反射是 Java 语言中一个相当重要的特性,它允许正在运行的 Java 程序观测,甚至是修改程序的动态行为。我们可以通过 Class 对象枚举该类中的所有方法,还可以通过 Method.setAccessible() 绕过 Java 语言的访问权限,在私有方法所在类之外的地方调用该方法。
反射调用的实现
首先,我们来看看方法的反射调用,也就是 Method.invoke 是怎么实现的。
public final class Method extends Executable {...public Object invoke(Object obj, Object... args) throws ... {// 权限检查MethodAccessor ma = methodAccessor;if (ma == null) {ma = acquireMethodAccessor();}return ma.invoke(obj, args);}}
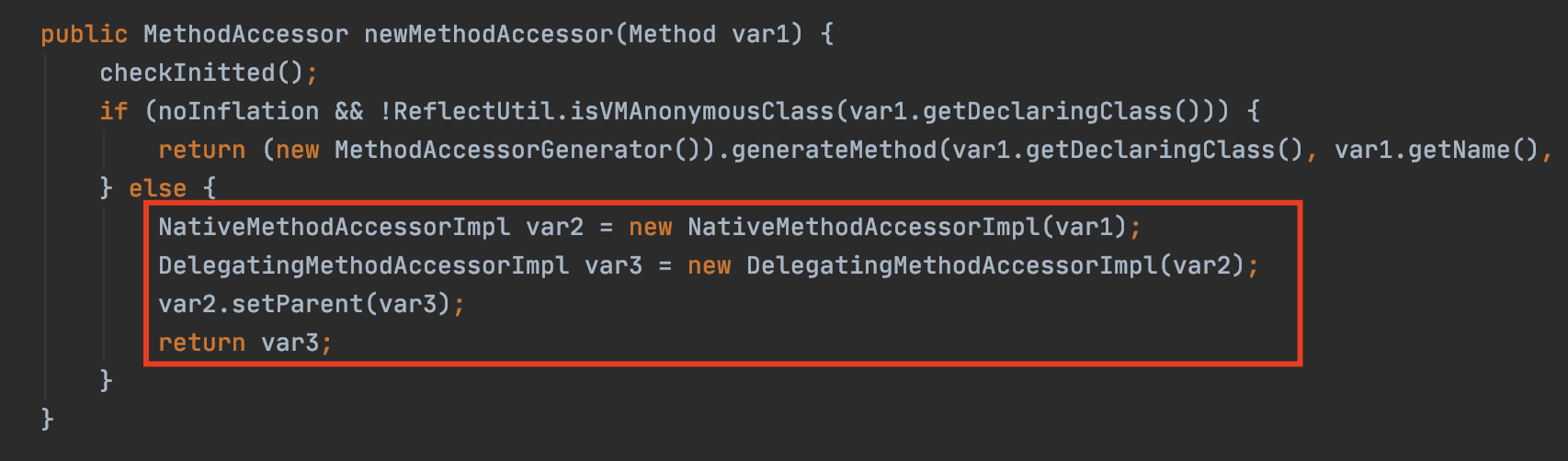
从源码中可以发现,它实际上委派给 MethodAccessor 来处理。MethodAccessor 是一个接口,它有两个已有的具体实现:一个通过本地方法来实现反射调用,另一个则使用了委派模式。每个 Method 实例的第一次反射调用都会生成一个委派实现,它所委派的具体实现便是一个本地实现。
private MethodAccessor acquireMethodAccessor() {MethodAccessor tmp = null;if (root != null) tmp = root.getMethodAccessor();if (tmp != null) {methodAccessor = tmp;} else {tmp = reflectionFactory.newMethodAccessor(this);setMethodAccessor(tmp);}return tmp;}
本地实现非常容易理解。当进入了 Java 虚拟机内部之后,我们便拥有了 Method 实例所指向方法的具体地址。此时反射调用无非就是将传入的参数准备好,然后调用进入目标方法。
1. 本地方法实现
为了方便理解,我们可以打印一下反射调用到目标方法时的栈轨迹。在下面的示例代码中,我们获取了一个指向 Test.target 方法的 Method 对象并用它来进行反射调用。
import java.lang.reflect.Method;public class Test {public static void target(int i) {new Exception("#" + i).printStackTrace();}public static void main(String[] args) throws Exception {Class<?> klass = Class.forName("Test");Method method = klass.getMethod("target", int.class);method.invoke(null, 0);}}
输出结果:
可以看到,反射调用先是调用了 Method.invoke,然后进入委派实现(DelegatingMethodAccessorImpl),再然后进入本地实现(NativeMethodAccessorImpl),最后到达目标方法。那为什么反射调用要采取委派实现作为中间层呢?直接交给本地实现不可以么?
