- 1. 优化器 Optimizer
- 1.0 基本用法
- 1.1 PyTorch 中的优化器
- 1.2 父类Optimizer 基本原理
- 1.3 常见优化器简介
- 1.3.1 SGD(params, lr, momentum=0, dampening=0, weight_decay=0, nesterov=False)
- 1.3.2 Adagrad(params, lr=0.01, lr_decay=0, weight_decay=0, initial_accumulator_value=0, eps=1e-10)
- 1.3.3 RMSprop(params, lr=0.01, alpha=0.99, eps=1e-08, weight_decay=0, momentum=0, centered=False)
- 1.3.4 Adam(params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=0, amsgrad=False)
- 2 学习率调节器 lr_scheduler
- 2.1 基类: _LRScheduler
- 2.2 学习率调整策略示例
- 2.2.1 StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1, verbose=False)
- 2.2.2 MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1, verbose=False)
- 2.2.3 MultiplicativeLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)
- 2.2.4 LambdaLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)
- 2.2.5 ExponentialLR(optimizer, gamma, last_epoch=-1, verbose=False)
- 2.2.6 CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1, verbose=False)
- 2.2.7 CosineAnnealingWarmRestarts(optimizer, T_0, T_mult=1, eta_min=0, last_epoch=-1, verbose=False)
- 2.2.8 CyclicLR(optimizer, base_lr, max_lr, step_size_up=2000, step_size_down=None, mode=’triangular’, …)
- 2.2.9 OneCycleLR(optimizer, max_lr, total_steps=None, epochs=None, steps_per_epoch=None, pct_start=0.3,…)
- 2.2.10 ReduceLROnPlateau(optimizer, mode=’min’, factor=0.1, patience=10, threshold=0.0001, threshold_mode=’rel’, …)
- 3 swa_utils里SWA相关类和函数
本篇笔记主要介绍torch.optim模块,主要包含模型训练的优化器Optimizer, 学习率调整策略LRScheduler 以及SWA相关优化策略. 本文中涉及的源码以torch==1.7.0为准. 本文参考了mmlab的知乎文章加工后形成
- 优化器 Optimizer
- 学习率调节器 lr_scheduler
- 随机参数平均 swa_utils
- 参考资料
1. 优化器 Optimizer
1.0 基本用法
- 优化器主要是在模型训练阶段对模型可学习参数进行更新, 常用优化器有 SGD,RMSprop,Adam等
- 优化器初始化时传入传入模型的可学习参数,以及其他超参数如 lr,momentum等
- 在训练过程中先调用 optimizer.zero_grad() 清空梯度,再调用 loss.backward() 反向传播,最后调用 optimizer.step()更新模型参数
- 两个方法可用来实现模型训练中断后继续训练功能
简单使用示例如下所示:
import torchimport numpy as npimport warningswarnings.filterwarnings('ignore') #ignore warningsx = torch.linspace(-np.pi, np.pi, 2000)y = torch.sin(x)p = torch.tensor([1, 2, 3])xx = x.unsqueeze(-1).pow(p)model = torch.nn.Sequential(torch.nn.Linear(3, 1),torch.nn.Flatten(0, 1))loss_fn = torch.nn.MSELoss(reduction='sum')learning_rate = 1e-3optimizer = torch.optim.RMSprop(model.parameters(), lr=learning_rate)for t in range(1, 1001):y_pred = model(xx)loss = loss_fn(y_pred, y)if t % 100 == 0:print('No.{: 5d}, loss: {:.6f}'.format(t, loss.item()))optimizer.zero_grad() # 梯度清零loss.backward() # 反向传播计算梯度optimizer.step() # 梯度下降法更新参数
1.1 PyTorch 中的优化器
所有优化器都是继承父类 Optimizer,如下列表是 PyTorch 提供的优化器:
- SGD
- ASGD
- Adadelta
- Adagrad
- Adam
- AdamW
- Adamax
- SparseAdam
- RMSprop
- Rprop
- LBFGS
1.2 父类Optimizer 基本原理
Optimizer 是所有优化器的父类,它主要有如下公共方法:
- add_param_group(param_group): 添加模型可学习参数组
- step(closure): 进行一次参数更新
- zero_grad(): 清空上次迭代记录的梯度信息
- state_dict(): 返回 dict 结构的参数状态
- load_state_dict(state_dict): 加载 dict 结构的参数状态
1.2.1 初始化 Optimizer
