1. Introduction
- We introduce SSD, a single-shot detector for multiple categories that is faster than the previous state-of-the-art for single shot detectors (YOLO), and significantly more accurate, in fact as accurate as slower techniques that perform explicit region proposals and pooling (including Faster R-CNN).
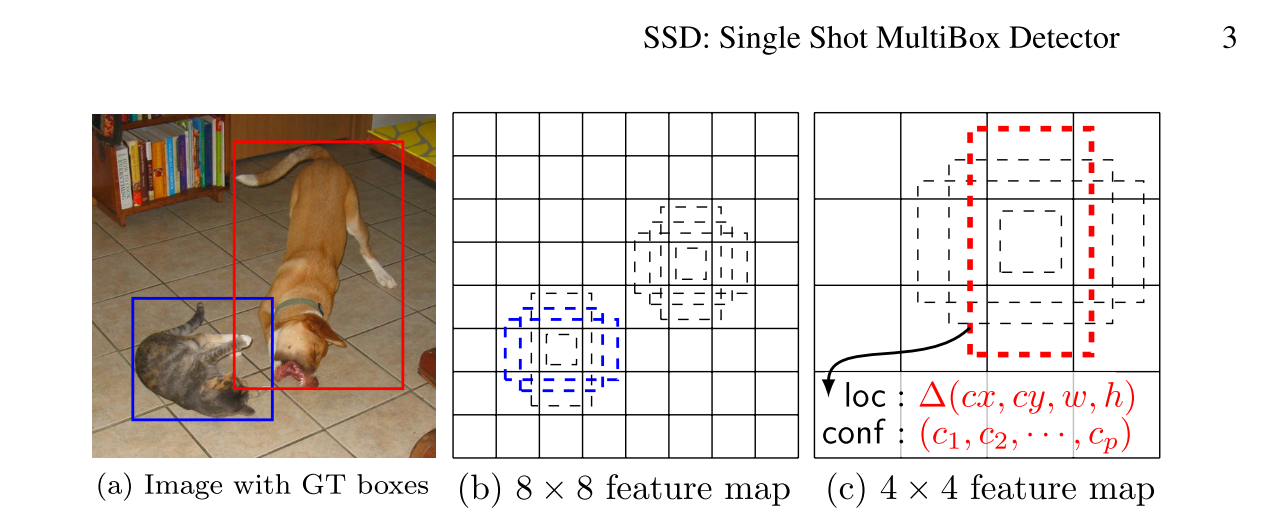
- The core of SSD is predicting category scores and box offsets for a fixed set of default bounding boxes using small convolutional filters applied to feature maps.
- To achieve high detection accuracy we produce predictions of different scales from feature maps of different scales, and explicitly separate predictions by aspect ratio.
- These design features lead to simple end-to-end training and high accuracy, even on low resolution input images, further improving the speed vs accuracy trade-off.
- Experiments include timing and accuracy analysis on models with varying input size evaluated on PASCAL VOC, COCO, and ILSVRC and are compared to a range of recent state-of-the-art approaches.
2. The Single Shot Detector (SSD)
2.1. Model
The SSD approach is based on a feed-forward convolutional network that produces a fixed-size collection of bounding boxes and scores for the presence of object class instances in those boxes, followed by a non-maximum suppression step to produce the final detections. The early network layers are based on a standard architecture used for high-quality image classification (truncated before any classification layers), which we will call the base network2. We then add auxiliary structure to the network to produce detections with the following key features:
Multi-scale feature maps for detection
Convolutional predictors for detection
2.2 Training
3. Experimental Results
3.1 PASCAL VOC2007
3.2 Model analysis
3.3 PASCAL VOC2012
3.4 COCO
3.5 Preliminary ILSVRC results
3.6 Data Augmentation for Small Object Accuracy
3.7 Inference time
4 Related Work
5 Conclusions

若有收获,就点个赞吧
0 人点赞
