0 前言
在解读完轻松掌握 MMDetection 训练和测试流程的相关系列文章后,相信大家对 MMDetection 框架训练和测试流程以及各个组件的内部抽象实现有了一定了解。本系列文章则从框架中已经实现的一些常用算法入手,通过对这些算法进行深度解析,使读者能够对 MMDetection 有进一步深入理解。本系列文章希望达到的目的是:
- 通过对常用算法进行深度解析,使读者能够对该系列算法及其改进算法的实现有非常透彻的理解
- 通过对算法相关的配置文件解读和扩展,使读者能够更加熟练的自定义配置
- 通过对常用算法进行解读,使读者能够更加便捷快速的使用 MMDetection
作为开篇系列,第一个解读算法是 RetinaNet。或许大家会有所疑问:为什么第一个解读算法不是经典的 Faster R-CNN? 这是由于考虑到 Faster R-CNN 包括两个阶段,复杂度比较高,并且第一阶段可以认为是 one-stage 检测器。为了降低理解 Faster R-CNN 难度,我们先分析经典的 one-stage 算法 RetinaNet。在理解该算法基础上再去理解 Faster R-CNN,应该会更加容易,思路也会更加清晰。
本系列文章的重点是解读 MMDetection 中相关算法实现,对于其原理描述的比较简单,并且一些配置和参数都是以 MMDetection 默认参数为准,某些参数和设置不完全与论文相同。
在阅读本文前,请先阅读前置系列文章。MMDetection 依然在快速发展,本文解读的版本是 V2.8。
需要特别注意的是:由于本文是系列文章开篇,所涉及的内容不仅仅是 RetinaNet,还包括了配置文件里面每个参数的详细解读(这个非常关键),在后续文章中如果出现重复配置就不再描述,故不管你对 RetinaNet 有多了解,如果你想进一步熟悉 MMDetection 参数配置及其含义,那么本文可能对你有帮助。
1 RetinaNet 简要介绍
RetinaNet 来自 FAIR 论文:Focal Loss for Dense Object Detection,其简要概述为:深入分析了极度不平衡的正负(前景背景)样本比例导致 one-stage 检测器精度低于 two-stage 检测器,基于上述分析,提出了一种简单但是非常实用的 Focal Loss 焦点损失函数,并且 Loss 设计思想可以推广到其他领域,同时针对目标检测领域特定问题,设计了 RetinaNet 网络,结合 Focal Loss 使得 one-stage 检测器在精度上能够达到乃至超过 two-stage 检测器。
其简要网络结构图如下所示: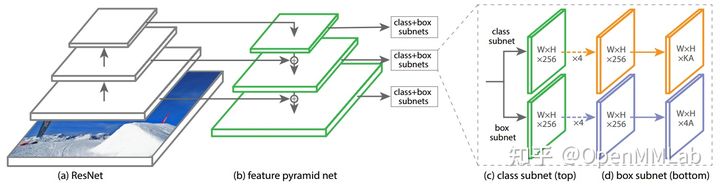
总的来说,RetinaNet 有两个大创新:
- Focal Loss
- RetinaNet 网络
Focal Loss 几乎已经成为 one-stage 算法的标配,而 RetinaNet 网络结构也是目前主流的目标检测网络结构,其变体不计其数。
2 RetinaNet 代码详解
在轻松掌握 MMDetection 整体构建流程(一)一文中分析了 MMDetection 中模型构建的基本组件,RetinaNet 涉及的组件包括: Backbone、Neck、Head、BBox Assigner、BBox Encoder Decoder、Loss 和 BBox PostProcess。下面按照顺序结合代码详细分析。
2.1 Backbone
标准的 RetinaNet 骨架网络采用的是 ResNet 系列。由于骨架本身没有限制,MMDetection 中目前提供的预训练权重所涉及的骨架网络包括:ResNet50-Caffe、ResNet50-Pytorch、ResNet101-Caffe、ResNet101-Pytorch、ResNeXt101,非常丰富。
为了读者好理解,先解释下配置文件名含义:
- retinanet 表示算法名称
- r50 等表示骨架网络名
- caffe 和 PyTorch 是指 Bottleneck 模块的区别,省略情况下表示是 PyTorch,后面会详细说明
- fpn 表示 Neck 模块采用了 FPN 结构
- mstrain 表示多尺度训练,一般对应的是 pipeline 中 Resize 类
- 1x 表示 1 倍数的 epoch 训练即 12 个 epoch,2x 则表示 24 个 epcoh
- coco 表示在 COCO 数据集上训练
以 ResNet50 为例进行具体分析,骨架网络配置如下:
# 使用 pytorch 提供的在 imagenet 上面训练过的权重作为预训练权重pretrained='torchvision://resnet50',backbone=dict(# 骨架网络类名type='ResNet',# 表示使用 ResNet50depth=50,# ResNet 系列包括 stem+ 4个 stage 输出num_stages=4,# 表示本模块输出的特征图索引,(0, 1, 2, 3),表示4个 stage 输出都需要,# 其 stride 为 (4,8,16,32),channel 为 (256, 512, 1024, 2048)out_indices=(0, 1, 2, 3),# 表示固定 stem 加上第一个 stage 的权重,不进行训练frozen_stages=1,# 所有的 BN 层的可学习参数都不需要梯度,也就不会进行参数更新norm_cfg=dict(type='BN', requires_grad=True),# backbone 所有的 BN 层的均值和方差都直接采用全局预训练值,不进行更新norm_eval=True,# 默认采用 pytorch 模式style='pytorch'),
可以看出,RetinaNet 算法采用了 ResNet50 作为 Backbone, 并且考虑到整个目标检测网络比较大,前面部分网络没有进行训练,BN 也不会进行参数更新。需要说明的是上述默认配置是经过前人工作和 OpenMMLab 在 COCO 数据集上不断实践的结果。推荐大家直接使用该配置模式,效果相对比较稳定。
(1) out_indices
ResNet 提出了骨架网络设计范式即 stem+n stage+ cls head,对于 ResNet 而言,其实际 forward 流程是 stem -> 4 个 stage -> 分类 head,stem 的输出 stride 是 4,而 4 个 stage 的输出 stride 是 4,8,16,32,这 4 个输出就对应 out_indices 索引。例如如果你想要输出 stride=4 的特征图,那么你可以设置 out_indices=(0,),如果你想要输出 stride=4 和 8 的特征图,那么你可以设置 out_indices=(0, 1)。
因为 RetinaNet 后面需要接 FPN,故需要输出 4 个尺度特征图,简要代码如下:
for i, layer_name in enumerate(self.res_layers):res_layer = getattr(self, layer_name)x = res_layer(x)# 如果 i 在 self.out_indices 中才保留if i in self.out_indices:outs.append(x)
(2) frozen_stages
该参数表示你想冻结前几个 stages 的权重,ResNet 结构包括 stem+4 stage
- frozen_stages=-1,表示全部可学习
- frozen_stage=0,表示stem权重固定
- frozen_stages=1,表示 stem 和第一个 stage 权重固定
- frozen_stages=2,表示 stem 和前两个 stage 权重固定
依次类推,具体代码为:
# 固定权重,需要两个步骤:1. 设置 eval 模式;2. requires_grad=Falsedef _freeze_stages(self):if self.frozen_stages >= 0:# 固定 stem 权重if self.deep_stem:self.stem.eval()for param in self.stem.parameters():param.requires_grad = Falseelse:self.norm1.eval()for m in [self.conv1, self.norm1]:for param in m.parameters():param.requires_grad = False# 固定 stage 权重for i in range(1, self.frozen_stages + 1):m = getattr(self, f'layer{i}')m.eval()for param in m.parameters():param.requires_grad = False
需要特别注意的是:上述函数不能仅仅在类初始化时候调用,因为在训练模式下,运行时候会调用 model.train() 导致 BN 层又进入 train 模式,最终 BN 没有被固定,故需要在 ResNet 中重写 train 方法,如下所示:
def train(self, mode=True):# 这行代码会导致 BN 进入 train 模式super(ResNet, self).train(mode)# 再次调用,固定 stem 和 前 n 个 stage 的 BNself._freeze_stages()# 如果所有 BN 都采用全局均值和方差,则需要对整个网络的 BN 都开启 eval 模式if mode and self.norm_eval:for m in self.modules():# trick: eval have effect on BatchNorm onlyif isinstance(m, _BatchNorm):m.eval()