初始化优化器只需要将模型的可学习参数(params)和超参数(defaults)分别传入优化器的构造函数,下面是Optimizer的初始化函数核心代码:
1.2.2 add_param_group
该方法在初始化函数中用到,主要用来向 self.param_groups添加不同分组的模型参数
def add_param_group(self, param_group):r"""Add a param group to the :class:`Optimizer` s `param_groups`.This can be useful when fine tuning a pre-trained network as frozen layers can be madetrainable and added to the :class:`Optimizer` as training progresses.Arguments:param_group (dict): Specifies what Tensors should be optimized along with groupspecific optimization options."""assert isinstance(param_group, dict), "param group must be a dict"params = param_group['params']if isinstance(params, torch.Tensor):param_group['params'] = [params]elif isinstance(params, set):raise TypeError('optimizer parameters need to be organized in ordered collections, but ''the ordering of tensors in sets will change between runs. Please use a list instead.')else:param_group['params'] = list(params)for param in param_group['params']:if not isinstance(param, torch.Tensor):raise TypeError("optimizer can only optimize Tensors, ""but one of the params is " + torch.typename(param))if not param.is_leaf:raise ValueError("can't optimize a non-leaf Tensor")# 利用默认参数给所有组设置统一的超参for name, default in self.defaults.items():if default is required and name not in param_group:raise ValueError("parameter group didn't specify a value of required optimization parameter "+name)else:param_group.setdefault(name, default)params = param_group['params']if len(params) != len(set(params)):warnings.warn("optimizer contains a parameter group with duplicate parameters; ""in future, this will cause an error; ""see github.com/pytorch/pytorch/issues/40967 for more information", stacklevel=3)param_set = set()for group in self.param_groups:param_set.update(set(group['params']))if not param_set.isdisjoint(set(param_group['params'])):raise ValueError("some parameters appear in more than one parameter group")self.param_groups.append(param_group)
利用 add_param_group 函数功能,可以对模型不同的可学习参数组设定不同的超参数,初始化优化器可传入元素是 dict 的 list,每个 dict 中的 key 是 params 或者其他超参数的名字如 lr,下面是一个实用的例子:对模型的fc层参数设置不同的学习率
from torch.optim import SGDfrom torch import nnclass DummyModel(nn.Module):def __init__(self, class_num=10):super(DummyModel, self).__init__()self.base = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.ReLU(),)self.gap = nn.AdaptiveAvgPool2d(1)self.fc = nn.Linear(128, class_num)def forward(self, x):x = self.base(x)x = self.gap(x)x = x.view(x.shape[0], -1)x = self.fc(x)return xmodel = DummyModel().cuda()optimizer = SGD([{'params': model.base.parameters()},{'params': model.fc.parameters(), 'lr': 1e-3} # 对 fc的参数设置不同的学习率], lr=1e-2, momentum=0.9)
1.2.3 step
此方法主要完成一次模型参数的更新
- 基类 Optimizer 定义了 step 方法接口,如下所示
def step(self, closure):r"""Performs a single optimization step (parameter update).Arguments:closure (callable): A closure that reevaluates the model andreturns the loss. Optional for most optimizers... note::Unless otherwise specified, this function should not modify the``.grad`` field of the parameters."""raise NotImplementedError
