在 Java 的 NIO 模型中,不再向输出流写入数据和从输入流读取数据,而是要从缓冲区中读写数据,数据的读写操作始终是与缓冲区相关联的。
从编程角度看,流和通道之间的关键区别在于流是基于字节的,而通道是基于块的。流设计为按顺序一个字节接一个字节地传送数据,虽然出于性能考虑可以传送字节数组,但基本概念都是一次传送一个字节的数据。与之不同,通道会传送缓冲区中的数据块,在可以读写通道(Channel)的字节之前,这些字节必须已经存储在缓冲区(Buffer)中了,而且一次会读、写一个缓冲区的数据。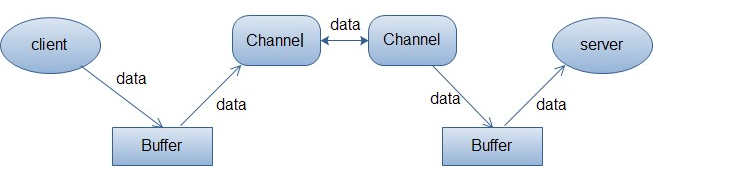
Buffer 定义
Buffer 抽象代表了一个有限容量的 Java 基本数据类型的容器——其本质是一个数组,并由指针指示了在哪存放数据和从哪读取数据。所有的缓冲区实现都是 Buffer 抽象类的子类,具体如下图所示:
缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存。因此在 Buffer 父类中记录了指向其元素列表信息的 4 个关键部分,并提供了公共的父类方法来获取和设置这些值: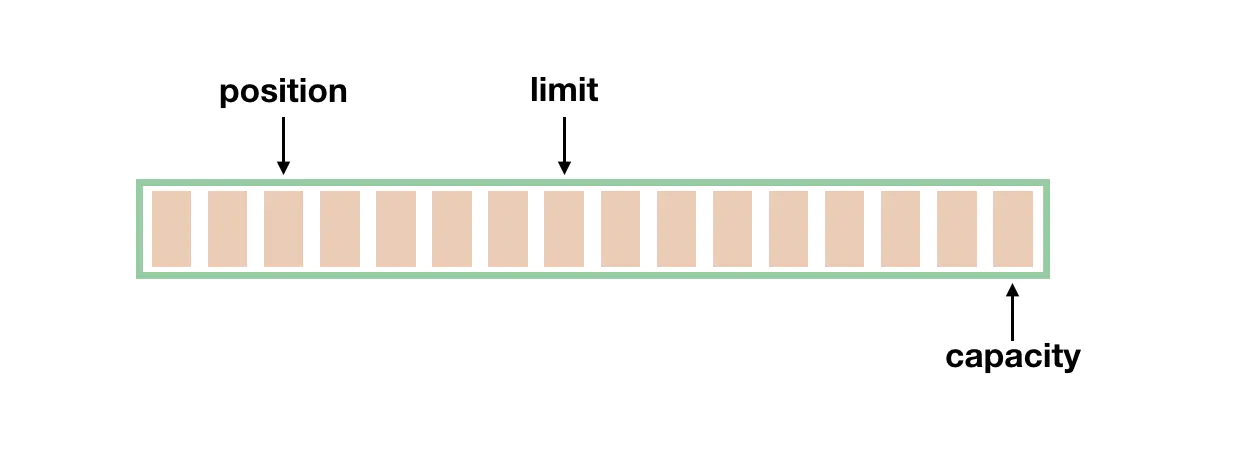
位置(position)
缓冲区中将要读取或写入的下一个位置,这个位置的值从 0 开始计算,当向 Buffer 写入或读取数据后,position 会向前移动到下一个可写入或可读取数据的 Buffer 单元,最大值等于缓冲区的大小。当将 Buffer 从写模式切换到读模式(调用 flip() 方法)时,position 会被重置为 0。
可以用下面两个方法获取和设置:
public final int position()public final Buffer position(int newPosition)
容量(capacity)
缓冲区可以保存的元素的最大数目,该值在创建缓冲区时设置,一旦设置后就不可以更改。一旦 Buffer 的容量达到 capacity 时需要先清空 Buffer 才能重新写入数据。可以用以下方法读取:
public final int capacity()
限度(limit)
缓冲区中可访问数据的末尾位置。只要不改变 limit 就无法读、写超过这个位置的数据,即使缓冲区有更大的容量也没有用。
在写模式下,Buffer 的 limit 表示你最多能往 Buffer 里写多少数据,通常该值等于 capacity。当切换 Buffer 到读模式时,limit 表示你最多能读到多少数据。此时 limit 会被设置成写模式下的 position 值。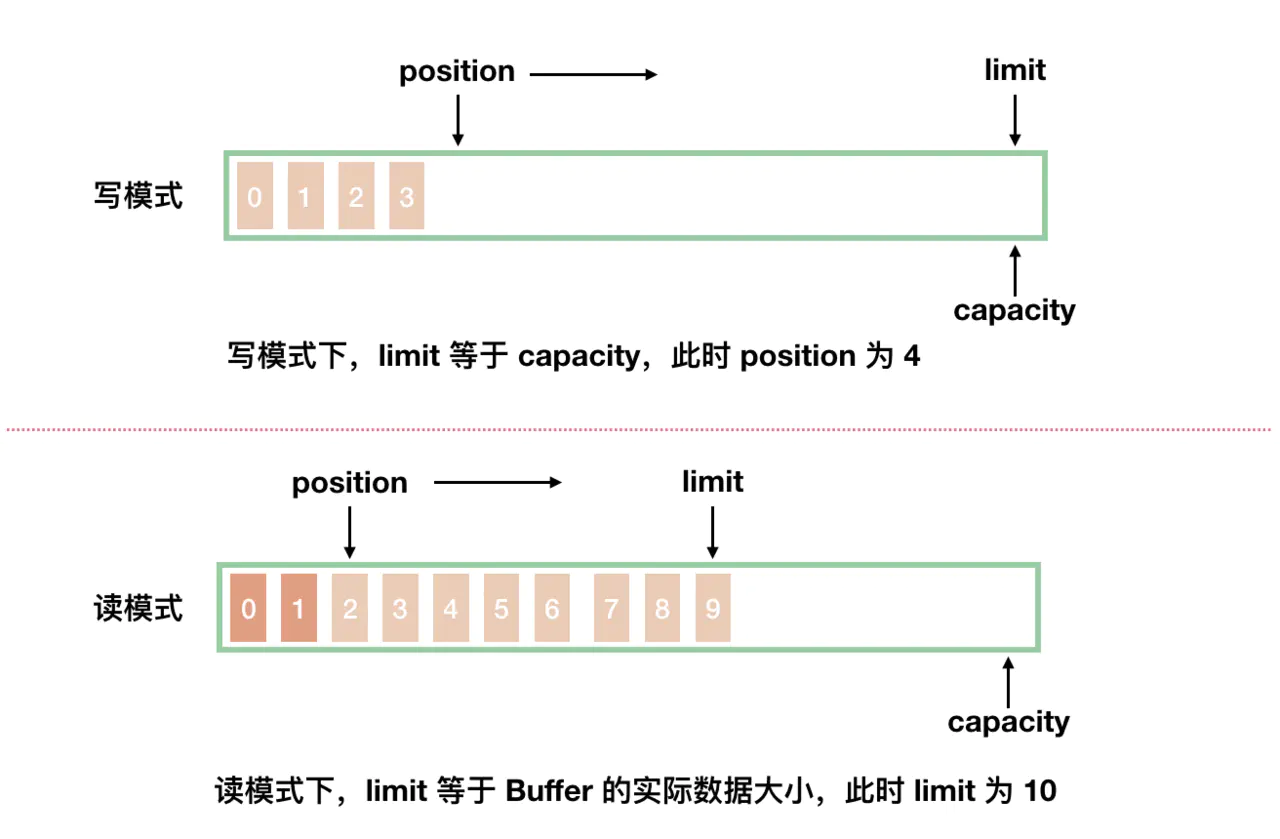
该值可通过下面两个方法获取和设置:
public final int limit()public final Buffer limit(int newLimit)