如果你自定义了骨架网络,想实现固定某一部分权重功能,你可以参考上述做法。
(3) norm_cfg 和 norm_eval
norm_cfg 表示所采用的归一化算子,一般是 BN 或者 GN,而 requires_grad 表示该算子是否需要梯度,也就是是否进行参数更新,而布尔参数 norm_eval 是用于控制整个骨架网络的归一化算子是否需要变成 eval 模式。
RetinaNet 中用法是 norm_cfg=dict(type='BN', requires_grad=True),表示通过 Registry 模式实例化 BN 类,并且设置为参数可学习。在 MMDetection 中会常看到通过字典配置方式来实例化某个类的做法, 底层是采用了装饰器模式进行构建,最大好处是扩展性极强,类和类之间的耦合度降低。
(4) style
style=’caffe’ 和 style=’pytorch’ 的差别就在 Bottleneck 模块中
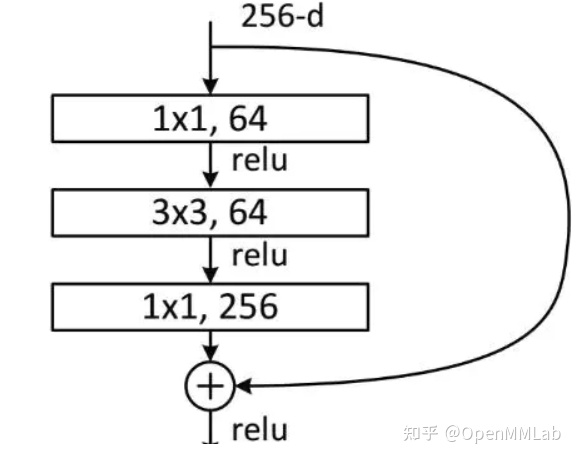
Bottleneck 是标准的 1x1-3x3-1x1 结构,考虑 stride=2 下采样的场景,caffe 模式下,stride 参数放置在第一个 1x1 卷积上,而 Pyorch 模式下,stride 放在第二个 3x3 卷积上:
if self.style == 'pytorch':self.conv1_stride = 1self.conv2_stride = strideelse:self.conv1_stride = strideself.conv2_stride = 1
出现两种模式的原因是因为 ResNet 本身就有不同的实现,torchvision 的 resnet 和早期 release 的 resnet 版本不一样,使得目标检测框架在使用 Backbone 的时候有两种不同的配置,不过目前新网络都是采用 PyTorch 模式。
2.2 Neck
Neck 模块即为 FPN,其简要结构如下所示: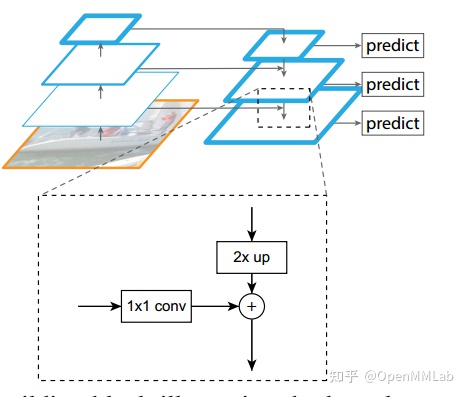
MMDetection 中对应配置为:
neck=dict(type='FPN',# ResNet 模块输出的4个尺度特征图通道数in_channels=[256, 512, 1024, 2048],# FPN 输出的每个尺度输出特征图通道out_channels=256,# 从输入多尺度特征图的第几个开始计算start_level=1,# 额外输出层的特征图来源add_extra_convs='on_input',# FPN 输出特征图个数num_outs=5),
前面说过 ResNet 输出 4 个不同尺度特征图 (c2,c3,c4,c5),stride 分别是 (4,8,16,32),通道数为 (256,512,1024,2048),通过配置文件我们可以知道:
- start_level=1 说明虽然输入是 4 个特征图,但是实际上 FPN 中仅仅用了后面三个
- num_outs=5 说明 FPN 模块虽然是接收 3 个特征图,但是输出 5 个特征图
- add_extra_convs=’on_input’ 说明额外输出的 2 个特征图的来源是骨架网络输出,而不是 FPN 层本身输出又作为后面层的输入
- out_channels=5 说明了 5 个输出特征图的通道数都是 256
下面对代码运行流程进行描述:
- 将 c3、c4 和 c5 三个特征图全部经过各自 1x1 卷积进行通道变换得到 m3~m5,输出通道统一为 256
- 从 m5(特征图最小)开始,先进行 2 倍最近邻上采样,然后和 m4 进行 add 操作,得到新的 m4
- 将新 m4 进行 2 倍最近邻上采样,然后和 m3 进行 add 操作,得到新的 m3
- 对 m5 和新融合后的 m4、m3,都进行各自的 3x3 卷积,得到 3 个尺度的最终输出 P5~P3
- 将 c5 进行 3x3 且 stride=2 的卷积操作,得到 P6
- 将 P6 再一次进行 3x3 且 stride=2 的卷积操作,得到 P7
P6 和 P7 目的是提供一个大感受野强语义的特征图,有利于大物体和超大物体检测。 在 RetinaNet 的 FPN 模块中只包括卷积,不包括 BN 和 ReLU。
总结:FPN 模块接收 c3, c4, c5 三个特征图,输出 P2-P7 五个特征图,通道数都是 256, stride 为 (8,16,32,64,128),其中大 stride (特征图小)用于检测大物体,小 stride (特征图大)用于检测小物体。
2.3 Head
