0 前言
在轻松掌握 MMDetection 中常用算法(一):RetinaNet 及配置详解一文中,对经典 one-stage 目标检测算法 RetinaNet 以及相关配置参数进行了详细说明,本文解读经典 two-stage 算法 Faster R-CNN 以及改进版 Mask R-CNN。需要特别注意的是:如果涉及到和 RetinaNet 相同的配置,本文不再进一步描述,读者请查看 RetinaNet 一文解读。
1 Faster R-CNN 和 Mask R-CNN 简介
Faster R-CNN (Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks) 是目标检测领域最为经典的方法之一,通过 RPN(Region Proposal Networks) 区域提取网络和 R-CNN 网络联合训练实现高效目标检测。其简要发展历程为:
- R-CNN。首先通过传统的 selective search 算法在图片上预取 2000 个左右 Region Proposal;接着将这些 Region Proposal 通过前处理统一尺寸输入到 CNN 中进行特征提取;然后把所提取的特征输入到 SVM 支持向量机中进行分类;最后对分类后的 Region Proposal 进行 bbox 回归。此时算法的整个过程较为繁琐,速度也较慢。
- Fast R-CNN。首先通过传统的 selective search 算法在图片上预取 2000 个左右 Region Proposal;接着对整张图片进行特征提取;然后利用 Region Proposal 坐标在 CNN 的最后一个特征图上进去 RoI 特征图提取;最后将所有 RoI 特征输入到分类和回归模块中。此时算法的整个过程相比 R-CNN 得到极大的简化,但依然无法联合训练。
- Faster R-CNN。首先通过可学习的 RPN 网络进行 Region Proposal 的预取;接着利用 Region Proposal 坐标在 CNN 的特征图上进行 RoI 特征图提取;然后利用 RoI Pooling 层进行空间池化使其所有特征图输出尺寸相同;最后将所有特征图输入到后续的 FC 层进行分类和回归。此时算法的整个过程一气呵成,实现了端到端训练。
Faster R-CNN 的出现改变了整个目标检测算法的发展历程。之所以叫做 two-stage 检测器,原因是其包括一个区域提取网络 RPN 和 RoI Refine 网络 R-CNN,同时为了将 RPN 提取的不同大小的 RoI 特征图组成 batch 输入到后面的 R-CNN 中,在两者中间还插入了一个 RoI Pooling 层,可以保证任意大小特征图输入都可以变成指定大小输出。简要结构图如下所示:
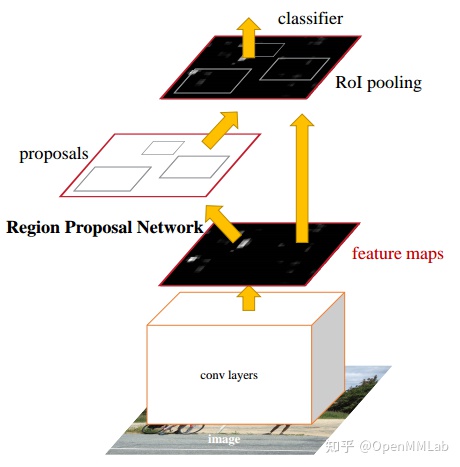
如果和 RetinaNet 进行类比的话,其过程相当于 二分类的 RetinaNet + RoI Pooling + 简单 FC 层多分类和回归网络,Faster R-CNN 也属于 Anchor-based 类算法。
Faster R-CNN 之后,考虑到多尺度预测问题,后续又提出了改进版本特征金字塔 FPN(Feature Pyramid Networks for Object Detection)。 通过分析目前目标检测中存在的图像金字塔、单层预测和多层预测问题,提出了一个简单的,通过从上到下路径和横向连接,结合高分辨率、弱语义信息的特征层和低分辨率、强语义信息的特征融合,实现类似图像金字塔效果,顶层特征通过上采样和低层特征做融合,而且每层都是独立预测的,效果显著,如下图所示:
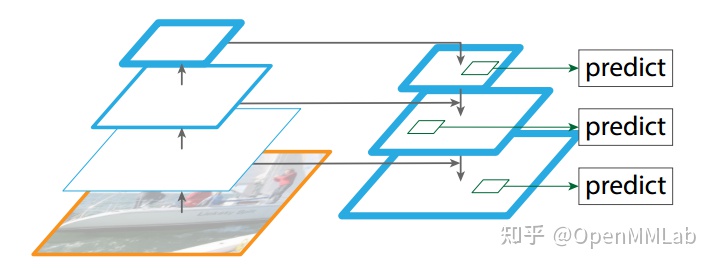
由于其强大的性能,更加模块化现代化的设计,现在提到 Faster R-CNN, 一般默认是指的 FPN 网络。本文解读的 Faster R-CNN 网络实际上也是指的 FPN。
在 FPN 提出后,Kaiming He 等进一步对其进行任务扩展,提出了 Mask R-CNN,通过新增 mask 掩码分支实现实例分割任务,其最大特点是任务扩展性强,通过新增不同分支就可以实现不同的扩展任务。例如可以将 mask 分支替换为关键点分支即可实现多人姿态估计。除此之外,为解决特征图与原始图像上的 RoI 不对准的问题,提出了 ROIAlign 模块。其简要示意图如下:
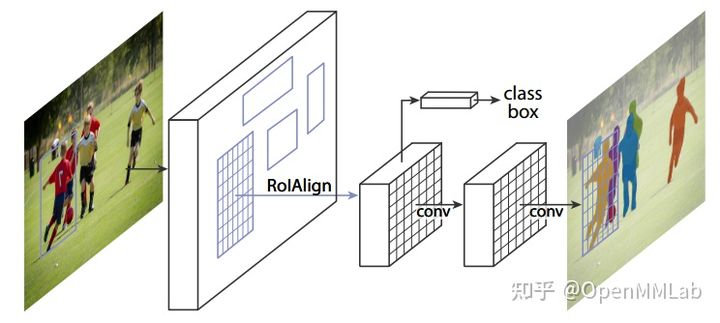
带有 FPN 的 Faster R-CNN 和 Mask R-CNN 算法是目前的主流算法,应用非常广泛。并且由于 Faster R-CNN 与 Mask R-CNN 属于同一系列,因此本文将这两个核心算法同时解读。
2 Faster R-CNN 代码详解
为方便算法与代码的解读,Faster R-CNN 模型整体流程如下所示:
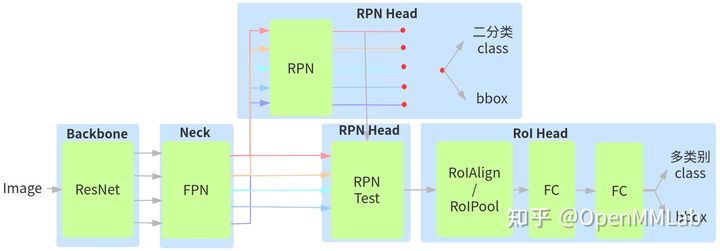
- 图片输入到 ResNet 中进行特征提取,输出 4 个特征图,按照特征图从大到小排列,分别是 C2 C3 C4 C5,stride = 4,8,16,32
- 4 个特征图输入到 FPN 模块中进行特征融合,输出 5 个通道数相同的特征图,分别是 p2 ~ p6,stride = 4,8,16,32,64
- FPN 输出的 5 个特征图,输入到同一个 RPN 或者说 5 个相同的 RPN 中,每个分支都进行前后景分类和 bbox 回归,然后就可以和 label 计算 loss
