Abstract
- Region Proposal Network(RPN)
- We further merge RPN and Fast R-CNN into a single network by sharing their convolutional features,using the recently popular terminology of neural networks with “attention” mechanisms,the RPN component tells the unified network where to look.
Introduction
Selective Search在GPU实现上大概需要2s每张图片,EdgeBoxes在区域提案的质量和速度上达到平衡,0.2s一张图片,无论怎么说Region Proposal的步骤依然是检测任务中最消耗时间的步骤。
RPN充分利用了GPU的优势,并且和SSP NET 或者 fast rcnn 共享网络层,所以开销是非常小的。
By sharing convolutions at test-time, the marginal cost for computing proposals is small (e.g., 10ms per image).
Relate Work
FASTER R-CNN
3.1. Region Proposal Networks
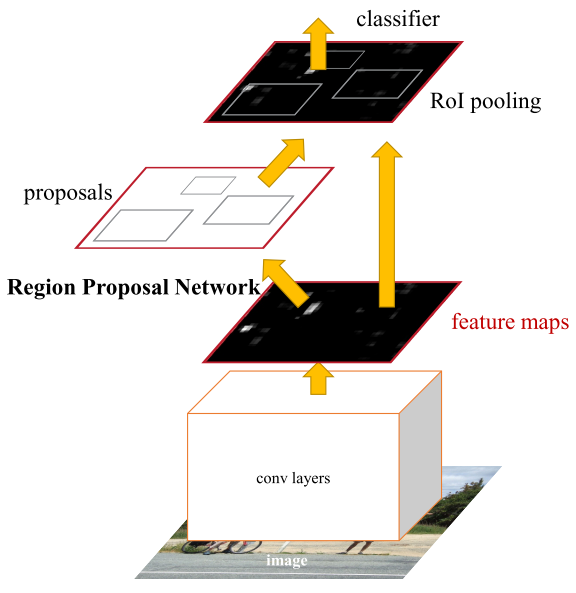
Figure 2: Faster R-CNN is a single, unified network for object detection. The RPN module serves as the ‘attention’ of this unified network.
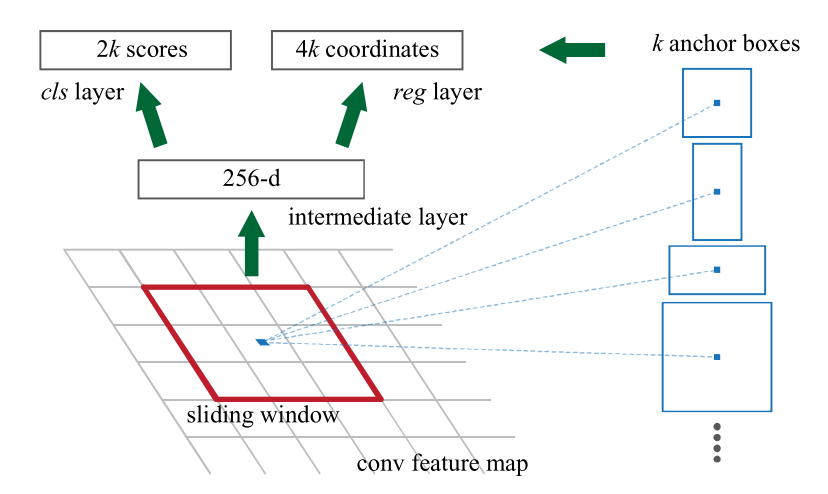
Region Proposal Network (RPN)
3.1.1 Anchors
At each sliding-window location, we simultaneously predict multiple region proposals, where the number of maximum possible proposals for each location is denoted as k. So the reg layer has 4k outputs encoding the coordinates of k boxes, and the cls layer outputs 2k scores that estimate probability of object or not object for each proposal4. The k proposals are param- eterized relative to k reference boxes, which we call anchors. An anchor is centered at the sliding window in question, and is associated with a scale and aspect ratio (Figure 3, left). By default we use 3 scales and 3 aspect ratios, yielding k = 9 anchors at each sliding position. For a convolutional feature map of a size W×H (typically ∼2,400), there are WHk anchors in total.
Anchor Box的概念,是为了解决同一个网格中有多个目标对象的情况。现实情况中,你的网格划分越细,比如将3x3的网格变为10x10,这种同一个网格中有多个目标对象的情况就越少。
Translation-Invariant Anchors
Multi-Scale Anchors as Regression References
3.1.2 Loss Function

 :Anchor[i]的预测分类概率;
:Anchor[i]的预测分类概率;
- Anchor[i]是正样本时,

- Anchor[i]是负样本时,

什么是正样本与负样本
满足以下条件的Anchor是正样本:
与Ground Truth Box的IOU(Intersection-Over-Union) 的重叠区域最大的Anchor;
与Gound Truth Box的IOU的重叠区域>0.7;
满足以下条件的Anchor是负样本:
与Gound Truth Box的IOU的重叠区域 <0.3;
既不属于正样本又不属于负样本的Anchor不参与训练。
 : Anchor[i]预测的Bounding Box的参数化坐标(parameterized coordinates);
: Anchor[i]预测的Bounding Box的参数化坐标(parameterized coordinates); : Anchor[i]的Ground Truth的Bounding Box的参数化坐标;
: Anchor[i]的Ground Truth的Bounding Box的参数化坐标;



其中, 是Box的中心点坐标,宽度、高度;
是Box的中心点坐标,宽度、高度; 分别对应于Predicted Box,Anchor Box,GroundTruth Box;
分别对应于Predicted Box,Anchor Box,GroundTruth Box; 也类似
也类似
 : mini-batch size;
: mini-batch size; : Anchor Location的数量;
: Anchor Location的数量;
 表示只有在正样本时才回归Bounding Box。
表示只有在正样本时才回归Bounding Box。
Smooth L1 Loss



本节参考文章
https://zhuanlan.zhihu.com/p/72579976
3.1.3 Training RPNs
3.2. Sharing Features for RPN and Fast R-CNN
Alternating training
Approximate joint training.
Non-approximate joint training.
3.3. Implementation Details
EXPERIMENTS
4.1. Experiments on PASCAL VOC
4.2. Experiments on MS COCO
4.3. From MS COCO to PASCAL VOC
5. Conclusion
We have presented RPNs for efficient and accurate region proposal generation. By sharing convolutional features with the down-stream detection network, the region proposal step is nearly cost-free. Our method enables a unified, deep-learning-based object detection system to run at near real-time frame rates. The learned RPN also improves region proposal quality and thus the overall object detection accuracy.

若有收获,就点个赞吧
0 人点赞