论文中作者认为 one-stage 算法 head 设计比较关键,对最终性能影响较大,相比于其余 one-stage 算法,RetinaNet 的 Head 模块比较重量级,输出头包括分类和检测两个分支,且每个分支都包括 4 个卷积层,不进行参数共享,分类 Head 输出通道是 num_classK,检测 head 输出通道是4K, K 是 anchor 个数, 虽然每个 Head 的分类和回归分支权重不共享,但是 5 个输出特征图的 Head 模块权重是共享的。
其完整配置如下:
bbox_head=dict(type='RetinaHead',# COCO 数据集类别个数num_classes=80,# FPN 层输出特征图通道数in_channels=256,# 每个分支堆叠4层卷积stacked_convs=4,# 中间特征图通道数feat_channels=256,# 后面分析anchor_generator=dict(type='AnchorGenerator',octave_base_scale=4,scales_per_octave=3,ratios=[0.5, 1.0, 2.0],strides=[8, 16, 32, 64, 128]),# 后面分析bbox_coder=dict(type='DeltaXYWHBBoxCoder',target_means=[.0, .0, .0, .0],target_stds=[1.0, 1.0, 1.0, 1.0]),# 后面分析loss_cls=dict(type='FocalLoss',use_sigmoid=True,gamma=2.0,alpha=0.25,loss_weight=1.0),# 后面分析loss_bbox=dict(type='L1Loss', loss_weight=1.0)))
Head 模块比较简单,网络构建代码如下所示:
def _init_layers(self):# stacked_convs=4for i in range(self.stacked_convs):# 构建4个中间卷积层,分类和回归分支不共享权重chn = self.in_channels if i == 0 else self.feat_channelsself.cls_convs.append(ConvModule(chn,self.feat_channels,3,...))self.reg_convs.append(ConvModule(chn,self.feat_channels,3,...))# 构建最终输出层self.retina_cls = nn.Conv2d(self.feat_channels,self.num_anchors * self.cls_out_channels,3,padding=1)self.retina_reg = nn.Conv2d(self.feat_channels, self.num_anchors * 4, 3, padding=1)
单张特征图的 forward 流程为:
# x是 p3-p7 中的某个特征图cls_feat = xreg_feat = x# 4层不共享参数卷积for cls_conv in self.cls_convs:cls_feat = cls_conv(cls_feat)for reg_conv in self.reg_convs:reg_feat = reg_conv(reg_feat)# 输出特征图cls_score = self.retina_cls(cls_feat)bbox_pred = self.retina_reg(reg_feat)return cls_score, bbox_pred
5 个输出 Head 共享所有分类或者回归分支的卷积权重,经过 Head 模块的前向流程输出一共是 5*2 个特征图。
2.4 BBox Assigner
2.4.1 AnchorGenerator
RetinaNet 属于 Anchor-based 算法,在运行 bbox 属性分配前需要得到每个输出特征图位置的 anchor 列表,故在分析 BBox Assigner 前,需要先详细说明下 anchor 生成过程,其对应配置如下所示:
anchor_generator=dict(type='AnchorGenerator',# 特征图 anchor 的 base scale, 值越大,所有 anchor 的尺度都会变大octave_base_scale=4,# 每个特征图有3个尺度,2**0, 2**(1/3), 2**(2/3)scales_per_octave=3,# 每个特征图有3个高宽比例ratios=[0.5, 1.0, 2.0],# 特征图对应的 stride,必须特征图 stride 一致,不可以随意更改strides=[8, 16, 32, 64, 128]),
从上面配置可以看出:RetinaNet 一共 5 个输出特征图,每个特征图上有 3 种尺度和 3 种宽高比,每个位置一共 9 个 anchor,并且通过 octave_base_scale 参数来控制全局 anchor 的 base scales ,如果自定义数据集中普遍都是大物体或者小物体,则可能修改更改 octave_base_scale 参数。