- 在 5 个 RPN 分支输出的基础上,采用 RPN test 模块输出指定个数的 Region Proposal,将 Region Proposal 按照重映射规则,在对应的 p2 ~ p5 特征图上进行特征提取,注意并没有使用 p6 层特征图,从而得到指定个数例如 2k 个 Region Proposal 特征图
- 将 2k 个不同大小的 RoI 区域特征图输入到 RoIAlign 或者 RoIPool 层中进行统一采样,得到指定输出 shape 的 2k 个特征图
- 组成 batch 输入到两层 FC 中进行多类别的分类和回归,其 loss 和 RPN 层 loss 相加进行联合训练
下面将会对每个模块进行详细的分析。值得注意的是,除了 RoI Head 模块外,其他模块在前一篇 RetinaNet 都有介绍,大家也可以作为参考,方便辅助理解。
2.1 Backbone
由于 Faster R-CNN 是后续各个算法的 baseline 且用途非常广泛,OpenMMLab 提供了非常多的模型配置供研究或者不同任务 fintune 用,几乎覆盖了所有常用配置,如下所示:
- 1x、2x 和 3x 的模型配置和权重
- 多尺度训练配置和权重
- 不同骨架的配置和权重
- PyTorch 和 Caffe style 的配置和权重
- 各种 loss 对比配置和权重
- 不包含 FPN 的 Faster R-CNN 配置和权重
- 常用类别例如 person 的配置和权重,可作为下游任务例如行人检测的预训练权重,性能极佳
以 ResNet50 为例,其配置和 RetinaNet 完全相同,此处不再描述。
# 使用 pytorch 提供的在 imagenet 上面训练过的权重作为预训练权重pretrained='torchvision://resnet50',backbone=dict(# 骨架网络类名type='ResNet',# 表示使用 ResNet50depth=50,# ResNet 系列包括 stem+ 4个 stage 输出num_stages=4,# 表示本模块输出的特征图索引,(0, 1, 2, 3),表示4个 stage 输出都需要,# 其 stride 为 (4,8,16,32),channel 为 (256, 512, 1024, 2048)out_indices=(0, 1, 2, 3),# 表示固定 stem 加上第一个 stage 的权重,不进行训练frozen_stages=1,# 所有的 BN 层的可学习参数都不需要梯度,也就不会进行参数更新norm_cfg=dict(type='BN', requires_grad=True),# backbone 所有的 BN 层的均值和方差都直接采用全局预训练值,不进行更新norm_eval=True,# 默认采用 pytorch 模式style='pytorch'),
2.2 Neck
虽然都采用了 FPN,但是 Faster R-CNN 的配置和 RetinaNet 不同,
neck=dict(type='FPN',# ResNet 模块输出的4个尺度特征图通道数in_channels=[256, 512, 1024, 2048],# FPN 输出的每个尺度输出特征图通道out_channels=256,# FPN 输出特征图个数num_outs=5),
- 将c2 c3 c4 c5 4 个特征图全部经过各自 1x1 卷积进行通道变换变成 m2~m5,输出通道统一为 256
- 从 m5 开始,先进行 2 倍最近邻上采样,然后和 m4 进行 add 操作,得到新的 m4
- 将新 m4 进行 2 倍最近邻上采样,然后和 m3 进行 add 操作,得到新的 m3
- 将新 m3 进行 2 倍最近邻上采样,然后和 m2 进行 add 操作,得到新的 m2
- 对 m5 和新的融合后的 m4 ~ m2,都进行各自的 3x3 卷积,得到 4 个尺度的最终输出 p5 ~ p2
- 将 c5 进行 3x3 且 stride=2 的卷积操作,得到 p6,目的是提供一个感受野非常大的特征图,有利于检测超大物体
故 FPN 模块实现了c2 ~ c5 4 个特征图输入,p2 ~ p6 5个特征图输出,其 strides = (4,8,16,32,64)。
2.3 RPN Head
其完整配置如下:
rpn_head=dict(type='RPNHead',# FPN 层输出特征图通道数in_channels=256,# 中间特征图通道数feat_channels=256,# 后面分析anchor_generator=dict(type='AnchorGenerator',scales=[8],ratios=[0.5, 1.0, 2.0],strides=[4, 8, 16, 32, 64]),# 后面分析bbox_coder=dict(type='DeltaXYWHBBoxCoder',target_means=[.0, .0, .0, .0],target_stds=[1.0, 1.0, 1.0, 1.0]),# 后面分析loss_cls=dict(type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
相比 RetinaNet,RPN Head 网络比较简单,就一个卷积进行特征通道变换,加上两个输出分支即可,如下所示:
def _init_layers(self):"""Initialize layers of the head."""# 特征通道变换self.rpn_conv = nn.Conv2d(self.in_channels, self.feat_channels, 3, padding=1)# 分类分支,类别固定是2,表示前后景分类# 并且由于 cls loss 是 bce,故实际上 self.cls_out_channels=1self.rpn_cls = nn.Conv2d(self.feat_channels,self.num_anchors * self.cls_out_channels, 1)# 回归分支,固定输出4个数值,表示基于 anchor 的变换值self.rpn_reg = nn.Conv2d(self.feat_channels, self.num_anchors * 4, 1)
