个人论文阅读笔记,仅供参考,详细准确请阅读原文。
本文提出了 Fast Region-based Convolutional Network method (Fast R-CNN) for object detection. Fast R-CNN builds on previous work to efficiently classify object proposals using deep convolutional networks.跟先前的工作相比,Fast R-CNN采取了多种方式提升训练和测试的速度,并且提升了精度。 Faster RCNN使用VGG-16进行训练,比RCNN训练时间快9倍,测试时间是RCNN的213倍,并且在PASCAL VOC 2012上取得更高的mAP。与SPPnet相比,Faster RCNN在VGG16网络上,训练快3倍,测试速度快10倍,并且在精度上更加准确。Fast RCNN 使用 Python 和 C++实现(基于Caffee),代码使用MIT协议进行开源https://github.com/rbgirshick/fast-rcnn
1. Introduction
近年来,深度卷积网络极大的提高了图像分类和目标检测的精度。相比于图像分类,目标检测是一个更具挑战性的任务,需要更多的方法去解决。因其的复杂度,目前多阶段pipeline训练模型的方法非常慢且不优雅。
1.1 R-CNN and SPPnet
RCNN使用深度卷积网络对提议框进行分类,使得目标检测的精度大大提升,缺具有以下的缺陷
RCNN的缺陷
多阶段分开训练,非端对端系统
RCNN首先使用log loss微调目标候选框
it fits SVMs to ConvNet features.
These SVMs act as object detectors, replacing the softmax classifier learnt by fine-tuning. In the third training stage, bounding-box regressors are learned.
训练非常耗费空间和时间
For SVM and bounding-box regressor training, features are extracted from each object proposal in each image and written to disk. With very deep networks, such as VGG16, this process takes 2.5 GPU-days for the 5k images of the VOC07 train val set. These features require hundreds of gigabytes of storage.
目标检测推理非常慢
使用VGG16进行测试花费47s/图片
R-CNN如此慢的原因是因为对每一个Proposal框都进行卷积forward,且不共享计算层。SPPnet实现特征图共享,但是也有很多其他缺陷 ① 多阶段训练 ② Feature仍然需要被写入disk
1.2. 本文贡献
- Higher detection quality (mAP) than R-CNN, SPPnet
2. Training is single-stage, using a multi-task loss
3. Training can update all network layers
4. No disk storage is required for feature caching2. Fast R-CNN architecture and training
Fig. 1 illustrates the Fast R-CNN architecture. A Fast R-CNN network takes as input an entire image and a set of object proposals. The network first processes the whole image with several convolutional (conv) and max pooling layers to produce a conv feature map. Then, for each object proposal a region of interest (RoI) pooling layer extracts a fixed-length feature vector from the feature map. Each feature vector is fed into a sequence of fully connected (fc) layers that finally branch into two sibling output layers: one that produces softmax probability estimates over K object classes plus a catch-all “background” class and another layer that outputs four real-valued numbers for each of the K object classes. Each set of 4 values encodes refined bounding-box positions for one of the K classes.
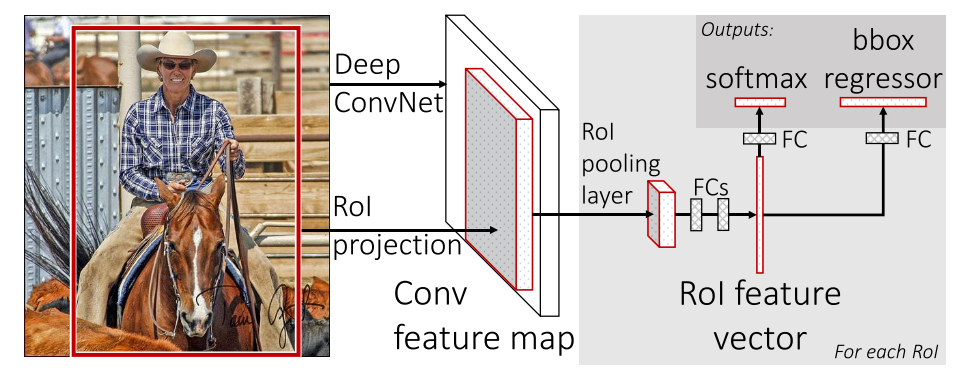
Figure 1. Fast R-CNN architecture. An input image and multiple regions of interest (ROIs) are input into a fully convolutional network. Each RoI is pooled into a fixed-size feature map and then mapped to a feature vector by fully connected layers (FCs). The network has two output vectors per RoI: softmax probabilities and per-class bounding-box regression offsets. The architecture is trained end-to-end with a multi-task loss.
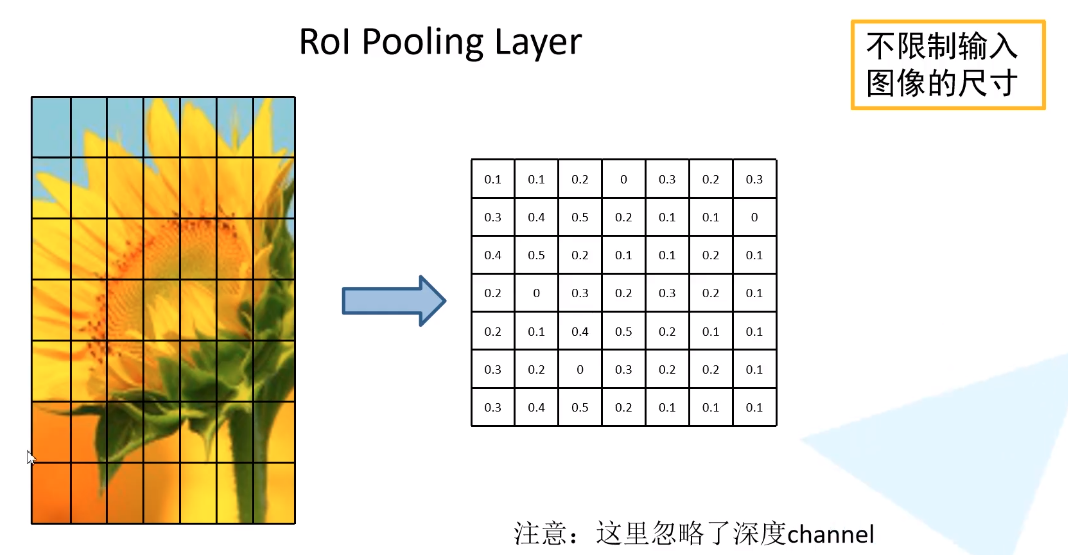
2.1. The RoI pooling layer
roipooling就是把输入图像的不同尺寸候选框映射到特征图上相同尺寸,其间会有两次取整操作,会损失一些精度,故之后又提出roialign。

4. Main results
Three main results support this paper’s contributions:
- State-of-the-art mAP on VOC07, 2010, and 2012
- Fast training and testing compared to R-CNN, SPPnet
- Fine-tuning conv layers in VGG16 improves mAP
4.1. Experimental setup
5. 设计评估
5.1. 多任务训练是否有帮助?
5.2. 尺度不变性: 是蛮力还是技巧?
5.3. 我们需要更多的训练数据吗?
5.4. SVMs比softmax更加优越吗?
5.5. 提议框是越多越好吗? Are more proposals always better?

若有收获,就点个赞吧
0 人点赞