标记(mark)
该值为缓冲区中客户端指定的索引,客户端可以通过 mark() 方法将标记设置为当前位置,随后可以通过 reset() 方法将当前位置设置为所标记的位置。
public final Buffer mark()public final Buffer reset()
其他公共方法:
public final Buffer clear()public final Buffer rewind()public final Buffer flip()public final int remaining()public final boolean hasRemaining()
clear() 方法将 position 设为 0 并将 limit 设置为 capacity,从而将缓冲区清空。这样就可以完全重新填充缓冲区了。不过,该方法并没有直接删除缓冲区中的数据,这些数据仍然存在,必要时可以使用绝对的 get 方法或改变 position 和 limit 的位置进行重新读取。
rewind() 方法只是将 position 设为 0,并没有改变 limit 的值,这允许我们重新读取该缓冲区。flip() 方法将 position 设为 0 并将 limit 设为当前的 position 值,用于将写模式切换到读模式。remaining() 方法返回缓冲区中当前 position 与 limit 之间的元素数,表示是否有元素还未被读取。如果剩余元素大于 0 则 hasRemaining() 方法返回 true。
Buffer 使用
1. 创建
Buffer 实例通常不是使用构造函数创建的,每种类型的缓冲区类都有几个工厂方法,以各种方式创建这个类型的特定于实现的子类。空的缓冲区一般由分配(allocate)方法创建,预填充数据的缓冲区由包装(wrap)方法创建。allocate 通常用于输入,而 wrap 通常用于输出。
1.1 allocate
基本的 allocate() 方法只返回一个有指定固定容量的新缓冲区,这是一个空缓冲区。用 allocate() 方法创建的缓冲区基于 Java 数组实现,因此可以通过 array() 和 arrayOffset() 方法来访问。
如下示例展示了 ByteBuffer 子类中的对应方法:
public static ByteBuffer allocate(int capacity)public final byte[] array()public final int arrayOffset()
array() 实际暴露了缓冲区中的私有数据,因为它直接返回了缓冲区中的数组,所以要谨慎使用,因为修改这个数组会直接影响到缓冲区内部数据,反之亦然。通常的做法是使用数据填充缓冲区,获取该数组后进行操作,但是要保证在开始处理这个数组后就不要再写缓冲区了。
1.2 allocateDirect
