Hierarchical Vision Transformer using Shift Windows
摘要
Presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision.
面临的挑战Challenges in adapting Transformer from language to vision arise from differences between the two domains
- large variations in the scale of visual entities
- high resolution of pixels in images compared to words in text.
To address these differences, we propose a hierarchical Transformer whose representation is computed with Shifted windows.
面临挑战所采取的措施The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at various scales and has linear computational complexity with respect to image size.
取得的成果
- image classification(87.3 top-1 accuracy on ImageNet-1K)
- Object Detection (58.7 box AP and 51.1 mask AP on COCO test-dev)
- +2.7 box AP on COCO
- +2.6 mask AP on COCO compare to state-of-art
- semantic segmentation (53.5 mIoU on ADE20K val)
- +3.2 mIoU on AED20K compare to state-of-art
1. 介绍
现代的计算机视觉任务被CNN系列网络所主导,CNN的广泛应用起始于AlexNet在ImageNet上的革命性的表现。随着CNN架构的深度、广度的增加和更优美的结构,使得其更加强大。随着CNN作为各大视觉任务的Backbone,这个架构广阔的提升了整个领域。
另一方面随着Transformer在NLP领域的流行已经取得的巨大成功,使得很多研究者去研究把Transformer引入到计算机视觉任务中来。
- visual elements can vary substantially in scale, a problem that receives attention in tasks such as object Detection.
- much higher resolution of pixels in images compared to words in passages of text.
2. 相关工作
CNN及其变种
AlexNet、VGG、GoogleNet、ResNet、DenseNet、HRNet和EfficientNet
虽然CNN及其变种仍然是计算机视觉任务最重要的Backbone,但是我们强调能应用在自然语言处理和计算机视觉的类Transformer-based大一统架构是潜在的Backbone
使用Self-attention和Transformers去完善CNNs
providing the capability to encode distant dependencies or heterogeneous interactions.
- self-attention layers complement backbones
- self-attention layers complement head networks
encoder-decoder design in Transformer has been applied for the object detection
Transformer based vision backbones
Vision Transformer(ViT) 以及他的follow-ups
- ViT在图像分类上的结果喜人,但是却不适合作为一个通用的视觉Backbone
- low-resolution feature maps
- the quadratic increase in complexity with image size.
3. 方法
3.1. 整体架构
- 每个patch被看做是一个token
- 一些Transformer blocks和编辑过的自注意力模块(Swin Transformer blocks)被用于这些patch tokens。
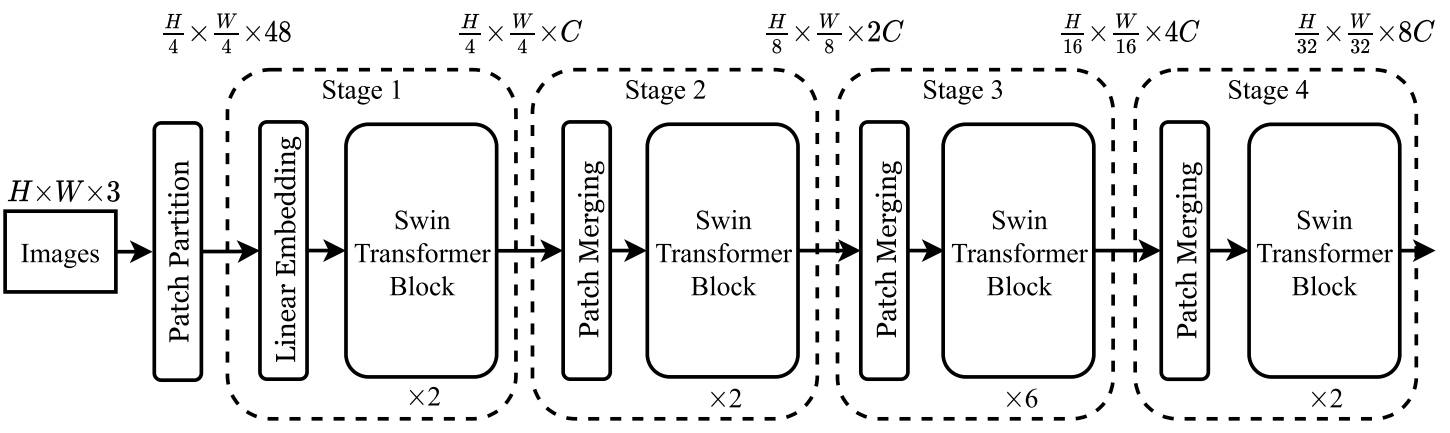
The architecture of a Swin Transformer (Swin-T)
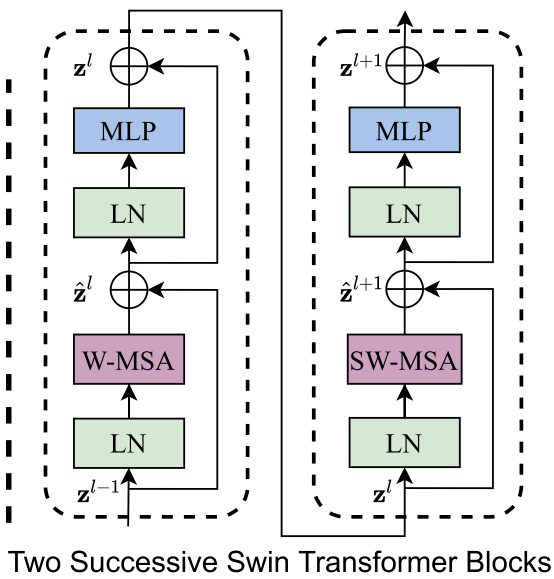
two successive Swin Transformer Blocks (notation presented with Eq. (3)). W-MSA and SW-MSA are multi-head self attention modules with regular and shifted windowing configurations, respectively.