5 个 RPN Head 共享所有分类或者回归分支的卷积权重,经过 Head 模块的前向流程输出一共是 5*2 个特征图。
2.4 BBox Assigner
RPN 这部分设计和 RetinaNet 原理完全相同,差别只在参数而已。
(1) AnchorGenerator
anchor_generator=dict(type='AnchorGenerator',# 相当于 octave_base_scale,表示每个特征图的 base scalesscales=[8],# 每个特征图有 3 个高宽比例ratios=[0.5, 1.0, 2.0],# 特征图对应的 stride,必须和特征图 stride 一致,不可以随意更改strides=[4, 8, 16, 32, 64]),
相比不包括 FPN 的 Faster R-CNN 算法,由于其 RPN Head 是多尺度特征图,为了适应这种变化,anchor 设置进行了适当修改,FPN 输出的多尺度信息可以帮助区分不同大小物体识别问题,每一层就不再需要不包括 FPN 的 Faster R-CNN 算法那么多 anchor 了。
可以看出一共 5 个输出层,每个输出层包括 3 个高宽比例和 1 种尺度,也就是说每一层的每个特征图坐标处都包括 3 个 anchor,一共 15 个 anchor,相比 RetinaNet 少了很多,其具体实现看 RetinaNet 算法解读文章。
(2) BBox Assigner
assigner=dict(# 最大 IoU 原则分配器type='MaxIoUAssigner',# 正样本阈值pos_iou_thr=0.7,# 负样本阈值neg_iou_thr=0.3,# 正样本阈值下限min_pos_iou=0.3,# 忽略 bboxes 的阈值,-1 表示不忽略ignore_iof_thr=-1),
分配准则和 RetinaNet 完全相同,除了参数不同以外。简要总结为:
- 如果 anchor 和所有 gt bbox 的最大 iou 值小于 0.3,那么该 anchor 就是背景样本
- 如果 anchor 和所有 gt bbox 的最大 iou 值大于等于 0.7,那么该 anchor 就是高质量正样本,该阈值比较高,这个阈值设置需要和后续的 R-CNN 模块匹配
- 如果 gt bbox 和所有 anchor 的最大 iou 值大于等于 0.3(可以看出可能有某些 gt bbox 没有和任意 anchor 匹配),那么该 gt bbox 所对应的 anchor 也是正样本
- 其余样本全部为忽略样本,但是由于 neg_iou_thr 和 min_pos_iou 相等,故不存在忽略样本
2.5 BBox Sampler
和 RetinaNet 采用 Focal Loss 处理正负样本不平衡不同,Faster R-CNN 是通过正负样本采样模块来克服。
sampler=dict(# 随机采样type='RandomSampler',# 采样后每张图片的训练样本总数,不包括忽略样本num=256,# 正样本比例pos_fraction=0.5,# 正负样本比例,用于确定负样本采样个数上界neg_pos_ub=-1,# 是否加入 gt 作为 proposals 以增加高质量正样本数add_gt_as_proposals=False)
核心参数的具体含义是:
- num = 256 表示采样后每张图片的样本总数,pos_fraction 表示其中的正样本比例,具体是正样本采样 128 个,那么理论上负样本采样也是 128 个
- neg_pos_ub 表示负和正样本比例上限,用于确定负样本采样个数上界,例如打算采样 1000 个样本,正样本打算采样 500 个,但是可能正样本才 200 个,那么正样本实际上只能采样 200 个,如果设置 neg_pos_ub=-1 那么就会对负样本采样 800 个,用于凑足 1000 个,但是如果设置了 neg_pos_ub 比例,例如 1.5,那么负样本最多采样 200x1.5=300 个,最终返回的样本实际上不够 1000 个,默认情况 neg_pos_ub=-1
- add_gt_as_proposals=True 是防止高质量正样本太少而加入的,可以保证前期收敛更快、更稳定,属于训练技巧,在 RPN 模块设置为 False,主要用于 R-CNN,因为前期 RPN 提供的正样本不够,可能会导致训练不稳定或者前期收敛慢的问题。
其实现过程比较简单,如下所示:
if self.add_gt_as_proposals and len(gt_bboxes) > 0:# 增加 gt 作为 proposalsbboxes = torch.cat([gt_bboxes, bboxes], dim=0)assign_result.add_gt_(gt_labels)# 计算正样本个数num_expected_pos = int(self.num * self.pos_fraction)# 正样本随机采样pos_inds = self.pos_sampler._sample_pos(assign_result, num_expected_pos, bboxes=bboxes, **kwargs)# 去重pos_inds = pos_inds.unique()# 计算负样本数num_sampled_pos = pos_inds.numel()num_expected_neg = self.num - num_sampled_posif self.neg_pos_ub >= 0:# 计算负样本个数上限_pos = max(1, num_sampled_pos)neg_upper_bound = int(self.neg_pos_ub * _pos)if num_expected_neg > neg_upper_bound:num_expected_neg = neg_upper_bound# 负样本随机采样neg_inds = self.neg_sampler._sample_neg(assign_result, num_expected_neg, bboxes=bboxes, **kwargs)# 去重neg_inds = neg_inds.unique()