ByteBuffer 类(但不包括其他缓冲区类)有另外一个 allocateDirect() 方法,这个方法在为缓冲区分配容量时不会创建 byte 数组,VM 会对该缓冲区使用直接内存访问,以此实现直接分配的 ByteBuffer,这种实现方式会尽最大努力减少中间环节的内存拷贝,把套接字的缓存数据直接拷贝到应用程序操作的内存空间里。这样就减少了内存的占用、分配、拷贝和废弃,提高了内存使用的效率及 I/O 操作的性能。
从 API 的角度看,allocateDirect() 的使用与 allocate() 完全相同。
public static ByteBuffer allocateDirect(int capacity)
在直接缓冲区上调用 array() 和 arrayOffset() 方法会抛出一个 UnsupportedOperationException 异常。因为其底层是不依赖数组的。
直接缓冲区在一些虚拟机上会更快,尤其是当缓冲区很大时。不过,分配和回收直接缓冲区的代价比间接缓冲区更高,所以只建议用在数据量比较大,存活时间比较长的情况下,比如网络连接的 I/O 操作。由于其实现细节非常依赖于 VM,除非经过测试后发现性能确实是个问题,否则不应考虑使用直接缓冲区。
1.3 warp
如果已经有了要输出的数据数组,一般可以直接用缓冲区进行包装,而不是分配一个新缓冲区,然后一次一部分地复制到这个缓冲区。
如下示例展示了 ByteBuffer 子类中的对应方法:
public static ByteBuffer wrap(byte[] array)public static ByteBuffer wrap(byte[] array, int offset, int length)
通过 wrap() 方法传入的数组入参将作为缓冲区的内部数组,修改该数组会影响到缓冲区,所以对数组操作结束前不要包装数组。并且由 wrap() 方法创建的缓冲区肯定不是直接缓冲区。
2. 数据读写
缓冲区是为顺序访问而设计的,每个缓冲区都有一个当前位置,由 position() 方法标识,从缓冲区中读取或向其写入一个元素时,缓冲区的 position 将增加一。当向缓冲区写入数据时,最多只能写入到其容量大小。如果试图填充的数据超出了初始设置的容量,继续写入则会抛出 BufferOverflowException 异常。
2.1 put
以 ByteBuffer 为例,有如下方法可以用于写入数据:
public abstract ByteBuffer put(byte b);public abstract ByteBuffer put(int index, byte b);
第二个方法中的 index 参数可以向缓冲区中的指定位置填充数据,并且该方法不会改变缓冲区中的 position 值。因此当从写模式切换到读模式时,就不需要调用 flip() 方法重置 position 值了。
除了单个字节的写入,还提供了批量写入的方法,批量写入通常要比单个字节的写入速度要快。
