0 摘要
轻松掌握 MMDetection 训练测试流程(二)对整个目标检测框架的训练以及测试整体流程进行的详细分析,旨在帮助大家对 MMDetection 框架进行较为全面的理解。在此基础上,本文主要针对 Model 模块中最为复杂的 Head 部分进行详解,主要内容包括:
- Head 模块整体概述
- Head 模块构建流程
- Head 模块源码分析
1 Head 模块整体概述
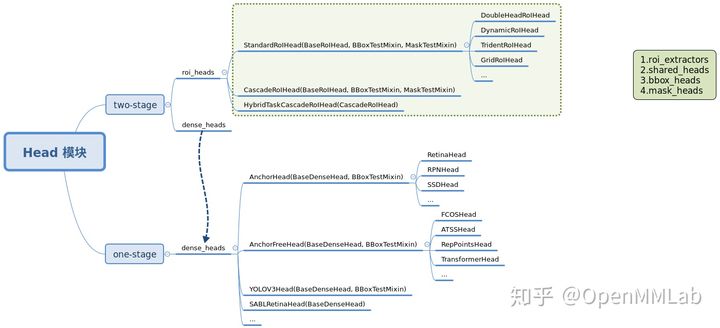
目前 MMDetection 中 Head 模块主要是按照 stage 来划分,主要包括两个 package: dense_heads 和 roi_heads , 分别对应 two-stage 算法中的第一和第二个 stage 模块,如果是 one-stage 算法则仅仅有 dense_heads 而已。
(1) dense_heads dense_heads 部分主要是按照 anchor-based 和 anchor-free 来划分,对应的类是 AnchorHead 和 AnchorFreeHead, 这两个类主要区别是 AnchorHead 会额外需要 anchor_generator 配置,用于生成默认 anchor。
同时可以看到有些类并没有直接继承这两个基类,例如 YOLOV3Head。原因是在该类中大部分函数处理逻辑都需要复写,为了简单就直接继承了 BaseDenseHead,而对于 SABLRetinaHead 而言,由于 SABL 是类似 anchor-based 和 anchor-free 混合的算法,故直接继承 BaseDenseHead 是最合适的做法。用户如果要进行扩展开发,可以依据开发便捷度自由选择最合适的基类进行继承。
(2) roi_heads roi_heads 部分主要是按照第二阶段内部的 stage 个数来划分,经典的 Faster R-CNN 采用的是 StandardRoIHead,表示进行一次回归即可,而对于 Cascade R-CNN,其第二阶段内部也包括多个 stage 回归阶段,实现了 CascadeRoIHead,即可以构建任意次数的分类回归结果。
总结来说,每个 Head 内部都可能包括:
- RoI 特征提取器 roi_extractor
- 共享模块 shared_heads
- bbox 分类回归模块 bbox_heads
- mask 预测模块 mask_heads
2 Head 模块构建流程
为了方便理解,首先需要回顾下 MMDetection 训练和测试流程,然后再对每个 Head 模块进行深入分析。
2.1 MMDetection 训练和测试流程
(1) 训练流程
对应 two-stage 而言,具体如下所示:
#============= mmdet/models/detectors/two_stage.py/TwoStageDetector ============def forward_train(...):# 先进行 backbone+neck 的特征提取x = self.extract_feat(img)losses = dict()# RPN forward and lossif self.with_rpn:# 训练 RPNproposal_cfg = self.train_cfg.get('rpn_proposal',self.test_cfg.rpn)# 主要是调用 rpn_head 内部的 forward_train 方法rpn_losses, proposal_list = self.rpn_head.forward_train(x,...)losses.update(rpn_losses)else:proposal_list = proposals# 第二阶段,主要是调用 roi_head 内部的 forward_train 方法roi_losses = self.roi_head.forward_train(x, ...)losses.update(roi_losses)return losses
Head 模块核心是调用 self.rpn_head.forward_train 和 self.roi_head.forward_train 函数,输出 losses 和其他相关数据。
对于 one-stage 而言,具体如下所示:
#============= mmdet/models/detectors/single_stage.py/SingleStageDetector ============def forward_train(...):super(SingleStageDetector, self).forward_train(img, img_metas)# 先进行 backbone+neck 的特征提取x = self.extract_feat(img)# 主要是调用 bbox_head 内部的 forward_train 方法losses = self.bbox_head.forward_train(x, ...)return losses
