数理统计中均方误差是指参数估计值与参数值之差平方的期望值,记为MSE。MSE是衡量“平均误差”的一种较方便的方法,MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。
SSE(和方差)
在统计学中,该参数计算的是拟合数据和原始对应点的误差的平方和,计算公式为:
其中  是真实数据,
是真实数据,  是拟合的数据,
是拟合的数据,  ,从这里可以看出SSE接近于0,说明模型选择和拟合更好,数据预测也越成功。
,从这里可以看出SSE接近于0,说明模型选择和拟合更好,数据预测也越成功。
MSE(均方方差)
该统计参数是预测数据和原始数据对应点误差的平方和的均值,也就是  ,和SSE没有太大的区别,计算公式为:<br /><br />其中,n为样本的个数。
RMSE
该统计参数,也叫回归系统的拟合标准差,是MSE的平方根,计算公式为:

Mean-Squared Loss的概率解释
假设我们的模型是二维平面的线性回归模型:  ,对于这个模型,我们定义损失函数为MSE,将得到如下的表达式:
,对于这个模型,我们定义损失函数为MSE,将得到如下的表达式:
下面我们试着通过概率的角度,推导出上述的MSE损失函数表达式。
在线性回归模型中,我们最终希望对于输入  进行线性组合得到值Y,考虑到输入带有噪声的情况的表达式如下:
进行线性组合得到值Y,考虑到输入带有噪声的情况的表达式如下:
为了使模型更合理,我们假设  服从均值为0,方差为1的高斯分布,即
服从均值为0,方差为1的高斯分布,即  。所以有:
。所以有:

所以,Y服从均值为  ,方差为1的高斯分布,则样本点的
,方差为1的高斯分布,则样本点的  概率为:
概率为:
有了单个样本的概率,我们就可以计算样本集的似然概率,我们假设每个样本是独立的:

对似然函数取对数,得到对数似然函数:

这个对数似然函数的形式和我们的MSE损失函数的定义是一样的。所以,使用MSE损失函数意味着,我们假设我们的模型是对噪声的输入做估计,该噪声服从高斯分布。
损失函数效果
缺点
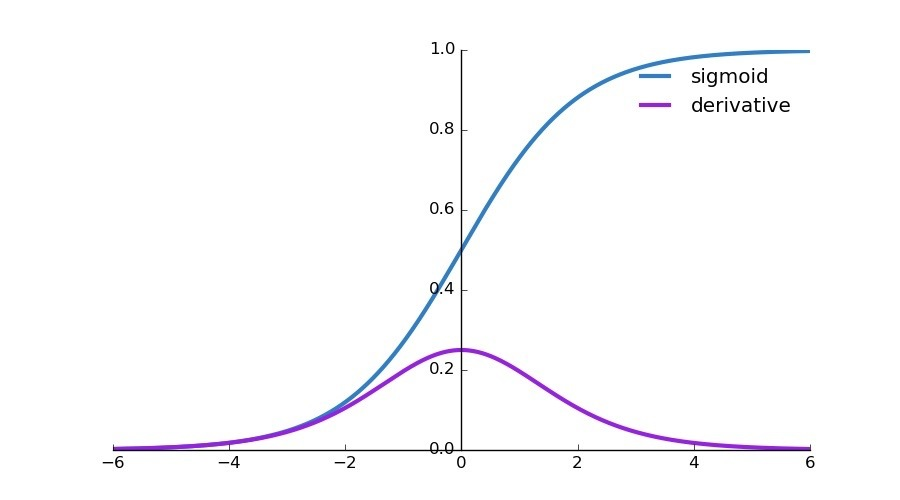
使用MSE的一个缺点就是其偏导值在输出概率值接近0或者接近1的时候非常小,这可能会造成模型刚开始训练时,偏导值几乎消失。
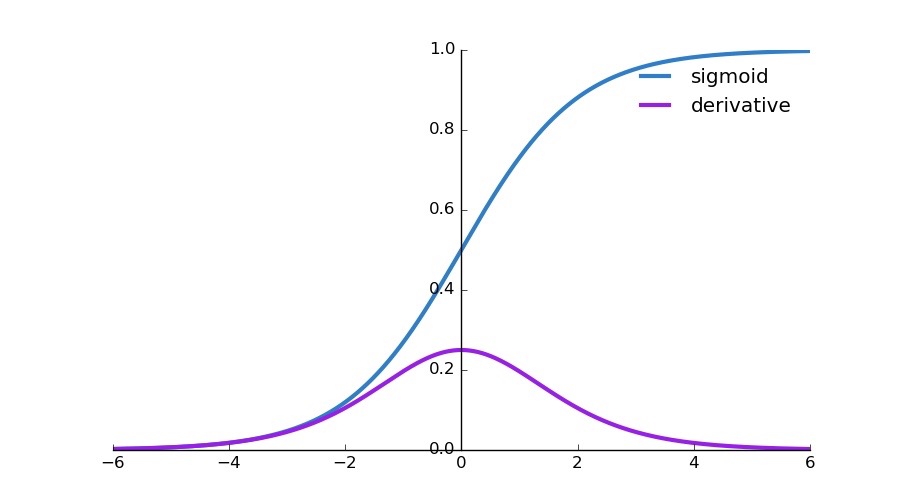
这导致模型在一开始学习的时候速率非常慢,而使用交叉熵作为损失函数则不会导致这样的情况发生
参考

若有收获,就点个赞吧
0 人点赞