为了方便理解,可以写个简单脚本可视化下指定特征图位置的 anchor 情况。
import numpy as npfrom mmcv.visualization import imshow_bboxesimport matplotlib.pyplot as pltfrom mmdet.core import build_anchor_generatorif __name__ == '__main__':anchor_generator_cfg = dict(type='AnchorGenerator',octave_base_scale=4,scales_per_octave=3,ratios=[0.5, 1.0, 2.0],strides=[8, 16, 32, 64, 128])anchor_generator = build_anchor_generator(anchor_generator_cfg)# 输出原图尺度上 anchor 坐标 xyxy 左上角格式# base_anchors 长度为5,表示5个输出特征图,不同的特征图尺度相差的只是 strides# 故我们取 strides=8 的位置 anchor 可视化即可base_anchors = anchor_generator.base_anchors[0]h = 100w = 160img = np.ones([h, w, 3], np.uint8) * 255base_anchors[:, 0::2] += w // 2base_anchors[:, 1::2] += h // 2colors = ['green', 'red', 'blue']for i in range(3):base_anchor = base_anchors[i::3, :].cpu().numpy()imshow_bboxes(img, base_anchor, show=False, colors=colors[i])plt.grid()plt.imshow(img)plt.show()
结果如下所示:
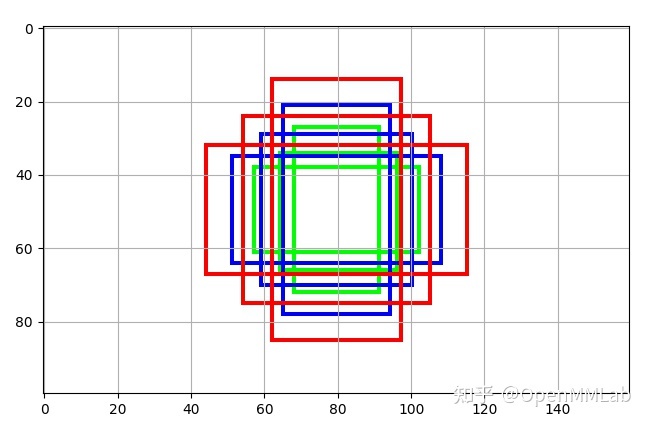
相同颜色表示在该特征图中基本尺度是相同的,只是宽高比不一样而已。
在对 AnchorGenerator 有基本认识后,下面对其实现源码进行分析:
(1) 先对单个位置 (0,0) 生成 base anchors
w = base_sizeh = base_size# 计算高宽比例h_ratios = torch.sqrt(ratios)w_ratios = 1 / h_ratios# base_size 乘上宽高比例乘上尺度,就可以得到 n 个 anchor 的原图尺度wh值ws = (w * w_ratios[:, None] * scales[None, :]).view(-1)hs = (h * h_ratios[:, None] * scales[None, :]).view(-1)# 得到 x1y1x2y2 格式的 base_anchor 坐标值base_anchors = [x_center - 0.5 * ws, y_center - 0.5 * hs, x_center + 0.5 * ws,y_center + 0.5 * hs]# 堆叠起来即可base_anchors = torch.stack(base_anchors, dim=-1)
(2) 利用输入特征图尺寸加上 base anchors,得到每个特征图位置的对于原图的 anchors
feat_h, feat_w = featmap_size# 遍历特征图上所有位置,并且乘上 stride,从而变成原图坐标shift_x = torch.arange(0, feat_w, device=device) * stride[0]shift_y = torch.arange(0, feat_h, device=device) * stride[1]shift_xx, shift_yy = self._meshgrid(shift_x, shift_y)shifts = torch.stack([shift_xx, shift_yy, shift_xx, shift_yy], dim=-1)shifts = shifts.type_as(base_anchors)# (0,0) 位置的 base_anchor,假设原图上坐标 shifts,即可得到特征图上面每个点映射到原图坐标上的 anchorall_anchors = base_anchors[None, :, :] + shifts[:, None, :]all_anchors = all_anchors.view(-1, 4)return all_anchors
简单来说就是:假设一共 m 个输出特征图