- 子类如 SGD 需要实现 step 方法,如下所示:
@torch.no_grad()def step(self, closure=None):"""Performs a single optimization step.Arguments:closure (callable, optional): A closure that reevaluates the modeland returns the loss."""loss = Noneif closure is not None:with torch.enable_grad():loss = closure()for group in self.param_groups:weight_decay = group['weight_decay']momentum = group['momentum']dampening = group['dampening']nesterov = group['nesterov']for p in group['params']:if p.grad is None:continued_p = p.gradif weight_decay != 0:d_p = d_p.add(p, alpha=weight_decay)if momentum != 0:param_state = self.state[p]if 'momentum_buffer' not in param_state:buf = param_state['momentum_buffer'] = torch.clone(d_p).detach()else:buf = param_state['momentum_buffer']buf.mul_(momentum).add_(d_p, alpha=1 - dampening)if nesterov:d_p = d_p.add(buf, alpha=momentum)else:d_p = bufp.add_(d_p, alpha=-group['lr'])return loss
- step 方法可传入闭包函数 closure,主要目的是为了实现如Conjugate Gradient和LBFGS等优化算法,这些算法需要对模型进行多次评估
- Python 中闭包概念:在一个内部函数中,对外部作用域的变量进行引用(并且一般外部函数的返回值为内部函数),那么内部函数就被认为是闭包
下面是 closure 的简单示例:
from torch.nn import CrossEntropyLossdummy_model = DummyModel().cuda()optimizer = SGD(dummy_model.parameters(), lr=1e-2, momentum=0.9, weight_decay=1e-4)# 定义lossloss_fn = CrossEntropyLoss()# 定义数据batch_size = 2data = torch.randn(64, 3, 64, 128).cuda() # 制造假数据shape=64 * 3 * 64 * 128data_label = torch.randint(0, 10, size=(64,), dtype=torch.long).cuda() # 制造假的labelfor batch_index in range(10):batch_data = data[batch_index*batch_size: batch_index*batch_size + batch_size]batch_label = data_label[batch_index*batch_size: batch_index*batch_size + batch_size]def closure():optimizer.zero_grad() # 清空梯度output = dummy_model(batch_data) # forwardloss = loss_fn(output, batch_label) # 计算lossloss.backward() # backwardprint('No.{: 2d} loss: {:.6f}'.format(batch_index, loss.item()))return lossoptimizer.step(closure=closure) # 更新参数
1.2.4 zero_grad
- 在反向传播计算梯度之前对上一次迭代时记录的梯度清零,参数set_to_none 设置为 True 时会直接将参数梯度设置为 None,从而减小内存使用, 但通常情况下不建议设置这个参数,因为梯度设置为 None 和 0 在 PyTorch 中处理逻辑会不一样。
def zero_grad(self, set_to_none: bool = False):r"""Sets the gradients of all optimized :class:`torch.Tensor` s to zero.Arguments:set_to_none (bool): instead of setting to zero, set the grads to None.This is will in general have lower memory footprint, and can modestly improve performance.However, it changes certain behaviors. For example:1. When the user tries to access a gradient and perform manual ops on it,a None attribute or a Tensor full of 0s will behave differently.2. If the user requests ``zero_grad(set_to_none=True)`` followed by a backward pass, ``.grad``sare guaranteed to be None for params that did not receive a gradient.3. ``torch.optim`` optimizers have a different behavior if the gradient is 0 or None(in one case it does the step with a gradient of 0 and in the other it skipsthe step altogether)."""for group in self.param_groups:for p in group['params']:if p.grad is not None:if set_to_none:p.grad = Noneelse:if p.grad.grad_fn is not None:p.grad.detach_()else:p.grad.requires_grad_(False)p.grad.zero_()