Stage1
Several Transformer blocks with modified self-attention computation(Swin Transformer blocks) are applied on patch tokens.
Stage2
To produce a hierarchical representation, the number of tokens is reduced by patch merging layers as the network gets deeper. The
Swin Transformer block
Swin Transformer is built by replacing the standard multi-head self attention (MSA) module in a Transformer block by a module based on shifted windows (described in Section 3.2), with other lay- ers kept the same. As illustrated in Figure 3(b), a Swin Transformer block consists of a shifted window based MSA module, followed by a 2-layer MLP with GELU non- linearity in between. A LayerNorm (LN) layer is applied before each MSA module and each MLP, and a residual connection is applied after each module.
3.2. Shifted Window based Self-Attention
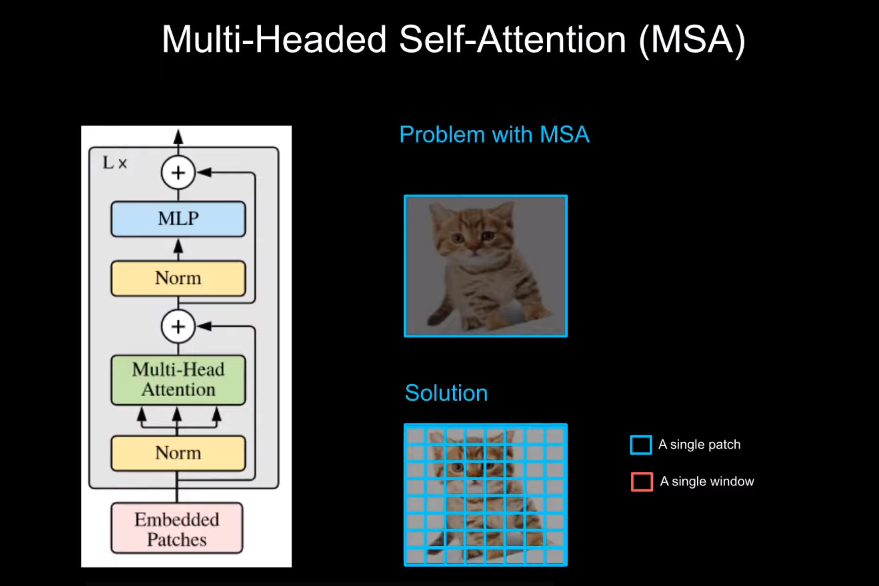
Self-attention in non-overlapped windows
Shifted window partitioning in successive blocks
Efficient batch computation for shifted configuration
Relative position bias
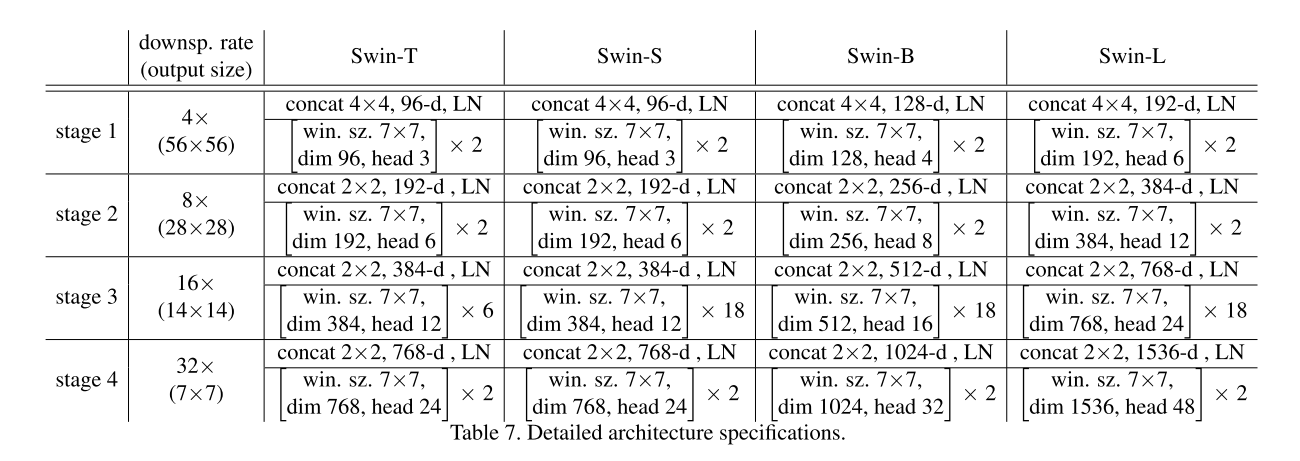
3.3. Architecture Variants
mmdet中swin代码源码解析
SwinTransformer类
| 关键参数名称 | 参数解释 | 默认值 |
|---|---|---|
| pretrain_img_size (int | tuple[int]) | The size of input image when pretrain. | 224 |
| in_channels (int) | The num of input channels. | 3 |
| embed_dims (int) | The feature dimension. | 96 |
| patch_size (int | tuple[int]) | Patch size. | 4 |
| window_size (int) | Window size. | 7 |
| mlp_ratio (int) | Ratio of mlp hidden dim to embedding dim. | 4 |
| depths (tuple[int]) | Depths of each Swin Transformer stage. | (2, 2, 6, 2) |
| num_heads (tuple[int]) | Parallel attention heads of each Swin Transformer stage. | (3, 6, 12, 24) |
