RCNN
使用基于滑窗的Selective Search算法生成候选框,然后使用神经网络进行分类。
首先时间回到了2014年,在2014年,正是深度学习如火如荼的发展的第三年。在CVPR 2014年中Ross Girshick提出的R-CNN中,使用到了卷积神经网络来进行目标检测。下面笔者就来概述一下R-CNN是如何采用卷积神经网络进行目标检测的工作。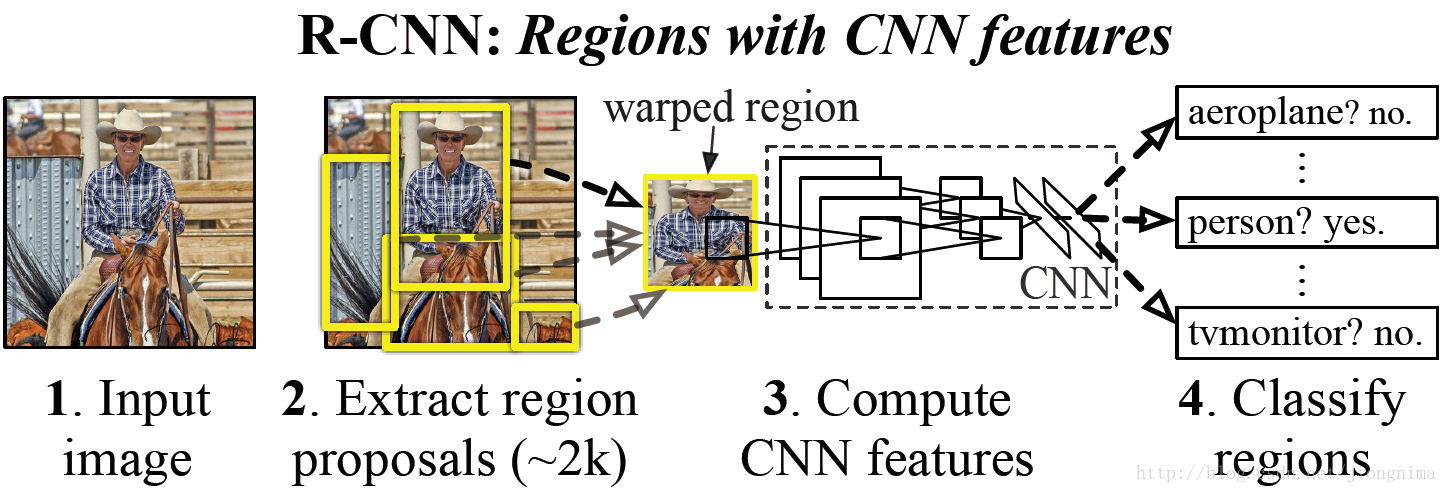
首先模型输入为一张图片,然后在图片上提出了约2000个待检测区域,然后这2000个待检测区域一个一个地(串联方式)通过卷积神经网络提取特征,然后这些被提取的特征通过一个支持向量机(SVM)进行分类,得到物体的类别,并通过一个bounding box regression调整目标包围框的大小。下面,笔者简要概述一下R-CNN是怎么实现以上步骤的。
首先在第一步提取2000个待检测区域的时候,是通过一个2012年提出的方法,叫做selective search。简单来说就是通过一些传统图像处理方法将图像分成若干块,然后通过一个SVM将属于同一目标的若干块拿出来。selective search的核心是一个SVM,架构如下所示:
RCNN的贡献
1) 使用了卷积神经网络进行特征提取。
2) 使用bounding box regression进行目标包围框的修正。
RCNN的局限性
1) 耗时的selective search,对一帧图像,需要花费2s。
2) 耗时的串行式CNN前向传播,对于每一个RoI,都需要经过一个AlexNet提特征,为所有的RoI提特征大约花费47s。
3) 三个模块是分别训练的,并且在训练的时候,对于存储空间的消耗很大。
Fast RCNN
面对RCNN的缺陷,Ross在2015年提出的Fast R-CNN进行了改进,下面我们来概述一下Fast R-CNN的解决方案:
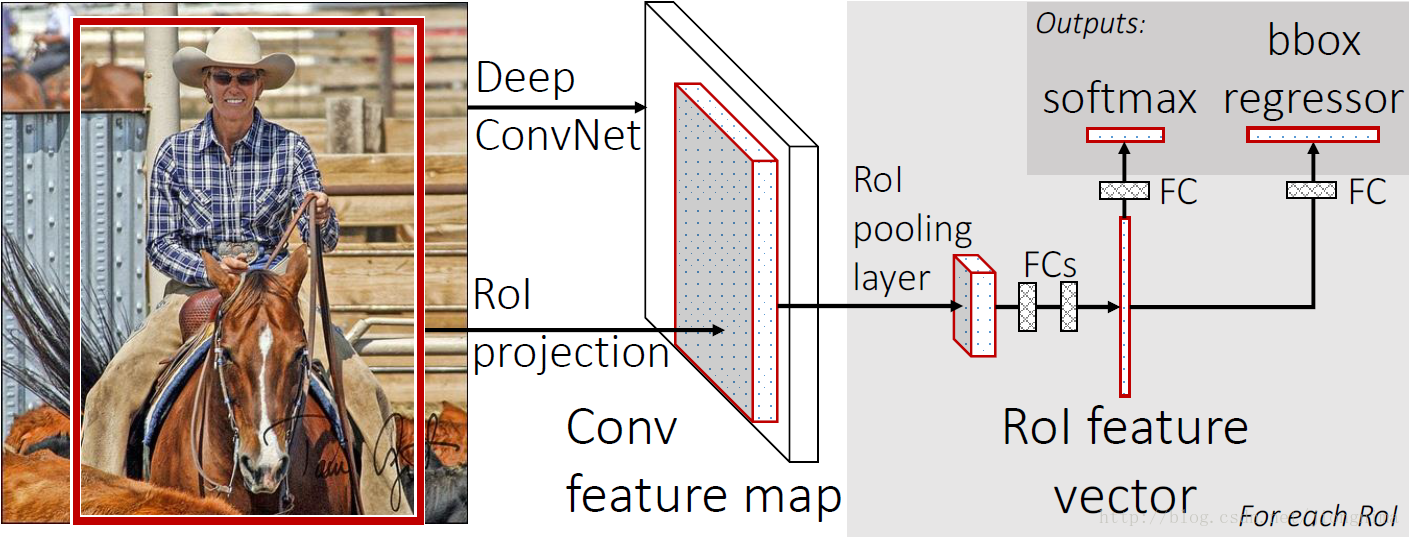
首先还是采用selective search提取2000个候选框,然后,使用一个神经网络对全图进行特征提取。接着,使用一个RoI Pooling Layer在全图特征上摘取每一个RoI对应的特征,再通过全连接层(FC Layer)进行分类与包围框的修正。Fast R-CNN的贡献可以主要分为两个方面:
1) 取代R-CNN的串行特征提取方式,直接采用一个神经网络对全图提取特征(这也是为什么需要RoI Pooling的原因)。
2) 除了selective search,其他部分都可以合在一起训练。
耗时的selective search还是依旧存在(不能使用cpu加速)
Faster RCNN
取代selective search,直接通过一个Region Proposal Network (RPN)生成待检测区域,这么做,在生成RoI区域的时候,时间也就从2s缩减到了10ms。我们来看一下Faster R-CNN是怎么做的。
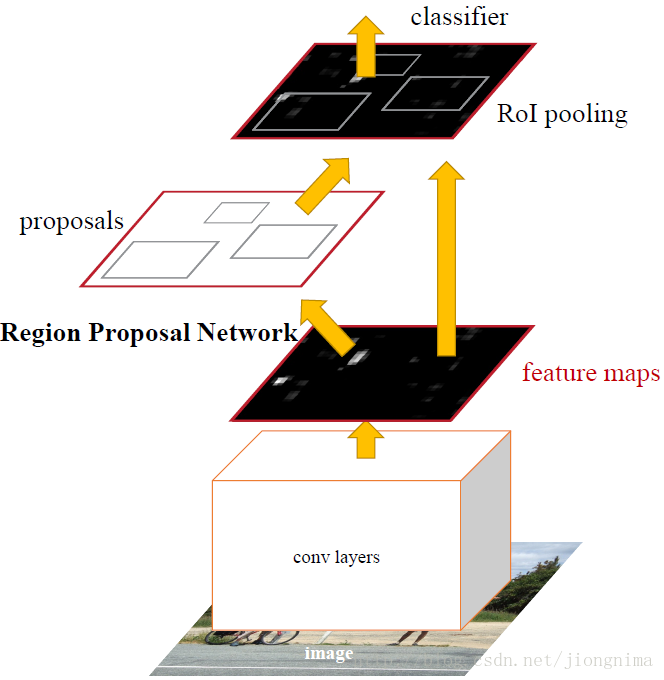
首先使用共享的卷积层为全图提取特征,然后将得到的Feature Maps送入RPN,RPN生成待检测框(指定RoI的位置)并对RoI的包围框进行第一次修正。之后就是Fast R-CNN的架构了,RoI Pooling Layer根据RPN的输出在feature map上面选取每个RoI对应的特征,并将维度置为定值。最后,使用全连接层(FC Layer)对框进行分类,并且进行目标包围框的第二次修正。尤其注意的是,Faster R-CNN真正实现了端到端的训练(end-to-end training)。
参考
CSDN 实例分割模型Mask R-CNN详解:从R-CNN,Fast R-CNN,Faster R-CNN再到Mask R-CNN

若有收获,就点个赞吧
0 人点赞