1.2.5 state_dict() 和 load_state_dict
这两个方法实现序列化和反序列化功能。
- state_dict(): 将优化器管理的参数和其状态信息以 dict 形式返回
- load_state_dict(state_dict): 加载之前返回的 dict,更新参数和其状态
- 两个方法可用来实现模型训练中断后继续训练功能
def state_dict(self):r"""Returns the state of the optimizer as a :class:`dict`.It contains two entries:* state - a dict holding current optimization state. Its contentdiffers between optimizer classes.* param_groups - a dict containing all parameter groups"""# Save order indices instead of Tensorsparam_mappings = {}start_index = 0def pack_group(group):nonlocal start_indexpacked = {k: v for k, v in group.items() if k != 'params'}param_mappings.update({id(p): i for i, p in enumerate(group['params'], start_index)if id(p) not in param_mappings})packed['params'] = [param_mappings[id(p)] for p in group['params']]start_index += len(packed['params'])return packedparam_groups = [pack_group(g) for g in self.param_groups]# Remap state to use order indices as keyspacked_state = {(param_mappings[id(k)] if isinstance(k, torch.Tensor) else k): vfor k, v in self.state.items()}return {'state': packed_state,'param_groups': param_groups,}
1.3 常见优化器简介
1.3.1 SGD(params, lr, momentum=0, dampening=0, weight_decay=0, nesterov=False)
实现带momentum和dampening的 SGD,公式如下:

1.3.2 Adagrad(params, lr=0.01, lr_decay=0, weight_decay=0, initial_accumulator_value=0, eps=1e-10)
自适应学习率,考虑历史所有梯度信息, 公式如下:

1.3.3 RMSprop(params, lr=0.01, alpha=0.99, eps=1e-08, weight_decay=0, momentum=0, centered=False)
加权考虑历史梯度和当前梯度,历史梯度系数是  ,当前梯度系数是
,当前梯度系数是 

1.3.4 Adam(params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=0, amsgrad=False)
实现了自适应学习率有优化器, Adam 是 Momentum 和 RMSprop 的结合 主要超参数有  ,
,  ,eps。 公式如下:
,eps。 公式如下:
其中,  、
、 分别是对梯度的一阶矩估计和二阶矩估计,可以看作对期望 E[gt]、E[g_t^2] 的近似;
分别是对梯度的一阶矩估计和二阶矩估计,可以看作对期望 E[gt]、E[g_t^2] 的近似;  ,
,  是校正,这样可以近似为对期望的无偏估计
是校正,这样可以近似为对期望的无偏估计
2 学习率调节器 lr_scheduler
有了优化器,还需要根据 epoch 来调整学习率,lr_schedluer提供了在训练模型时学习率的调整策略。
目前 PyTorch 提供了如下学习率调整策略:
- StepLR: 等间隔调整策略
- MultiStepLR: 多阶段调整策略
- ExponentialLR: 指数衰减调整策略
- ReduceLROnPlateau: 自适应调整策略
- CyclicLR: 循环调整策略
- OneCycleLR: 单循环调整策略
- CosineAnnealingLR: 余弦退火调整策略
- CosineAnnealingWarmRestarts: 带预热启动的余弦退火调整策略
- LambdaLR: 自定义函数调整策略
- MultiplicativeLR: 乘法调整策略
学习率调整策略可粗略分为以下三大类:
有序调整策略:
- StepLR
- MultiStepLR
- ExponentialLR
- CyclicLR
- OneCycleLR
- CosineAnnealingLR
- CosineAnnealingWarmRestarts
自适应调整策略:
- ReduceLROnPlateau
自定义调整策略:
- LambdaLR
- MultiplicativeLR
2.1 基类: _LRScheduler
学习率调整类主要的逻辑功能就是每个 epoch 计算参数组的学习率,更新 optimizer对应参数组中的lr值,从而应用在optimizer里可学习参数的梯度更新。所有的学习率调整策略类的父类是torch.optim.lr_scheduler._LRScheduler,基类 _LRScheduler 定义了如下方法:
- step(epoch=None): 子类公用
- get_lr(): 子类需要实现
- get_last_lr(): 子类公用
- print_lr(is_verbose, group, lr, epoch=None): 显示 lr 调整信息
- state_dict(): 子类可能会重写
- load_state_dict(state_dict): 子类可能会重写
2.1.1 初始化