那是因为 Java 的反射调用机制还设立了另一种动态生成字节码的实现,直接使用 invoke 相关的字节码指令来调用目标方法。使用委派实现便是为了能够在本地实现以及动态实现中进行切换。
动态实现和本地实现相比,其运行效率要快上 20 倍。因为动态实现无需经过 Java 到 C++ 再到 Java 的切换(本地实现中又调用了 Java 代码),但由于生成字节码十分耗时,仅调用一次的话,反而是本地实现要快上 3 到 4 倍。
考虑到许多反射调用仅会执行一次,Java 虚拟机设置了一个阈值 15(可以通过 -Dsun.reflect.inflationThreshold 来调整),当某个反射调用的调用次数在 15 之下时,采用本地实现;当达到 15 时,便开始动态生成字节码并将委派实现的委派对象切换至动态实现,这个过程我们称之为 Inflation。
2. 动态字节码实现
为了观察 Inflation 过程,我们将刚才的例子更改为下面的版本。它会将反射调用循环 20 次。
/** 使用 -verbose:class 参数来打印加载的类*/import java.lang.reflect.Method;public class Test {public static void target(int i) {new Exception("#" + i).printStackTrace();}public static void main(String[] args) throws Exception {Class<?> klass = Class.forName("Test");Method method = klass.getMethod("target", int.class);for (int i = 0; i < 20; i++) {method.invoke(null, i);}}}
输出结果: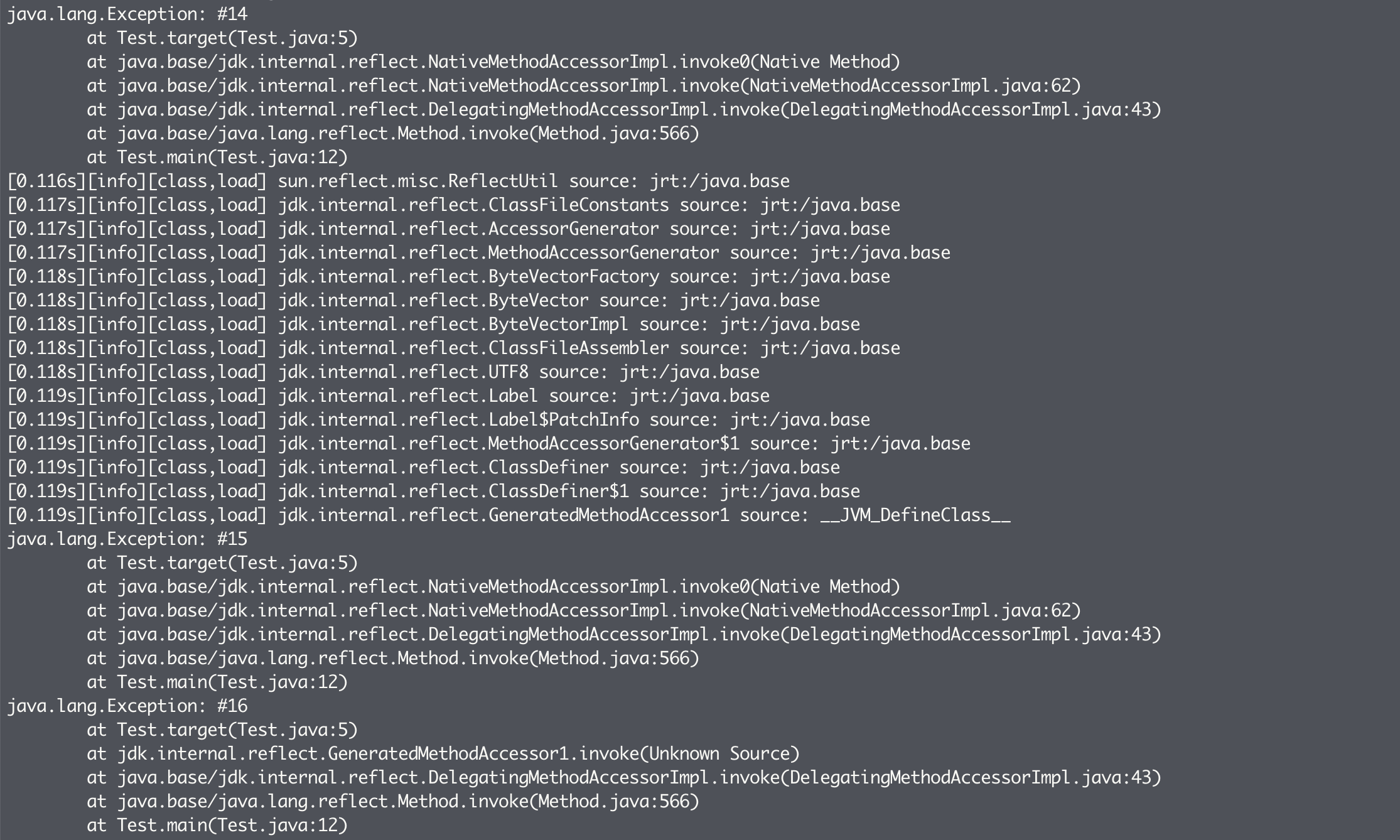
可以看到,在第 15 次(从 0 开始数)反射调用时,我们便触发了动态实现的生成。这时候,Java 虚拟机额外加载了不少类。其中最重要的当属 GeneratedMethodAccessor1。并且,从第 16 次反射调用开始,我们便切换至这个刚刚生成的动态实现了。
反射调用的 Inflation 机制是可以通过参数 -Dsun.reflect.noInflation=true 来关闭的。这样一来,在反射调用一开始便会直接生成动态实现,而不会使用委派实现或者本地实现。
反射调用的开销
在上面的示例代码中,我们先后进行了 Class.forName,Class.getMethod 以及 Method.invoke 三个操作。其中 Class.forName 会调用本地方法,Class.getMethod 则会遍历该类的公有方法。如果没有匹配到,它还将遍历父类的公有方法。可想而知,这两个操作都非常费时。
值得注意的是,以 getMethod 为代表的查找方法操作,会返回查找结果的一份拷贝。因此,我们应当避免在热点代码中使用 Class 实例的 getMethods 或者 getDeclaredMethods 方法,以减少不必要的堆空间消耗。
1. 性能测试