public final ByteBuffer put(byte[] src)public ByteBuffer put(ByteBuffer src)public ByteBuffer put(byte[] src, int offset, int length)
这些 put() 方法从当前位置(position)开始插入指定数组或子数组的数据,并且会使 position 增加数组或子数组的长度。如果缓冲区没有足够的空间容纳这个数组或子数组的,则抛出 BufferOverflowException� 异常。
2.2 get
以 ByteBuffer 为例,有如下方法可以用于读取数据:
public abstract byte get();public abstract byte get(int index);
第二个方法中的 index 参数同 put() 方法一样,可以从缓冲区中的指定位置读取数据。获取数据也提供了批量获取的方法,具体如下:
public ByteBuffer get(byte[] dst)public ByteBuffer get(byte[] dst, int offset, int length)
这些 get() 方法从当前位置(position)将数据读取到参数指定的数组或子数组中,并且会使 position 增加数组或子数组的长度。如果缓冲区没有足够的剩余数据来填充这个数组或子数组的,则抛出 BufferUnderflowException� 异常。
2.3 类型转换
Java 中的所有数据最终都解析为字节,任何适当长度的字节序列都可解释为基本类型数据。例如,任何 4 字节的序列都可以对应于一个 int 或 float;8 字节的序列对应于一个 long 或 double。
ByteBuffer 类(只有 ByteBuffer 类)提供了相对和绝对的 put 方法,可以用简单类型(boolean 除外)参数的相应字节来填充缓冲区。此外,ByteBuffer 类还提供了相对和绝对的 get 方法,可以读取适当数量的字节形成一个新的基本类型数据。
public abstract char getChar();public abstract char getChar(int index);public abstract ByteBuffer putChar(char value);public abstract ByteBuffer putChar(int index, char value);public abstract short getShort();public abstract short getShort(int index);public abstract ByteBuffer putShort(short value);public abstract ByteBuffer putShort(int index, short value);// int、long、float、double....