基类的初始化函数可传入两个参数, 第一是optimizer就是之前我们讲过的优化器的实例,第二个参数lastepoch是最后一次 epoch 的 index,默认值是 -1,代表初次训练模型,此时会对optimizer里的各参数组设置初始学习率 initiallr。若last_epoch传入值大于 -1,则代表从某个 epoch 开始继续上次训练,此时要求optimizer的参数组中有initial_lr初始学习率信息。初始化函数内部的 with_counter 函数主要是为了确保lr_scheduler.step()是在optimizer.step()之后调用的 (PyTorch=1.1 发生变化). 注意在__init函数最后一步调用了self.step(),即_LRScheduler在初始化时已经调用过一次step()方法。
class _LRScheduler(object):def __init__(self, optimizer, last_epoch=-1, verbose=False):# Attach optimizerif not isinstance(optimizer, Optimizer):raise TypeError('{} is not an Optimizer'.format(type(optimizer).__name__))self.optimizer = optimizer# Initialize epoch and base learning ratesif last_epoch == -1:for group in optimizer.param_groups:group.setdefault('initial_lr', group['lr'])else:for i, group in enumerate(optimizer.param_groups):if 'initial_lr' not in group:raise KeyError("param 'initial_lr' is not specified ""in param_groups[{}] when resuming an optimizer".format(i))self.base_lrs = list(map(lambda group: group['initial_lr'], optimizer.param_groups))self.last_epoch = last_epoch# Following https://github.com/pytorch/pytorch/issues/20124# We would like to ensure that `lr_scheduler.step()` is called after# `optimizer.step()`def with_counter(method):if getattr(method, '_with_counter', False):# `optimizer.step()` has already been replaced, return.return method# Keep a weak reference to the optimizer instance to prevent# cyclic references.instance_ref = weakref.ref(method.__self__)# Get the unbound method for the same purpose.func = method.__func__cls = instance_ref().__class__del method@wraps(func)def wrapper(*args, **kwargs):instance = instance_ref()instance._step_count += 1wrapped = func.__get__(instance, cls)return wrapped(*args, **kwargs)# Note that the returned function here is no longer a bound method,# so attributes like `__func__` and `__self__` no longer exist.wrapper._with_counter = Truereturn wrapperself.optimizer.step = with_counter(self.optimizer.step)self.optimizer._step_count = 0self._step_count = 0self.verbose = verboseself.step()
2.1.3 get_last_lr、get_lr和print_lr
- get_last_lr()方法比较简单,就是step()方法调用后,记录的最后一次 optimizer各参数组里更新后的学习率信息
- get_lr() 方法是抽象方法,定义了更新学习率策略的接口,不同子类继承后会有不同的实现.其返回值是[lr1, lr2, …]结构
- print_lr(is_verbose, group, lr, epoch=None)): 该方法提供了显示 lr 调整信息的功能
def get_last_lr(self):""" Return last computed learning rate by current scheduler."""return self._last_lrdef get_lr(self):# Compute learning rate using chainable form of the schedulerraise NotImplementedErrordef print_lr(self, is_verbose, group, lr, epoch=None):"""Display the current learning rate."""if is_verbose:if epoch is None:print('Adjusting learning rate'' of group {} to {:.4e}.'.format(group, lr))else:print('Epoch {:5d}: adjusting learning rate'' of group {} to {:.4e}.'.format(epoch, group, lr))
2.1.4 state_dict 和 load_state_dict
这两个方法和Optimizer里的方法功能是一样的,就是为了保存和重新加载状态信息,需要注意的是,这里不会重复记录self.optimizer属性的状态信息,因为 Optimizer 有自己实现的对应方法。