在实践中,我们往往会在应用程序中缓存 Class.forName 和 Class.getMethod 的结果。因此我们就只关注反射调用本身的性能开销。为了比较直接调用和反射调用的性能差距,我们将反射调用循环二十亿次,另外记录下每跑一亿次的时间。然后取最后五个记录的平均值,作为预热后的峰值性能。
直接调用:
public class Test {public static void target(int i) {}public static void main(String[] args) throws Exception {long current = System.currentTimeMillis();for (int i = 1; i <= 2_000_000_000; i++) {if (i % 100_000_000 == 0) {long temp = System.currentTimeMillis();System.out.println(temp - current);current = temp;}target(128);}}}
经测试,一亿次直接调用耗费的时间大约在 95ms,这和不调用 target 方法所耗费的时间是一致的。因为这段代码属于热循环,会触发即时编译。即时编译把 main 方法对 target 方法的调用内联进来从而消除了调用的开销。下面我们就以 95ms 作为基准值,来比较反射调用的性能开销。
反射调用:
public class Test {public static void target(int i) {}public static void main(String[] args) throws Exception {Class<?> klass = Class.forName("Test");Method method = klass.getMethod("target", int.class);long current = System.currentTimeMillis();for (int i = 1; i <= 2_000_000_000; i++) {if (i % 100_000_000 == 0) {long temp = System.currentTimeMillis();System.out.println(temp - current);current = temp;}method.invoke(null, 128);}}}
一亿次反射调用所耗费的时间大约在 240ms,是基准值的 2.5 倍。我们来看下在反射调用前的字节码:
这里截取了循环中反射调用编译而成的字节码。可以看到,这段字节码除反射调用外还额外做了两个操作:
第一,由于 Method.invoke 是一个变长参数方法,在字节码层面它的最后一个参数是 Object 数组。因此 Javac 编译器会在方法调用处生成一个长度为传入参数数量的 Object 数组,并将传入参数一一存储进该数组中。
第二,由于 Object 数组不能存储基本类型,Javac 编译器会对传入的基本类型参数进行自动装箱。
这两个操作除了带来性能开销外,还可能占用堆内存,使得 GC 更加频繁。那如何能消除这部分开销呢?