这个比 two-stage head 模块简单,因为其只有第一个 stage,对应的函数是 self.bbox_head.forward_train。
(2) 测试流程
- 调用 MMDataParallel 或 MMDistributedDataParallel 中的 forward 方法
- 调用 base.py 中的 forward 方法
- 调用 base.py 中的 self.forward_test 方法
- 如果是单尺度测试,则会调用 TwoStageDetector 或 SingleStageDetector 中的 simple_test 方法,如果是多尺度测试,则调用 aug_test 方法
- 最终调用的是每个具体 Head 模块的 simple_test 或者 aug_test 方法(one-stage 和 two-stage 的 head 调用逻辑有些区别)
可以看出在测试阶段,主要是调用了 Head 模块自身的 simple_test 或 aug_test 方法。
2.2 dense_heads 模块训练和测试流程
(1) 训练流程
dense_heads 训练流程最外层函数是 forward_train, 其实现是在mmdet/models/dense_heads/base_dense_head.py/BaseDenseHead 中,如下所示:
def forward_train(self,x,img_metas,gt_bboxes,gt_labels=None,gt_bboxes_ignore=None,proposal_cfg=None,**kwargs):# 调用各个子类实现的 forward 方法outs = self(x)if gt_labels is None:loss_inputs = outs + (gt_bboxes, img_metas)else:loss_inputs = outs + (gt_bboxes, gt_labels, img_metas)# 调用各个子类实现的 loss 计算方法losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)if proposal_cfg is None:return losseselse:# two-stage 算法还需要返回 proposalproposal_list = self.get_bboxes(*outs, img_metas, cfg=proposal_cfg)return losses, proposal_list
每个算法的 Head 子类一般不会重写上述方法,但是每个 Head 子类都会重写 forward 和 loss 方法,其中 forward 方法用于运行 head 网络部分输出分类回归分支的特征图,而 loss 方法接收 forward 输出,并且结合 label 计算 loss。
(1-1) BaseDenseHead
BaseDenseHead 基类过于简单,对于 anchor-based 和 anchor-free 算法又进一步进行了继承,得到 AnchorHead 或者 AnchorFreeHead 类。在目前的各类算法实现中,绝大部分子类都是继承自 AnchorHead 或者 AnchorFreeHead,其提供了一些相关的默认操作,如果直接继承 BaseDenseHead 则子类需要重写大部分算法逻辑。
(1-2) AnchorHead
首先分析 AnchorHead,其主要是封装了 anchor 生成过程。下面对 forward 和 loss 函数进行分析
# BBoxTestMixin 是多尺度测试时候调用class AnchorHead(BaseDenseHead, BBoxTestMixin):# feats 是 backbone+neck 输出的多个尺度图def forward(self, feats):# 对每张特征图单独计算预测输出return multi_apply(self.forward_single, feats)# head 模块分类回归分支输出def forward_single(self, x):cls_score = self.conv_cls(x)bbox_pred = self.conv_reg(x)return cls_score, bbox_pred
forward 函数比较简单,就是对多尺度特征图中每个特征图分别计算分类和回归输出即可,主要复杂度在 loss 函数中,其运行流程图如下所示:
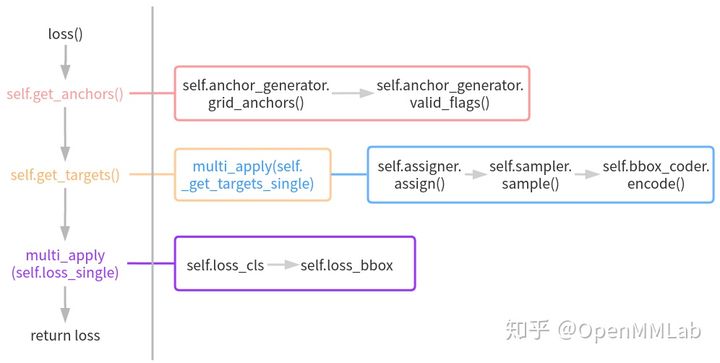
- 在 loss 函数中首先会调用 get_anchors 函数得到默认 anchor 列表。而 get_anchors 函数内部会先计算多尺度特征图上每个特征点位置的 anchor,然后再计算有效 anchor 标志(因为在组织 batch 时候有些图片会进行左上角 padding,这部分像素人为加的,不需要考虑 anchor)