- 遍历 m 个输出特征图,在每个特征图的 (0,0) 或者说原图的 (0,0) 坐标位置生成 base_anchors,注意 base_anchors 不是特征图尺度,而是原图尺度
- 遍历 m 个输出特征图中每个特征图上每个坐标点,将其映射到原图坐标上
- 原图坐标点加上 base_anchors,就可以得到特征图每个位置的对应到原图尺度的 anchor 列表,anchor 列表长度为 m
2.4.2 BBox Assigner
计算得到输出特征图上面每个点对应的原图 anchor 坐标后,就可以和 gt 信息计算每个 anchor 的正负样本属性,对应配置如下:
assigner=dict(# 最大 IoU 原则分配器type='MaxIoUAssigner',# 正样本阈值pos_iou_thr=0.5,# 负样本阈值neg_iou_thr=0.4,# 正样本阈值下限min_pos_iou=0,# 忽略 bboes 的阈值,-1表示不忽略ignore_iof_thr=-1)
仅从上面的描述可能比较难理解参数含义,通过下面的流程分析就比较容易理解每个参数含义了。MaxIoUAssigner 操作包括 4 个步骤:
(1) 初始化所有 anchor 为忽略样本
假设所有输出特征的所有 anchor 总数一共 n 个,对应某张图片中 gt bbox 个数为 m,首先初始化长度为 n 的 assigned_gt_inds,全部赋值为 -1,表示当前全部设置为忽略样本
# 1. assign -1 by defaultassigned_gt_inds = overlaps.new_full((num_bboxes, ),-1,dtype=torch.long)
(2) 计算背景样本
将每个 anchor 和所有 gt bbox 计算 iou,找出最大 iou,如果该 iou 小于 neg_iou_thr 或者在背景样本阈值范围内,则该 anchor 对应索引位置的 assigned_gt_inds 设置为 0,表示是负样本(背景样本)
max_overlaps, argmax_overlaps = overlaps.max(dim=0)gt_max_overlaps, gt_argmax_overlaps = overlaps.max(dim=1)# 2. assign negative: below# the negative inds are set to be 0if isinstance(self.neg_iou_thr, float):assigned_gt_inds[(max_overlaps >= 0)& (max_overlaps < self.neg_iou_thr)] = 0elif isinstance(self.neg_iou_thr, tuple):assert len(self.neg_iou_thr) == 2# 可以设置一个范围assigned_gt_inds[(max_overlaps >= self.neg_iou_thr[0])& (max_overlaps < self.neg_iou_thr[1])] = 0
(3) 计算高质量正样本
将每个 anchor 和所有 gt bbox 计算 iou,找出最大 iou,如果其最大 iou 大于等于 pos_iou_thr,则设置该 anchor 对应所有的 assigned_gt_inds 设置为当前匹配 gt bbox 的编号 +1(后面会减掉 1),表示该 anchor 负责预测该 gt bbox,且是高质量 anchor。之所以要加 1,是为了区分背景样本(背景样本的 assigned_gt_inds 值为 0)
# 3. assign positive: above positive IoU thresholdpos_inds = max_overlaps >= self.pos_iou_thrassigned_gt_inds[pos_inds] = argmax_overlaps[pos_inds] + 1
(4) 适当增加更多正样本
在第三步计算高质量正样本中可能会出现某些 gt bbox 没有分配给任何一个 anchor (由于 iou 低于 pos_iou_thr),导致该 gt bbox 不被认为是前景物体,此时可以通过 self.match_low_quality=True 配置进行补充正样本。
对于每个 gt bbox 需要找出和其最大 iou 的 anchor 索引,如果其 iou 大于 min_pos_iou,则将该 anchor 对应索引的 assigned_gt_inds 设置为正样本,表示该 anchor 负责预测对应的 gt bbox。通过本步骤,可以最大程度保证每个 gt bbox 都有相应的 anchor 负责预测,**但是如果其最大 iou 值还是小于 min_pos_iou,则依然不被认为是前景物体**。