关于第二个自动装箱,Java 缓存了 [-128, 127] 中所有整数所对应的 Integer 对象。当需要自动装箱的整数在这个范围之内时,便返回缓存的 Integer,否则需要新建一个 Integer 对象。因此,我们可以将这个缓存的范围扩大至覆盖 128,可以通过参数 -Djava.lang.Integer.IntegerCache.high=128 设置,也可以在循环外缓存 128 自动装箱得到的 Integer 对象并直接传入反射调用中。
通过这两种方法测得的结果差不多,一亿次反射调用耗费的时间大约在 180ms,约为基准值的 1.9 倍。我们再看第一个因变长参数而自动生成的 Object 数组。既然每个反射调用对应的参数个数是固定的,那我们是否可以在循环外新建一个 Object 数组,设置好参数直接交给反射调用呢?
public class Test {public static void target(int i) {}public static void main(String[] args) throws Exception {Class<?> klass = Class.forName("Test");Method method = klass.getMethod("target", int.class);Object[] arg = new Object[1]; // 在循环外构造参数数组arg[0] = 128;long current = System.currentTimeMillis();for (int i = 1; i <= 2_000_000_000; i++) {if (i % 100_000_000 == 0) {long temp = System.currentTimeMillis();System.out.println(temp - current);current = temp;}method.invoke(null, arg);}}}
通过测试发现,性能并没有提升,仍为基准值的 2.5 倍,这是为什么呢?
如果在解决了自动装箱后查看运行时的 GC 状况,会发现这段程序并不会触发 GC。因为原本的反射调用被内联了,从而使得即时编译器中的逃逸分析将原本新建的 Object 数组判定为不逃逸的对象。如果一个对象不逃逸,则即时编译器可以选择栈分配甚至虚拟分配,不会占用堆空间。如果在循环外新建数组,即时编译器无法确定这个数组会不会中途被更改,因此无法优化掉访问数组的操作,可谓得不偿失。
为什么自动装箱后,反射调用被内联了?
实际上,我们还可以关闭反射调用的 Inflation 机制,从而取消委派实现并直接使用动态实现。此外,每次反射调用都会检查目标方法的权限,而这个检查可以在 Java 代码里关闭,在关闭了这两项机制后,一亿次反射调用耗费的时间大约在 120ms,约为基准值的 1.3 倍。
// 添加启动参数 -Dsun.reflect.noInflation=truepublic class Test {public static void target(int i) {}public static void main(String[] args) throws Exception {Class<?> klass = Class.forName("Test");Method method = klass.getMethod("target", int.class);method.setAccessible(true);long current = System.currentTimeMillis();for (int i = 1; i <= 2_000_000_000; i++) {if (i % 100_000_000 == 0) {long temp = System.currentTimeMillis();System.out.println(temp - current);current = temp;}method.invoke(null, 127);}}}
2. 方法内联瓶颈
在上面的代码示例中,之所以反射调用能够变得这么快,主要是因为即时编译器中的方法内联。虽然 Method.invoke 方法一直会被内联,但是它里面的 MethodAccesor.invoke 方法则不一定。
在关闭了 Inflation 的情况下,内联的瓶颈在于 Method.invoke 中对 MethodAccessor.invoke 的调用。因为关闭 inflation 后默认使用的是动态实现,在生产环境中,我们又往往拥有多个不同的反射调用,这对应了多个 GeneratedMethodAccessor,也就是动态实现。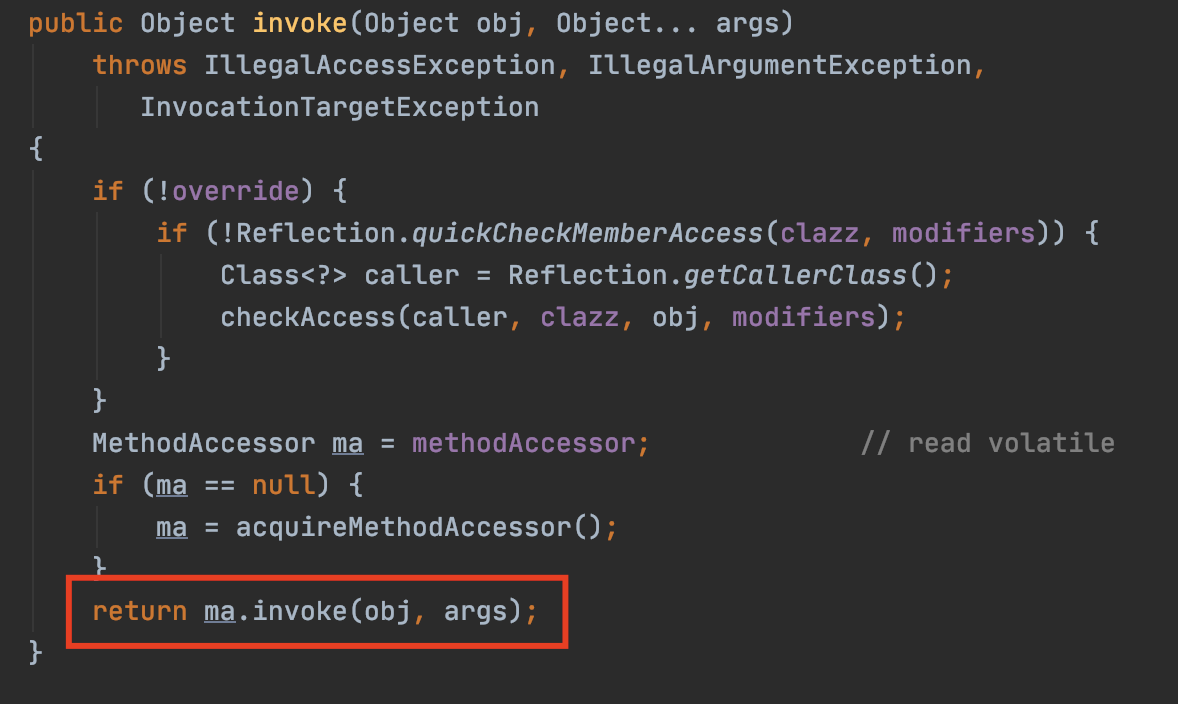