- 然后基于 anchor、gt bbox 以及其他必备信息调用 get_targets 函数计算每个预测分支对应的 target。get_targets 函数内部会调用 multi_apply(_get_targets_single) 函数对每张图片单独计算 target,而 _get_targets_single 函数实现的功能比较多,包括:bbox assigner、bbox sampler 和 bbox encoder 三个关键环节
- 在得到 targets 后,调用 loss_single 函数计算每个输出尺度的 loss 值,最终返回各个分支的 loss
(1-3) AnchorFreeHead
AnchorFreeHead 逻辑比 AnchorHead 简单很多,主要是因为 anchor-free 类算法比 anchor-based 算法更加灵活多变,而且少了复杂的 anchor 生成过程,其 forward 方法实现和 AnchorHead 完全相同,而 loss 方法没有实现,其子类必须实现。
(2) 测试流程
前面说过在测试流程中,最终会调用 Head 模块的 simple_test 或 aug_test 方法分别进行单尺度和多尺度测试,涉及到具体代码层面,one-stage 和 two-stage 调用函数有区别,但是最终调用的依然是 Head 模块的 get_bboxes 方法。
(2-1) AnchorHead
在单尺度测试模式下,对于 one-stage 而言,是直接调用 self.bbox_head.get_bboxes 方法,如果是 AnchorHead,其流程是:
- 遍历每个特征尺度输出分支,利用 nms_pre 配置参数对该层预测结果按照 scores 值进行从大到小进行 topk 截取,保留 scores 最高的前 nms_pre 的预测结果
- 对保留的预测结果进行 bbox 解码还原操作
- 还原到最原始图片尺度
- 如果需要进行 nms,则对所有分支预测保留结果进行统一 nms 即可,否则直接属于多尺度预测结果
对于 two-stage 而言,其第一阶段 Head 推理是直接调用了 simple_test_rpn 方法,该方法内部最终也是调用了 AnchorHead 中的get_bboxes 方法。
# mmdet/models/dense_heads/rpn_test_mixin.py/RPNTestMixindef simple_test_rpn(self, x, img_metas):rpn_outs = self(x)proposal_list = self.get_bboxes(*rpn_outs, img_metas)return proposal_list
(2-2) AnchorFreeHead
AnchorFreeHead 比较灵活, get_bboxes 都是由具体算法子类实现。
def get_bboxes(self,cls_scores,bbox_preds,img_metas,cfg=None,rescale=None):raise NotImplementedError
(2-3) 多尺度测试
除了 RPN 算法的多尺度测试是在mmdet/models/dense_heads/rpn_test_mixin.py,其余 Head 多尺度测试都是在 mmdet/models/dense_heads/dense_test_mixins.py/BBoxTestMixin 中实现,其思路是对多尺度图片中每张图片单独运行 get_bboxes,然后还原到原图尺度,最后把多尺度图片预测结果合并进行统一 nms。
2.3 roi_heads 模块训练和测试流程
(1) 训练流程
训练流程最外层依然是调用 forward_train, 其核心代码如下所示:
def forward_train(self,x,img_metas,proposal_list,gt_bboxes,gt_labels,...):if self.with_bbox or self.with_mask:num_imgs = len(img_metas)sampling_results = []for i in range(num_imgs):# 对每张图片进行 bbox 正负样本属性分配assign_result = self.bbox_assigner.assign(proposal_list[i], ...)# 然后进行正负样本采样sampling_result = self.bbox_sampler.sample(assign_result,proposal_list[i],...)sampling_results.append(sampling_result)losses = dict()if self.with_bbox:# bbox 分支 forward,返回 lossbbox_results = self._bbox_forward_train(...)losses.update(bbox_results['loss_bbox'])if self.with_mask:# mask 分支 forward,返回 lossreturn lossesdef _bbox_forward_train(self, x, sampling_results, gt_bboxes, gt_labels,img_metas):rois = bbox2roi([res.bboxes for res in sampling_results])# forwardbbox_results = self._bbox_forward(x, rois)# 计算 targetbbox_targets = self.bbox_head.get_targets(...)