- state_dict(): 以字典 dict 形式返回当前实例除 self.optimizer 之外的其他所有属性信息
- load_state_dict(state_dict): 重新载入之前保存的状态信息
def state_dict(self):"""Returns the state of the scheduler as a :class:`dict`.It contains an entry for every variable in self.__dict__ whichis not the optimizer."""return {key: value for key, value in self.__dict__.items() if key != 'optimizer'}def load_state_dict(self, state_dict):"""Loads the schedulers state.Arguments:state_dict (dict): scheduler state. Should be an object returnedfrom a call to :meth:`state_dict`."""self.__dict__.update(state_dict)
2.2 学习率调整策略示例
2.2.1 StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1, verbose=False)
StepLR是根据 epoch 的等间隔学习率调整策略,实现了get_lr()方法。初始化函数须传入优化器,epoch 间隔 step_size,gamma是学习率的衰减系数,默认是 0.1。
class StepLR(_LRScheduler):def __init__(self, optimizer, step_size, gamma=0.1, last_epoch=-1, verbose=False):self.step_size = step_sizeself.gamma = gammasuper(StepLR, self).__init__(optimizer, last_epoch, verbose)def get_lr(self):if not self._get_lr_called_within_step:warnings.warn("To get the last learning rate computed by the scheduler, ""please use `get_last_lr()`.", UserWarning)if (self.last_epoch == 0) or (self.last_epoch % self.step_size != 0):return [group['lr'] for group in self.optimizer.param_groups]return [group['lr'] * self.gammafor group in self.optimizer.param_groups]def _get_closed_form_lr(self):return [base_lr * self.gamma ** (self.last_epoch // self.step_size)for base_lr in self.base_lrs]## 可视化学习率from torch.optim import lr_schedulerfrom matplotlib import pyplot as plt%matplotlib inlinedef create_optimizer():return SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=1e-4)def plot_lr(scheduler, title='', labels=['base'], nrof_epoch=100):lr_li = [[] for _ in range(len(labels))]epoch_li = list(range(nrof_epoch))for epoch in epoch_li:scheduler.step() # 调用step()方法,计算和更新optimizer管理的参数基于当前epoch的学习率lr = scheduler.get_last_lr() # 获取当前epoch的学习率for i in range(len(labels)):lr_li[i].append(lr[i])for lr, label in zip(lr_li, labels):plt.plot(epoch_li, lr, label=label)plt.grid()plt.xlabel('epoch')plt.ylabel('lr')plt.title(title)plt.legend()plt.show()## StepLR 可视化学习率optimizer = create_optimizer()scheduler = lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)plot_lr(scheduler, title='StepLR')
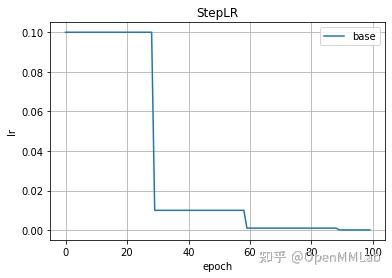
2.2.2 MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1, verbose=False)
多阶段学习率调整策略,参数 milestones 是包含多个学习率调整点列表
optimizer = create_optimizer()scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[20, 35, 45], gamma=0.5)plot_lr(scheduler, title='MultiStepLR')
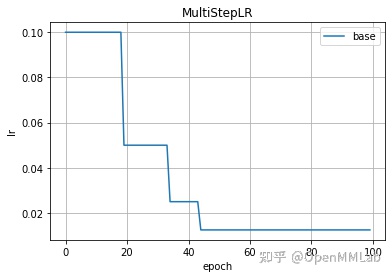
2.2.3 MultiplicativeLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)
乘法调整策略实现了学习率的衰减系数 gamma可变,即在每个调整节点,可对各参数组的学习率乘上一个不同的衰减率gamma,初始化函数中lr_lambda参数可以是一个lambda函数,也可是lambda函数列表,每个lambda函数输入是 epoch,输出是gamma。