由于 Java 虚拟机的关于上述调用点的类型 profile(对于 invokevirtual 或者 invokeinterface,Java 虚拟机会记录下调用者的具体类型,我们称之为类型 profile)无法同时记录这么多个类,因此可能造成所测试的反射调用没有被内联的情况。
代码示例:
public class Test {public static void target(int i) {}public static void target1(int i) {}public static void target2(int i) {}public static void main(String[] args) throws Exception {Class<?> klass = Class.forName("Test");Method method = klass.getMethod("target", int.class);method.setAccessible(true); // 关闭权限检查polluteProfile();long current = System.currentTimeMillis();for (int i = 1; i <= 2_000_000_000; i++) {if (i % 100_000_000 == 0) {long temp = System.currentTimeMillis();System.out.println(temp - current);current = temp;}method.invoke(null, 127);}}public static void polluteProfile() throws Exception {Method method1 = Test.class.getMethod("target1", int.class);Method method2 = Test.class.getMethod("target2", int.class);for (int i = 0; i < 2000; i++) {method1.invoke(null, 0);method2.invoke(null, 0);}}}
在代码示例中,我们在测试循环之前调用了 polluteProfile 方法。该方法将反射调用 Test 类的另外两个方法,并且循环上 2000 遍。经测试,一亿次反射调用耗费的时间大约在 700ms,约为基准值的 7.3 倍。
这是因为我们在循环调用前,用 method1 和 method2 干扰了 Method.invoke 方法的类型 profile。Java 虚拟机关于每个调用能够记录的类型数目,默认为 2,可通过 -XX:TypeProfileWidth 参数进行设置。而我们在循环调用前,正好执行了两个不同的方法,导致执行 target 方法时无法进行内联。如果我们在 polluteProfile 方法中注释掉对 method1 的反射调用,则 target 方法就可以被内联了。
方法的反射调用会带来不少性能开销,原因主要有三个:变长参数方法导致的 Object 数组,基本类型的自动装箱、拆箱,还有最重要的方法内联。
反射 API 简介
通常来说,使用反射 API 的第一步便是获取 Class 对象。在 Java 中常见的有这么三种:
使用静态方法 Class.forName 来获取。
调用对象的 getClass() 方法。
直接用类名 +“.class”访问。对于基本类型来说,它们的包装类型拥有一个名为“TYPE”的 final 静态字段指向该基本类型对应的 Class 对象。例如,Integer.TYPE 指向 int.class。
一旦得到了 Class 对象,我们便可以正式地使用反射功能了。下面列举了较为常用的几项:
- 使用 newInstance() 来生成一个该类的实例。它要求该类中拥有一个无参数的构造器。
- 使用 isInstance(Object) 来判断一个对象是否是该类的实例,语法上等同于 instanceof 关键字
- 使用 Array.newInstance(Class,int) 来构造该类型的数组。
- 使用 getFields()/getConstructors()/getMethods() 来访问该类的成员。除了这三个之外,Class 类还提供了许多【其他方法】。需要注意的是,方法名中带 Declared 的不会返回父类的成员,但是会返回私有成员;而不带 Declared 的则相反。
当获得了类成员之后,我们可以进一步做如下操作:
- 使用 Constructor/Field/Method.setAccessible(true) 来绕开 Java 语言的访问限制。
- 使用 Constructor.newInstance(Object[]) 来生成该类的实例。
- 使用 Field.get/set(Object) 来访问字段的值。
- 使用 Method.invoke(Object, Object[]) 来调用方法。

若有收获,就点个赞吧
0 人点赞