# 计算 lossloss_bbox = self.bbox_head.loss(...)return ...def _bbox_forward(self, x, rois):# roi 提取bbox_feats = self.bbox_roi_extractor(x[:self.bbox_roi_extractor.num_inputs], rois)# bbox head 网络前向cls_score, bbox_pred = self.bbox_head(bbox_feats)return ...
从上述逻辑可以看出,StandardRoIHead 中 forward_train 函数仅仅是对内部的 bbox_head 相关函数进行调用,例如 get_targets 和 loss,本身 StandardRoIHead 类不做具体算法逻辑计算。
可以参考 Faster R-CNN 配置文件理解 StandardRoIHead 和 bbox_head 的关系:
roi_head=dict(type='StandardRoIHead',bbox_roi_extractor=dict(type='SingleRoIExtractor',roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),out_channels=256,featmap_strides=[4, 8, 16, 32]),bbox_head=dict(type='Shared2FCBBoxHead',in_channels=256,fc_out_channels=1024,roi_feat_size=7,num_classes=80,bbox_coder=dict(type='DeltaXYWHBBoxCoder',target_means=[0., 0., 0., 0.],target_stds=[0.1, 0.1, 0.2, 0.2]),reg_class_agnostic=False,loss_cls=dict(type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),loss_bbox=dict(type='L1Loss', loss_weight=1.0))))
StandardRoIHead 类包装了 bbox_roi_extractor 和 bbox_head 的实例,前者用于 RoI 特征提取,后者才是真正计算分类和回归的逻辑。在 bbox_head 中除了网络模型有些变换外,loss计算过程是非常类似的,其 get_targets 和 loss 计算过程都是封装在基类 mmdet/models/roi_heads/bbox_heads/bbox_head.py 中。
(2) 测试流程
测试流程是调用 Head 模块的 simple_test 和 aug_test 函数,单尺度测试 bbox 相关实现代码在 mmdet/models/roi_heads/test_mixins.py/BBoxTestMixin 的 simple_test_bboxes 函数中。
def simple_test_bboxes(self,x,...):rois = bbox2roi(proposals)# roi 提取+ forward,输出预测结果bbox_results = self._bbox_forward(x, rois)cls_score = bbox_results['cls_score']bbox_pred = bbox_results['bbox_pred']det_bboxes = []det_labels = []for i in range(len(proposals)):# 对预测结果进行解码输出 bbox 和对应 labeldet_bbox, det_label = self.bbox_head.get_bboxes(...)det_bboxes.append(det_bbox)det_labels.append(det_label)return det_bboxes, det_labels
实际上依然是调用了 Head 模块内部的 get_bboxes 函数,处理逻辑和 dense_head 差不多( 解码+还原尺度+ nms)。
3 总结
本文是 MMDetection 流程解读三部曲的最终章,重点是对最复杂的 Head 模块进行深入详细解读。通过三篇解读,读者可以了解到:

若有收获,就点个赞吧
0 人点赞