if self.match_low_quality:# Low-quality matching will overwirte the assigned_gt_inds assigned# in Step 3. Thus, the assigned gt might not be the best one for# prediction.# For example, if bbox A has 0.9 and 0.8 iou with GT bbox 1 & 2,# bbox 1 will be assigned as the best target for bbox A in step 3.# However, if GT bbox 2's gt_argmax_overlaps = A, bbox A's# assigned_gt_inds will be overwritten to be bbox B.# This might be the reason that it is not used in ROI Heads.for i in range(num_gts):if gt_max_overlaps[i] >= self.min_pos_iou:if self.gt_max_assign_all:#如果有多个相同最高 iou 的 anchor 和该 gt bbox 对应,则一并赋值max_iou_inds = overlaps[i, :] == gt_max_overlaps[i]# 同样需要加1assigned_gt_inds[max_iou_inds] = i + 1else:assigned_gt_inds[gt_argmax_overlaps[i]] = i + 1
从这一步可以看出,3 和 4 有部分 anchor 重复分配了,即当某个 gt bbox 和 anchor 的最大 iou 大于等于 pos_iou_thr,那肯定大于 min_pos_iou,此时 3 和 4 步骤分配的同一个 anchor,并且从上面注释可以看出本步骤可能会引入低质量 anchor,是否需要开启本步骤需要根据不同算法来确定。
再次回到 RetinaNet 的 bbox assigner 配置:
assigner=dict(# 最大 IoU 原则分配器type='MaxIoUAssigner',# 正样本阈值pos_iou_thr=0.5,# 负样本阈值neg_iou_thr=0.4,# 正样本阈值下限min_pos_iou=0,# 忽略 bbox 的阈值,-1表示不忽略ignore_iof_thr=-1)
此时可以可以得到如下总结:
- 如果 anchor 和所有 gt bbox 的最大 iou 值小于 0.4,那么该 anchor 就是背景样本
- 如果 anchor 和所有 gt bbox 的最大 iou 值大于等于 0.5,那么该 anchor 就是高质量正样本
- 如果 gt bbox 和所有 anchor 的最大 iou 值大于等于 0(可以看出每个 gt bbox 都一定有至少一个 anchor 匹配),那么该 gt bbox 所对应的 anchor 也是正样本
- 其余样本全部为忽略样本即 anchor 和所有 gt bbox 的最大 iou 值处于 [0.4,0.5) 区间的 anchor 为忽略样本,不计算 loss
2.5 BBox Encoder Decoder
在 anchor-based 算法中,为了利用 anchor 信息进行更快更好的收敛,一般会对 head 输出的 bbox 分支 4 个值进行编解码操作,作用有两个:
- 更好的平衡分类和回归分支 loss,以及平衡 bbox 四个预测值的 loss
- 训练过程中引入 anchor 信息,加快收敛
RetinaNet 采用的编解码函数是主流的 DeltaXYWHBBoxCoder,其配置如下:
bbox_coder=dict(type='DeltaXYWHBBoxCoder',target_means=[.0, .0, .0, .0],target_stds=[1.0, 1.0, 1.0, 1.0]),
target_means 和 target_stds 相当于对 bbox 回归的 4 个 txtytwth 进行变换。在不考虑 target_means 和 target_stds 情况下,其编码公式如下:
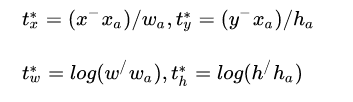
 是 gt bbox 的中心 xy 坐标,
是 gt bbox 的中心 xy 坐标,  是 gt bbox 的 wh 值,
是 gt bbox 的 wh 值,  是 anchor 的中心 xy 坐标,
是 anchor 的中心 xy 坐标,  是 anchor 的 wh 值,
是 anchor 的 wh 值,  是 bbox 分支输出的 4 个值对应 targets。可以看出
是 bbox 分支输出的 4 个值对应 targets。可以看出  预测值表示 gt bbox 中心相对于 anchor 中心点的偏移,并且通过除以 anchor 的 wh 进行归一化;而