而具体的随机采样函数如下所示:
# 随机采样正样本def _sample_pos(self, assign_result, num_expected, **kwargs):"""Randomly sample some positive samples."""pos_inds = torch.nonzero(assign_result.gt_inds > 0, as_tuple=False)if pos_inds.numel() != 0:pos_inds = pos_inds.squeeze(1)if pos_inds.numel() <= num_expected:return pos_indselse:return self.random_choice(pos_inds, num_expected)# 随机采样负样本def _sample_neg(self, assign_result, num_expected, **kwargs):"""Randomly sample some negative samples."""neg_inds = torch.nonzero(assign_result.gt_inds == 0, as_tuple=False)if neg_inds.numel() != 0:neg_inds = neg_inds.squeeze(1)if len(neg_inds) <= num_expected:return neg_indselse:return self.random_choice(neg_inds, num_expected)
经过随机采样函数后,可以有效控制 RPN 网络计算 loss 时正负样本平衡问题。
2.6 BBox Encoder Decoder
本部分参数和实现方式和 RetinaNet 中介绍的完全相同,请参照相关解读。
2.7 Loss
loss_cls=dict(type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
RPN 采用的 loss 是常用的 bce loss 和 l1 loss,不需要详细描述。
2.8 RPN Test
到目前为止, RPN 的整个训练流程就分析完后,但是实际上 RPN 是作为一个 RoI 提取模块,真正核心的是 R-CNN 部分,为了实现联合训练,RPN 不仅仅要自己进行训练,还要同时输出 RoI,然后利用这些 RoI 去 FPN 输出的特征图上进行截取,最后输入给 R-CNN 进行分类和回归。一个核心的问题是如何得到这些 RoI,实际上是调用了 RPN 的 test 过程。由于 RPN 也是和 RetinaNet 一样的 one-stage 算法,其大概过程和 RetinaNet 基本一致:
rpn=dict(# 是否跨层进行 NMS 操作nms_across_levels=False,# nms 前每个输出层最多保留 1000 个预测框nms_pre=1000,# nms 后每张图片最多保留 1000 个预测框nms_post=1000,# 每张图片最终输出检测结果最多保留 1000 个,RPN 层没有使用这个参数max_num=1000,# nms 阈值nms_thr=0.7,# 过滤掉的最小 bbox 尺寸min_bbox_size=0),
1.对 batch 输入图片经过 Backbone+FPN+RPN Head 后输出 5 个特征图,每个图包括两个分支 rpn_cls_score,rpn_bbox_pred,首先遍历每张图,然后遍历每张图片中的每个输出层进行后续处理
2.对每层的分类 rpn_cls_score 进行 sigmoid 操作得到概率值
3.按照分类预测分值排序,保留前 nms_pre 个预测结果
if cfg.nms_pre > 0 and scores.shape[0] > cfg.nms_pre:# sort is faster than topk# _, topk_inds = scores.topk(cfg.nms_pre)ranked_scores, rank_inds = scores.sort(descending=True)topk_inds = rank_inds[:cfg.nms_pre]scores = ranked_scores[:cfg.nms_pre]rpn_bbox_pred = rpn_bbox_pred[topk_inds, :]anchors = anchors[topk_inds, :]
4.对每张图片的 5 个输出层都运行 2 ~ 3 步骤,将预测结果全部收集,然后进行解码
scores = torch.cat(mlvl_scores)anchors = torch.cat(mlvl_valid_anchors)rpn_bbox_pred = torch.cat(mlvl_bbox_preds)proposals = self.bbox_coder.decode(anchors, rpn_bbox_pred, max_shape=img_shape)