| strides (tuple[int]) | The patch merging or patch embedding stride of each Swin Transformer stage. (In swin, we set kernel size equal to stride.) | (4, 2, 2, 2) |
| out_indices (tuple[int]) | Output from which stages. | Default: (0, 1, 2, 3). |
| qkv_bias (bool, optional) | If True, add a learnable bias to query, key, value. | True |
| qk_scale (float | None, optional) | Override default qk scale of head_dim ** -0.5 if set. | None |
| patch_norm (bool) | If add a norm layer for patch embed and patch merging. | True |
| drop_rate (float) | Dropout rate. | 0 |
| attn_drop_rate (float) | Attention dropout rate. | 0 |
| drop_path_rate (float) | Stochastic depth rate. | 0.1 |
| use_abs_pos_embed | If True, add absolute position embedding to the patch embedding. | False |
| act_cfg (dict) | Config dict for activation layer. | dict(type=’LN’) |
| norm_cfg (dict) | Config dict for normalization layer at output of backone. | dict(type=’LN’) |
| with_cp (bool, optional) | Use checkpoint or not. Using checkpoint will save some memory while slowing down the training speed. | False |
| pretrained (str, optional) | model pretrained path. | None |
| convert_weights (bool) | The flag indicates whether the pre-trained model is from the original repo. We may need to convert some keys to make it compatible. | False |
| frozen_stages (int) | Stages to be frozen (stop grad and set eval mode). | -1 means not freezing any parameters. |
| init_cfg (dict, optional): | The Config for initialization. | None |
Swin Transformer 通道数变换
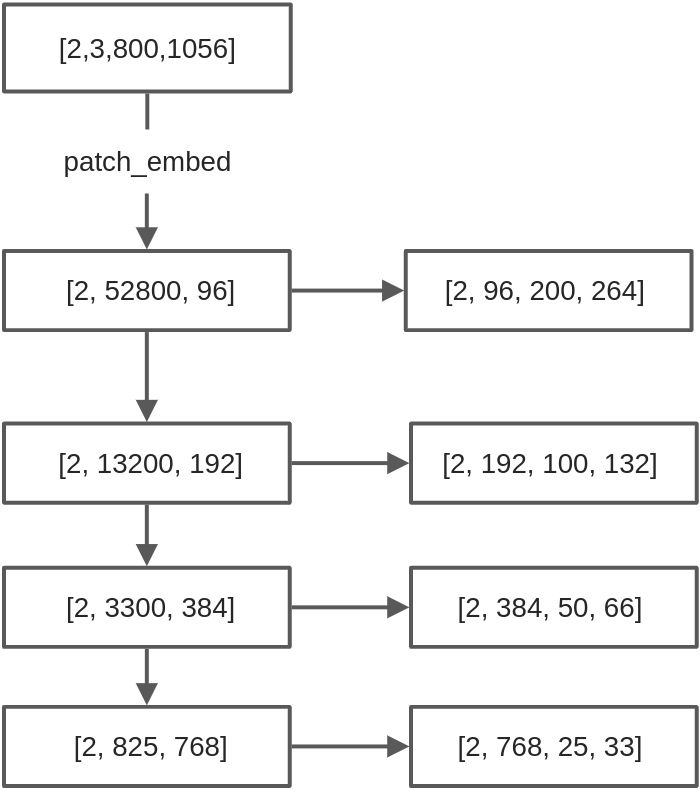
参考
https://jalammar.github.io/illustrated-transformer/
视频【沈向洋带你读论文】Swin Transformer 马尔奖论文(ICCV 2021最佳论文)
(YouTube)Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (paper illustrated)

若有收获,就点个赞吧
0 人点赞
