Attention is all you need 把Self-Attention发扬光大。
Abstract

1 Introduction
2 Background
3 Model Architecture
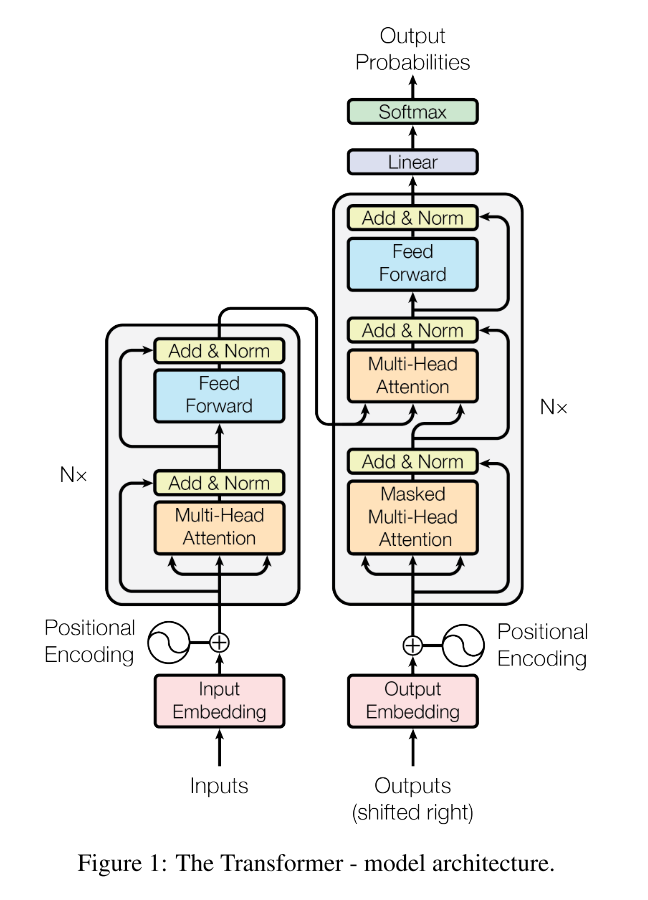
3.1 Encoder and Decoder Stacks
3.2 Attention
3.2.1 Scaled Dot-Product Attention
3.2.2 Multi-Head Attention
3.2.3 Application of Attention in our Model
3.3 Position-wise Feed-Forward Networks
3.4 Embeddings and Softmax
3.5 Positional Encoding
4 Why Self-Attention
5 Training
5.1 Training Data and Batching
5.2 Hardware and Schedule
5.3 Optimizer
5.4 Regularization
6. Results
6.1 Machine Translation
6.2 Model Variation
6.3 English Constituency
7. Conclusion
8. 其他
心理学概念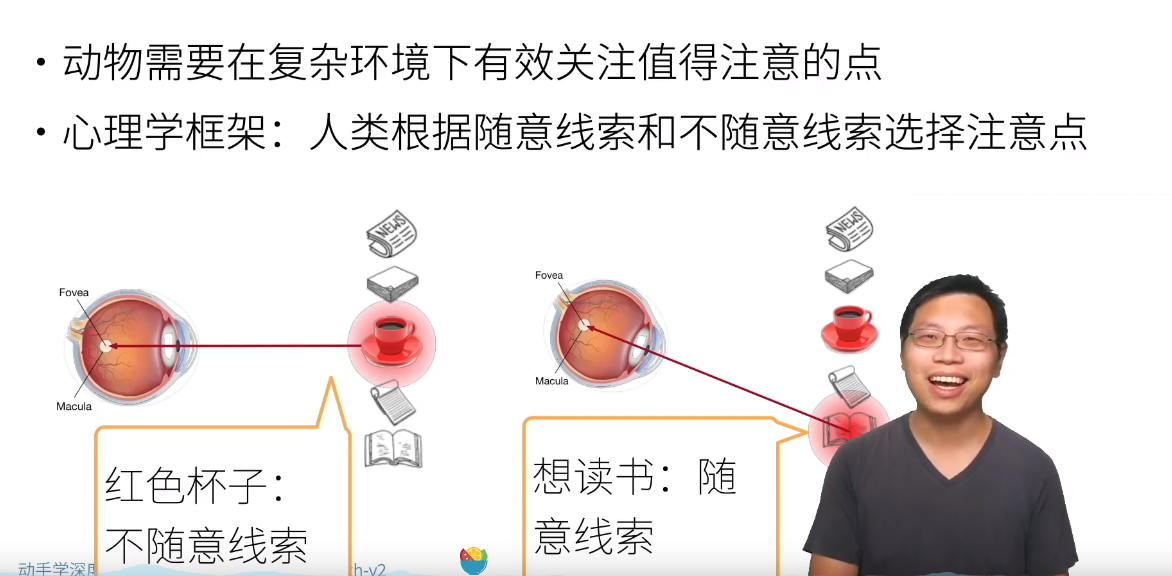
- 卷积、全连接、池化层都只考虑不随意线索
- 注意力机制则显示的考虑随意线索
- 随意线索被称之为查询(query)
- 每个输入是一个值(value)和不随意线索(key)的对
- 通过注意力池化层来有偏向性的选择选择某些输入
非参注意力池化层
- 给定数据(xi,yi),i = 1,….,n
- 平均池化是最简单的方案:

- 更好的方案是60年代提出来的Nadaraya-Watson核回归

- 使用高斯核
 ,那么
,那么
参数化的注意力机制

参考
个人mendeley地址
强烈推荐!台大李宏毅自注意力机制和Transformer详解!
李沐 注意力机制 【动手学习深度学习】

若有收获,就点个赞吧
0 人点赞