5.进行统一的 NMS 操作,每张图片最终保留 cfg.nms_post 个预测框
nms_cfg = dict(type='nms', iou_threshold=cfg.nms_thr)dets, keep = batched_nms(proposals, scores, ids, nms_cfg)return dets[:cfg.nms_post]
经过 RPN test 计算后每张图片可以提供最多 nms_post 个候选框,一般该值为 2000。
2.9 RoI Head
R-CNN 模块接收 RPN 输出的每张图片共 nms_post 个候选框,然后对这些候选框进一步 refine,输出包括区分具体类别和 bbox 回归。该模块网络构建方面虽然简单,但是也包括了 RPN 中涉及到的组件,例如 BBox Assigner、BBox Sampler、BBox Encoder Decoder、Loss 等等,除此之外,还包括一个额外的 RPN 到 R-CNN 数据转换模块:RoIAlign 或者 RoIPool, 下面详细描述。
roi_head=dict(# 一次 refine head,另外对应的是级联结构type='StandardRoIHead',bbox_roi_extractor=dict(type='SingleRoIExtractor',roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),out_channels=256,featmap_strides=[4, 8, 16, 32]),bbox_head=dict(# 2 个共享 FC 模块type='Shared2FCBBoxHead',# 输入通道数,相等于 FPN 输出通道in_channels=256,# 中间 FC 层节点个数fc_out_channels=1024,# RoIAlign 或 RoIPool 输出的特征图大小roi_feat_size=7,# 类别个数num_classes=80,# bbox 编解码策略,除了参数外和 RPN 相同,bbox_coder=dict(type='DeltaXYWHBBoxCoder',target_means=[0., 0., 0., 0.],target_stds=[0.1, 0.1, 0.2, 0.2]),# 影响 bbox 分支的通道数,True 表示 4 通道输出,False 表示 4×num_classes 通道输出reg_class_agnostic=False,# CE Lossloss_cls=dict(type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),# L1 Lossloss_bbox=dict(type='L1Loss', loss_weight=1.0))),
从配置可以看出,和 RPN 相比,除了额外的 SingleRoIExtractor 外,基本都是相同的。其训练和测试流程简要概况如下:
(1) 公共部分
- RPN 层输出每张图片最多 nms_post 个候选框,故 R-CNN 输入 shape 为 (batch, nms_post, 4),4 表示 RoI 坐标
- 利用 RoI 重映射规则,将 nms_post 个候选框映射到 FPN 输出的不同特征图上,提取对应的特征图,然后利用插值思想将其变成指定的固定大小输出,输出 shape 为 (batch, nms_post, 256, roi_feat_size, roi_feat_size),其中 256 是 FPN 层输出特征图通道大小,roi_feat_size 一般取 7。上述步骤即为 RoIAlign 或者 RoIPool 计算过程
- 将 (batch, nms_post, 256, roi_feat_size, roi_feat_size) 数据拉伸为 (batchnms_post, 256roi_feat_sizeroi_feat_size),转化为 FC 可以支持的格式, 然后应用两次共享卷积,输出 shape 为 (batchnms_post, 1024)
- 将 (batchnms_post, 1024) 分成分类和回归分支,分类分支输出 (batchnms_post, num_classes+1), 回归分支输出 (batchnms_post, 4num_class)
第二步的映射规则是在 FPN 论文中提出。不知大家是否有疑问:假设某个 proposal 是由第 4 个 特征图层检测出来的,为啥该 proposal 不是直接去对应特征图层切割就行,还需要重新映射?原因是这些 proposal 是 RPN 测试阶段检测出来的,大部分 proposal 可能符合前面设定,但是也有很多不符合的,也就是说测试阶段上述一致性不一定满足,需要重新映射,公式如下:

上述公式中 k_0=4,通过公式可以算出 pk,具体是:
- wh>=448x448,则分配给 p5
- wh<448x448 并且 wh>=224x224,则分配给 p4
- wh<224x224 并且 wh>=112x112,则分配给 p3
- 其余分配给 p2
在 R-CNN 部分没有采用感受野最大的 p6 层。