3. 视图缓冲区
如果你知道从 SocketChannel 读取的 ByteBuffer 只包含一种特定基本数据类型的元素,那么就有必要创建一个视图缓冲区。这是一个适当类型的新的 Buffer 对象,它从当前 position 开始由底层 ByteBuffer 提取数据。因为 SocketChannel 类只有读、写 ByteBuffer 的方法,它无法读、写任何其他类型的缓冲区,所以视图缓冲区在某些情况下也是很有用的。
修改视图缓冲区会反映到底层缓冲区,反之亦然。不过,每个缓冲区还是有自己独立的 position、limit、capacity、mark 值。视图缓冲区可以用 ByteBuffer 的以下 6 个方法来创建:
public abstract CharBuffer asCharBuffer();public abstract ShortBuffer asShortBuffer();public abstract IntBuffer asIntBuffer();public abstract LongBuffer asLongBuffer();public abstract FloatBuffer asFloatBuffer();public abstract DoubleBuffer asDoubleBuffer();
在非阻塞模式下,我们不能保证缓冲区在读取后仍能以 int、double 或 char 等类型的边界对其,因此向非阻塞通道中写入一个 int 或 double 的半个字节是完全有可能的。所以在使用非阻塞 I/O 时,在向视图缓冲区放入更多数据前,要确保检查这个问题。
4. 压缩
大多数可写缓冲区都支持 compact() 方法:
public abstract ByteBuffer compact();public abstract IntBuffer compact();public abstract ShortBuffer compact();public abstract FloatBuffer compact();public abstract CharBuffer compact();public abstract DoubleBuffer compact();
如果 Buffer 中仍有未读的数据且后续还需要这些数据,但是此时想要先写些数据,则可以使用 compact() 方法。该方法将所有未读的数据拷贝到 Buffer 起始处,然后将 position 设到最后一个未读元素的后面,limit 属性依然像 clear() 方法一样设置成 capacity。现在 Buffer 准备好写数据了,但是不会覆盖未读的数据。
当使用非阻塞 I/O 进行复制时(读取一个通道,再把数据写入另一个通道)这是一个特别有用的操作。可以将一些数据读入缓冲区,再写出缓冲区,然后压缩数据,这样所有没有写出的数据就在缓冲区开头,position 则在缓冲区中剩余数据的末尾,准备接收更多数据。这样只利用一个缓冲区就能完成比较随机的交替读、写操作。
5. 复制
通常我们需要建立缓冲区的副本,从而将相同的信息分发到两个或多个通道,6 种特定类型的缓冲区都提供了 duplicate() 方法来完成这项工作:
public abstract ByteBuffer duplicate();public abstract IntBuffer duplicate();public abstract ShortBuffer duplicate();public abstract FloatBuffer duplicate();public abstract CharBuffer duplicate();public abstract DoubleBuffer duplicate();
返回值并不是克隆,复制的缓冲区共享相同的数据,修改一个缓冲区中的数据会反映到另一个缓冲区中。所以这个方法主要用在只准备读取缓冲区时。
尽管共享相同的数据,但初始和复制的缓冲区有自己独立的 position、limit 和 mark 值。如果希望通过多个通道并行地传输相同的数据时,该方法非常有用,可以为每个通道建立主缓冲区的副本,让每个通道以其自己的速度运行。
6. 分片
分片(slicing)缓冲区是复制的一个变形。分片也会创建一个新缓冲区,与原缓冲区共享数据。不过,分片的起始位置是原缓冲区的当前 position 值,而且其容量最大不超过原缓冲区的 limit 值。也就是说,分片是原缓冲区的一个子序列,只包含从当前 position 到 limit 的所有元素。
同样的,6 种特定类型的缓冲区都有单独的 slice() 方法:
public abstract ByteBuffer slice();public abstract IntBuffer slice();public abstract ShortBuffer slice();public abstract FloatBuffer slice();public abstract CharBuffer slice();public abstract DoubleBuffer slice();
如果你有一个很长的数据缓冲区,并且能够很容易地分为多个部分(如协议首部以及数据),此时该方法就很有用。可以先读出协议首部,然后对缓冲区进行分片,将只包含数据的新缓冲区传递给一个单独的方法处理。
Charset
字符是由字节序列进行编码而成的,而且在字节序列与字符集合之间有各种映射方式(称为字符集)。NIO 缓冲区的另一个用途是在各种字符集之间进行转换。
Charset 类提供了如下编码与解码的方法:
// 创建指定编码类型的Charset对象public static Charset forName(String charsetName)// 编码public final ByteBuffer encode(String str)public final ByteBuffer encode(CharBuffer cb)// 解码public final CharBuffer decode(ByteBuffer bb)

若有收获,就点个赞吧
0 人点赞
