部都立即需要,这样可以使以后的读取速度更快。当程序写入一个 BufferedWriter 时,文本被放置在缓冲区中,只有当缓冲区满或者显示刷新时,文本才会被移到底层输出流或其他目标,这使得写入也要快很多。
此外,BufferedReader 中还有一个 readLine() 方法,它读取一行文本,并作为一个字符串返回;在 Java 8 中还增加了一个 lines() 方法用于返回字符流:
public String readLine() throws IOExceptionpublic Stream<String> lines()
在 BufferedWriter 中也增加了一个新的 newLine() 方法,用于向输出流插入一个与平台有关的行分隔字符串
public void newLine() throws IOException
读取字符串示例:
String newLine = System.getProperty("line.separator");BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));StringBuilder result = new StringBuilder();for (String line; (line = reader.readLine()) != null; ) {if (result.length() > 0) {result.append(newLine);}result.append(line);}String myString = result.toString();

若有收获,就点个赞吧
0 人点赞