def map_roi_levels(self, rois, num_levels):"""Map rois to corresponding feature levels by scales.- scale < finest_scale * 2: level 0- finest_scale * 2 <= scale < finest_scale * 4: level 1- finest_scale * 4 <= scale < finest_scale * 8: level 2- scale >= finest_scale * 8: level 3"""scale = torch.sqrt((rois[:, 3] - rois[:, 1]) * (rois[:, 4] - rois[:, 2]))target_lvls = torch.floor(torch.log2(scale / self.finest_scale + 1e-6))target_lvls = target_lvls.clamp(min=0, max=num_levels - 1).long()return target_lvls
其中 finest_scale=56,num_level=5。
在基于候选框提取出对应的特征图后,再利用 RoIAlign 或者 RoIPool 进行统一输出大小,其计算过程在 Mask R-CNN 部分分析。
经过 RoIAlign 或者 RoIPool 后,所有候选框特征图的 shape 为 (batch, nms_post, 256, roi_feat_size, roi_feat_size),将其拉伸后输入到 R-CNN 的 Head 模块中,具体来说主要是包括两层分类和回归共享全连接层 FC,最后是各自的输出头,其 forward 逻辑如下:
if self.num_shared_fcs > 0:x = x.flatten(1)# 两层共享 FCfor fc in self.shared_fcs:x = self.relu(fc(x))x_cls = xx_reg = x# 不共享的分类和回归分支输出cls_score = self.fc_cls(x_cls) if self.with_cls else Nonebbox_pred = self.fc_reg(x_reg) if self.with_reg else Nonereturn cls_score, bbox_pred
最终输出分类和回归预测结果。相比于目前主流的全卷积模型,Faster R-CNN 的 R-CNN 模块依然采用的是全连接模式。
(2) 训练逻辑
rcnn=dict(assigner=dict(# 和 RPN 一样,正负样本定义参数不同type='MaxIoUAssigner',pos_iou_thr=0.5,neg_iou_thr=0.5,min_pos_iou=0.5,match_low_quality=False,ignore_iof_thr=-1),sampler=dict(# 和 RPN 一样,随机采样参数不同type='RandomSampler',num=512,pos_fraction=0.25,neg_pos_ub=-1,# True,RPN 中为 Falseadd_gt_as_proposals=True)
理论上,BBox Assigner 和 BBox Sampler 逻辑可以放置在 (1) 公共部分 后面,因为其任务是输入每张图片的 nms_post 个候选框以及标注的 gt bbox 信息,然后计算每个候选框样本的正负样本属性,最后再进行随机采样尽量保证样本平衡。R-CNN的候选框对应了 RPN 阶段的 anchor,只不过 RPN 中的 anchor 是预设密集的,而 R-CNN 面对的 anchor 是动态稀疏的,RPN 阶段基于 anchor 进行分类回归对应于 R-CNN 阶段基于候选框进行分类回归,思想是完全一致的,故 Faster R-CNN 类算法叫做 two-stage,因此可以简化为 one-stage + RoI 区域特征提取 + one-stage。
实际上为了方便理解,BBox Assigner 和 BBox Sampler 逻辑是在 (1) 公共部分 的步骤 1 后运行的。需要特别注意的是配置参数和 RPN 不同:
- match_low_quality=False。为了避免出现低质量匹配情况(因为 two-stage 算法性能核心在于 R-CNN,RPN 主要保证高召回率,R-CNN 保证高精度),R-CNN 阶段禁用了允许低质量匹配设置
- 3 个 iou_thr 设置都是 0.5,不存在忽略样本,这个参数在 Cascade R-CNN 论文中有详细说明,影响较大
- add_gt_as_proposals=True。主要是克服刚开始 R-CNN 训练不稳定情况
R-CNN 整体训练逻辑如下:
if self.with_bbox or self.with_mask:num_imgs = len(img_metas)sampling_results = []# 遍历每张图片,单独计算 BBox Assigner 和 BBox Samplerfor i in range(num_imgs):# proposal_list 是 RPN test 输出的候选框assign_result = self.bbox_assigner.assign(proposal_list[i], gt_bboxes[i], gt_bboxes_ignore[i],gt_labels[i])# 随机采样sampling_result = self.bbox_sampler.sample(assign_result,proposal_list[i],gt_bboxes[i],gt_labels[i],feats=[lvl_feat[i][None] for lvl_feat in x])sampling_results.append(sampling_result)# 特征重映射+ RoI 区域特征提取+ 网络 forward + Loss 计算losses = dict()# bbox head forward and lossif self.with_bbox:bbox_results = self._bbox_forward_train(x, sampling_results,gt_bboxes, gt_labels,img_metas)losses.update(bbox_results['loss_bbox'])# mask head forward and lossif self.with_mask:mask_results = self._mask_forward_train(x, sampling_results,bbox_results['bbox_feats'],gt_masks, img_metas)losses.update(mask_results['loss_mask'])return losses
_bbox_forward_train 逻辑和 RPN 非常类似,只不过多了额外的 RoI 区域特征提取步骤:
def _bbox_forward_train(self, x, sampling_results, gt_bboxes, gt_labels,img_metas):rois = bbox2roi([res.bboxes for res in sampling_results])# 特征重映射+ RoI 特征提取+ 网络 forwardbbox_results = self._bbox_forward(x, rois)# 计算每个样本对应的 target, bbox encoder 在内部进行bbox_targets = self.bbox_head.get_targets(sampling_results, gt_bboxes,gt_labels, self.train_cfg)# 计算 lossloss_bbox = self.bbox_head.loss(bbox_results['cls_score'],bbox_results['bbox_pred'], rois,*bbox_targets)bbox_results.update(loss_bbox=loss_bbox)return bbox_results
_bbox_forward 逻辑是 R-CNN 的重点:
def _bbox_forward(self, x, rois):# 特征重映射+ RoI 区域特征提取,仅仅考虑前 num_inputs 个特征图bbox_feats = self.bbox_roi_extractor(x[:self.bbox_roi_extractor.num_inputs], rois)# 共享模块if self.with_shared_head:bbox_feats = self.shared_head(bbox_feats)# 独立分类和回归 headcls_score, bbox_pred = self.bbox_head(bbox_feats)bbox_results = dict(cls_score=cls_score, bbox_pred=bbox_pred, bbox_feats=bbox_feats)return bbox_results
(3) 测试逻辑
rcnn=dict(score_thr=0.05,nms=dict(type='nms', iou_threshold=0.5),max_per_img=100)
测试逻辑核心逻辑如下:
- 公共逻辑部分输出 batch * nms_post 个候选框的分类和回归预测结果
- 将所有预测结果按照 batch 维度进行切分,然后依据单张图片进行后处理,后处理逻辑为:先解码并还原为原图尺度;然后利用 score_thr 去除低分值预测;然后进行 NMS;最后保留最多 max_per_img 个结果
3 Mask R-CNN 代码详解
Mask R-CNN 和 Faster R-CNN 的区别主要包括两个方面:
- R-CNN 中额外引入 Mask Head,从而可以实现实例分割任务
针对特征图与原始图像上的 RoI 不对准问题,提出了 RoIPool 的改进版本 RoIAlign
3.1 Mask Head
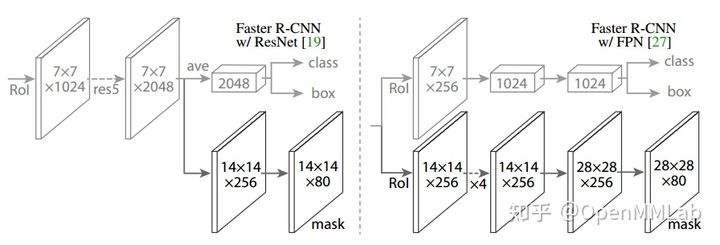
上图为在 Faster R-CNN 和 FPN 基础上扩展得到 Mask R-CNN 模型,本文解读的是 FPN 扩展的 Mask R-CNN 模型,其简要描述为:bbox 分支和 mask 分支都有自己的 RoI 区域特征提取算子,其中由于 mask 任务要求更加精细的结果,所以 RoI 特征区域提取算子输出特征图比 bbox 分支大,一般设置为 14
- bbox 分支是全连接结构,而 mask 分支是全卷积结构,输出 shape 为 (batch* num_post,80,28,28),其中 80 表示类别,即输出的每个通道代表一个类别的 mask
- 由于 mask 分支目的是对前景物体进行分割,故该分支的输入仅仅包括 Bbox Assigner 加上 Bbox Sampler 后的正样本而已
- 在测试阶段,为了避免 bbox 和 mask 结果没有对齐,做法是先对 bbox 分支进行后处理,得到预测的 bbox,然后将 bbox 作为 proposal 输入到 mask 分支中进行 RoI 特征区域提取和 forward,输出和类别相关的 mask。为了得到二值分割图,还需要在 test_cfg 指定 mask_thr_binary 参数,一般设置为 0.5
结合上面图示和配置就可以知道 Mask R-CNN 所有细节:
roi_head=dict(# 和 Faster R-CNN 完全相同type='StandardRoIHead',bbox_roi_extractor=dict(type='SingleRoIExtractor',roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),out_channels=256,featmap_strides=[4, 8, 16, 32]),bbox_head=dict(type='Shared2FCBBoxHead',in_channels=256,fc_out_channels=1024,roi_feat_size=7,num_classes=80,bbox_coder=dict(type='DeltaXYWHBBoxCoder',target_means=[0., 0., 0., 0.],target_stds=[0.1, 0.1, 0.2, 0.2]),reg_class_agnostic=False,loss_cls=dict(type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),loss_bbox=dict(type='L1Loss', loss_weight=1.0)),# mask 分支也有自己的 RoIAlignmask_roi_extractor=dict(type='SingleRoIExtractor',# 除了 output_size 不同外,其他都相同roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),out_channels=256,featmap_strides=[4, 8, 16, 32]),# 全卷积 headmask_head=dict(type='FCNMaskHead',# 总共 4 层卷积num_convs=4,in_channels=256,# 中间卷积通道数conv_out_channels=256,# 输出类别num_classes=80,# loss 采用 bce lossloss_mask=dict(type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))),
3.2 RoIAlign 和 RoIPool
Mask R-CNN 中一个比较大的创新点就是提出了 RoIAlign 层,本小节先描述 RoIPool 层原理以及缺点,然后再分析 RoIAlign。
(1) RoIPool
首先需要明确其作用: 将任意大小的特征图都池化为指定输出大小。示意图如下:
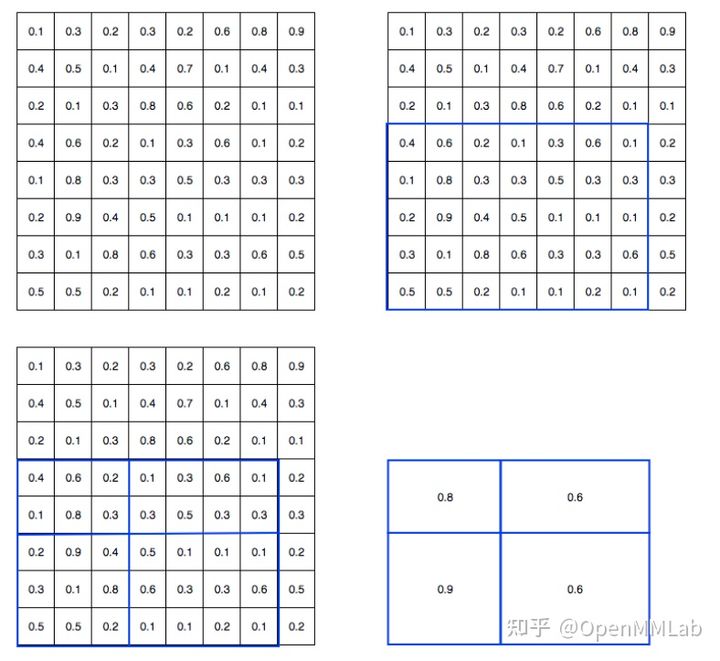
假设左上图为输入特征图,bbox 分支预测的坐标可能是浮点数,设置 RoIPool 输出 size 是 (2,2)
- 首先将 bbox 预测值转化为整数,得到右上蓝框
- 将蓝框内 5x7 的特征图均匀切割为 2x2 的块,但是由于取整操作,实际上第一个块是 wh=(7//2,5//2),第二个块是 wh=(7-7//2,5-5//2), 后面类似,从而得到左下图示
- 然后在每个小块内采用 MaxPool 提取最大值,从而得到右下角的 2x2 输出
可以发现 RoIPool 存在两次取整操作,第一次是将 proposal 值变成整数,第二次是均匀切割时候。对于小物体的特征图而言,两次取整操作特征图会产生比较大的偏差,从而对 分割和定位精度有比较大的影响,在论文里作者把它总结为“不匹配问题”(mis-alignment)。
(2) RoIAlign
为了解决这个问题,RoIAlign 取消两次整数化操作,保留了小数,每个小数位置都采用双线性插值方法获得坐标为浮点数的特征图上数值, 其可视化如下所示:
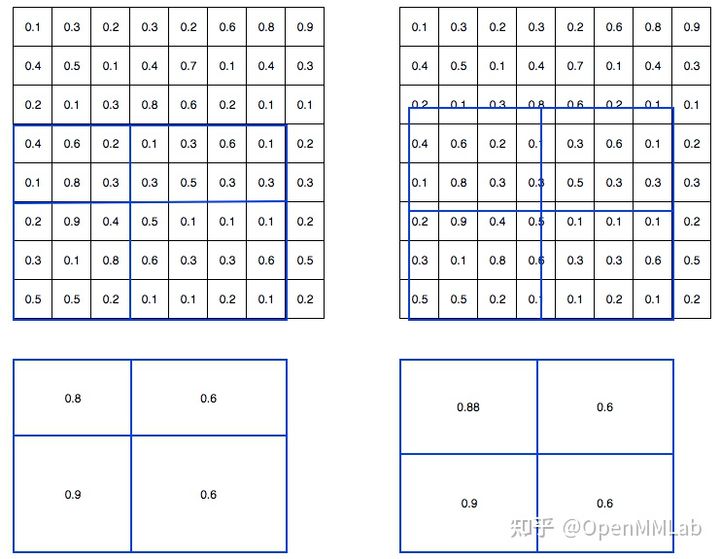
其对应的论文图示如下:

假设黑色大框是要切割的 bbox,打算输出 size 为 2x2 输出,则先把黑色大 bbox 均匀切割为 4 个小 bbox,然后在每个小 bbox 内部均匀采样 4 个点(相当于每个小 bbox 内部再次均匀切割为 2x2 共 4 个小块,取每个小块的中心点即可),首先对每个采样点利用双线性插值函数得到该浮点值处的值(插值的 4 个整数点是上下左右最近的 4 个点),然后对 4 个采样点采样值取 max 操作得到该小 bbox 的最终值。采样个数 4 是超参,实验发现设置为 4 的时候速度和精度都是最合适的。
关于 RoIAlign 和 RoIPool 的源码实现,由于是采用 CUDA 编程,在后续系列中统一进行分析。
3 总结
本文重点分析了主流的带有 FPN 模块的 Faster R-CNN 算法,对每个组件都进行了详细分析,在此基础上,对其扩展版本 Mask R-CNN 进行了详细描述。通过本系列第一篇 RetinaNet 和 本文第二篇 Faster R-CNN 和 Mask R-CNN的解读,希望大家可以了解:
- 掌握 MMDetection 中涉及到的常用配置参数含义
- 掌握 MMDetection 框架中两个经典算法 RetinaNet 和 Faster R-CNN
- 对 one-stage 和 two-stage 算法有清晰的理解,例如能够理解 two-stage 实际上可以认为是 one-stage + RoI 区域特征提取 + one-stage,对于 Cascade R-CNN 这类算法可以认为是 one-stage + RoI 区域特征提取 + one-stage + RoI 区域特征提取 + one-stage
- RetinaNet 和 Faster R-CNN 解读完后,大家阅读 MMDetection 中大部分算法都会相对容易

若有收获,就点个赞吧
0 人点赞