optimizer = SGD([{'params': model.base.parameters()},{'params': model.fc.parameters(), 'lr': 0.05} # 对 fc的参数设置不同的学习率], lr=0.1, momentum=0.9)lambda_base = lambda epoch: 0.5 if epoch % 10 == 0 else 1lambda_fc = lambda epoch: 0.8 if epoch % 10 == 0 else 1scheduler = lr_scheduler.MultiplicativeLR(optimizer, [lambda_base, lambda_fc])plot_lr(scheduler, title='MultiplicativeLR', labels=['base', 'fc'])
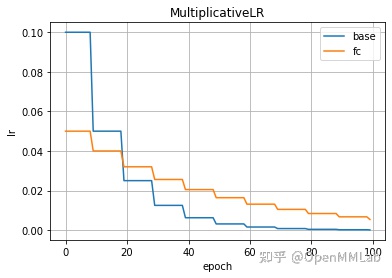
2.2.4 LambdaLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)
该策略可传入自定义的lambda函数, lambda函数参数为epoch,返回值为学习率。
# LamdbdaLR调用示例def lambda_foo(epoch):if epoch < 10:return (epoch+1) * 1e-3elif epoch < 40:return 1e-2else:return 1e-3optimizer = create_optimizer()scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda_foo)plot_lr(scheduler, title='LambdaLR')
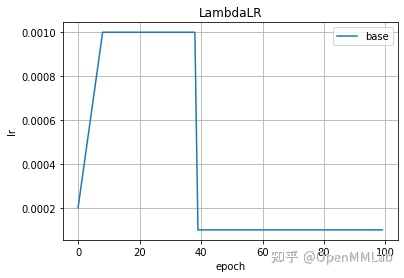
2.2.5 ExponentialLR(optimizer, gamma, last_epoch=-1, verbose=False)
指数衰减学习率调整策略
optimizer = create_optimizer()scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.9)plot_lr(scheduler, title='ExponentialLR')
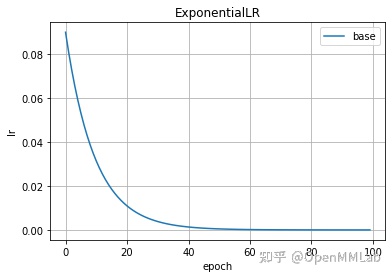
2.2.6 CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1, verbose=False)
余弦退火调整策略,T_max是最大迭代次数, eta_min是最小学习率值,其公式如下,eta_max为初始学习率,T_cur 是自重新启动后的 epoch 数

optimizer = create_optimizer()scheduler = lr_scheduler.CosineAnnealingLR(optimizer, 10, 1e-5)plot_lr(scheduler, title='CosineAnnealingLR')
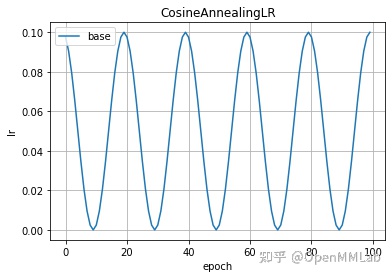
2.2.7 CosineAnnealingWarmRestarts(optimizer, T_0, T_mult=1, eta_min=0, last_epoch=-1, verbose=False)
在 SGDR(Stochastic Gradient Descent with Warm Restarts)中提出:
- T_0: 第一次启动时的迭代数
- T_mult: 启动后,改变周期 T 的因子
- eta_min: 学习率下限
optimizer = create_optimizer()scheduler = lr_scheduler.CosineAnnealingWarmRestarts(optimizer, 10, 2)plot_lr(scheduler, title='CosineAnnealingWarmRestarts')
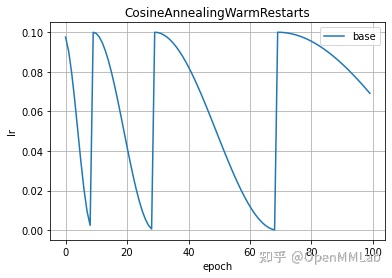
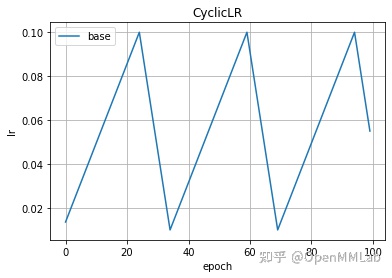
2.2.8 CyclicLR(optimizer, base_lr, max_lr, step_size_up=2000, step_size_down=None, mode=’triangular’, …)
类似三角波形状的学习率调整策略,以下是几个重要初始化参数:
- base_lr: 基准学习率,也是最小的学习率
- max_lr: 学习率上限
- step_size_up: 一个周期里上升阶段 epoch 数
- step_size_down: 一个周期里下降阶段 epoch 数
optimizer = create_optimizer()scheduler = lr_scheduler.CyclicLR(optimizer, 0.01, 0.1, step_size_up=25, step_size_down=10)plot_lr(scheduler, title='CyclicLR')
2.2.9 OneCycleLR(optimizer, max_lr, total_steps=None, epochs=None, steps_per_epoch=None, pct_start=0.3,…)
只有 1 次循环的学习率调整策略
- max_lr: float/list, 学习率调整的上限
- total_steps: int 循环中的总步数
optimizer = create_optimizer()scheduler = lr_scheduler.OneCycleLR(optimizer, 0.1, total_steps=100)plot_lr(scheduler, title='OneCycleLR')
2.2.10 ReduceLROnPlateau(optimizer, mode=’min’, factor=0.1, patience=10, threshold=0.0001, threshold_mode=’rel’, …)
自适应学习率调整策略,比如只有当 loss 在几个 epoch 里都不发生下降时,才调整学习率。注意在调用时,需要在其 step() 方法中传入对应的参考变量,例如: scheduler.step(val_loss)
- mode: 评价模型训练质量的模式, 传入值为min 或max
- factor: 学习率衰减因子, 类似gamma
- patience: 控制何时调整学习率
示例:
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)scheduler = ReduceLROnPlateau(optimizer, 'min')for epoch in range(100):train(...)val_loss = validate(...)scheduler.step(val_loss)
3 swa_utils里SWA相关类和函数
该模块中只有 2 个类和一个函数:
- AveragedModel: 实现 SWA 算法的权重平均模型
- SWALR: 与AverageModel配合使用的学习率调整策略
- update_bn: 更新模型中的 bn
3.0 SWA 简介
随机权重平均(SWA)是一种优化算法,在SWA 论文的结果证明,取 SGD 轨迹的多点简单平均值,以一个周期或者不变的学习率,会比传统训练有更好的泛化效果。论文的结果同样了证明了,随机权重平均 (SWA) 可以找到更广的最优值域。
3.1 AveragedModel
- 该类实现 SWA 算法的权重平均模型,初始化时传入模型 model 和参数平均化函数 avg_fn,然后在初始化函数中对 model的参数进行深拷贝, 注册模型计数器。
- 在update_parameters(self, model)方法中再次传入模型后,根据参数avg_fn对模型参数进行平均后更新 swa 模型参数。
class AveragedModel(Module):def __init__(self, model, device=None, avg_fn=None):super(AveragedModel, self).__init__()self.module = deepcopy(model)if device is not None:self.module = self.module.to(device)self.register_buffer('n_averaged',torch.tensor(0, dtype=torch.long, device=device))# 默认提供了avg_fn,你可以指定if avg_fn is None:def avg_fn(averaged_model_parameter, model_parameter, num_averaged):return averaged_model_parameter + \(model_parameter - averaged_model_parameter) / (num_averaged + 1)self.avg_fn = avg_fndef forward(self, *args, **kwargs):return self.module(*args, **kwargs)def update_parameters(self, model):for p_swa, p_model in zip(self.parameters(), model.parameters()):device = p_swa.devicep_model_ = p_model.detach().to(device)if self.n_averaged == 0:p_swa.detach().copy_(p_model_)else:p_swa.detach().copy_(self.avg_fn(p_swa.detach(), p_model_,self.n_averaged.to(device)))self.n_averaged += 1
3.2 update_bn
该函数主要是通过传入的某个训练时刻的模型model 和 dataloader,来允许 swa 模型计算和更新 bn
def update_bn(loader, model, device=None):momenta = {}for module in model.modules():if isinstance(module, torch.nn.modules.batchnorm._BatchNorm):module.running_mean = torch.zeros_like(module.running_mean)module.running_var = torch.ones_like(module.running_var)momenta[module] = module.momentumif not momenta:returnwas_training = model.trainingmodel.train()for module in momenta.keys():module.momentum = Nonemodule.num_batches_tracked *= 0# 重新算BN全局均值和方差for input in loader:if isinstance(input, (list, tuple)):input = input[0]if device is not None:input = input.to(device)model(input)for bn_module in momenta.keys():bn_module.momentum = momenta[bn_module]model.train(was_training)
Example:
loader, model = ...torch.optim.swa_utils.update_bn(loader, model)
3.3 SWALR
SWALR类继承_LRScheduler基类,实现了供 swa 模型的学习率调整策略
在此就只放出其使用示例:
Example:>>> loader, optimizer, model = ...>>> swa_model = torch.optim.swa_utils.AveragedModel(model)>>> lr_lambda = lambda epoch: 0.9>>> scheduler = torch.optim.lr_scheduler.MultiplicativeLR(optimizer,>>> lr_lambda=lr_lambda)>>> swa_scheduler = torch.optim.swa_utils.SWALR(optimizer,>>> anneal_strategy="linear", anneal_epochs=20, swa_lr=0.05)>>> swa_start = 160>>> for i in range(300):>>> for input, target in loader:>>> optimizer.zero_grad()>>> loss_fn(model(input), target).backward()>>> optimizer.step()>>> if i > swa_start:>>> swa_scheduler.step()>>> else:>>> scheduler.step()>>> # Update bn statistics for the swa_model at the end>>> torch.optim.swa_utils.update_bn(loader, swa_model)

若有收获,就点个赞吧
0 人点赞