预测值表示 gt bbox 中心相对于 anchor 中心点的偏移,并且通过除以 anchor 的 wh 进行归一化;而  预测值表示 gt bbox 的 wh 除以 anchor 的 wh,然后取 log 非线性变换即可。
预测值表示 gt bbox 的 wh 除以 anchor 的 wh,然后取 log 非线性变换即可。
考虑编码过程 target_means 和 target_stds 情况下,核心代码如下:
dx = (gx - px) / pwdy = (gy - py) / phdw = torch.log(gw / pw)dh = torch.log(gh / ph)deltas = torch.stack([dx, dy, dw, dh], dim=-1)# 最后减掉均值,处于标准差means = deltas.new_tensor(means).unsqueeze(0)stds = deltas.new_tensor(stds).unsqueeze(0)deltas = deltas.sub_(means).div_(stds)
解码过程是编码过程的反向,比较容易理解,其核心代码如下:
# 先乘上 std,加上 meanmeans = deltas.new_tensor(means).view(1, -1).repeat(1, deltas.size(1) // 4)stds = deltas.new_tensor(stds).view(1, -1).repeat(1, deltas.size(1) // 4)denorm_deltas = deltas * stds + meansdx = denorm_deltas[:, 0::4]dy = denorm_deltas[:, 1::4]dw = denorm_deltas[:, 2::4]dh = denorm_deltas[:, 3::4]# wh 解码gw = pw * dw.exp()gh = ph * dh.exp()# 中心点 xy 解码gx = px + pw * dxgy = py + ph * dy# 得到 x1y1x2y2 的 gt bbox 预测坐标x1 = gx - gw * 0.5y1 = gy - gh * 0.5x2 = gx + gw * 0.5y2 = gy + gh * 0.5
2.6 Loss
前面说过 RetinaNet 一个非常大的亮点就是提出了 Focal Loss。
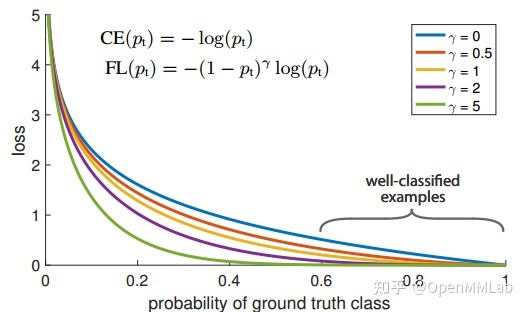
Focal Loss 属于 CE Loss 的动态加权版本,其可以根据样本的难易程度(预测值和 label 的差距可以反映)对每个样本单独加权,易学习样本权重比较低,难样本权重比较高。因为在前面的 bbox assigner 环节,大部分样本都是背景易学习样本,虽然其本身 loss 比较小,但是由于数目众多最终会主导梯度,从而得到次优模型,而 Focal Loss 通过指数效应把大量易学习样本的权重大大降低,从而避免上述问题。
完整的 Focal Loss 为: 
 属于正负样本的加权参数,值越大,正样本的权重越大,
属于正负样本的加权参数,值越大,正样本的权重越大,  有focal效应,可以控制难易样本权重,值越大,对分类错误样本梯度越大(难样本权重大),focal 效应越大,这个参数非常关键。
有focal效应,可以控制难易样本权重,值越大,对分类错误样本梯度越大(难样本权重大),focal 效应越大,这个参数非常关键。
代码实现方面也比较简单,MMDetection 提供了 py 和 cuda 版本,py 版本如下所示:
pred_sigmoid = pred.sigmoid()# one-hot 格式target = target.type_as(pred)pt = (1 - pred_sigmoid) * target + pred_sigmoid * (1 - target)focal_weight = (alpha * target + (1 - alpha) *(1 - target)) * pt.pow(gamma)loss = F.binary_cross_entropy_with_logits(pred, target, reduction='none') * focal_weightloss = weight_reduce_loss(loss, weight, reduction, avg_factor)return loss
RetinaNet 的完整 loss 配置如下:
# 分类 lossloss_cls=dict(type='FocalLoss',use_sigmoid=True,gamma=2.0,alpha=0.25,loss_weight=1.0),# 回归 lossloss_bbox=dict(type='L1Loss', loss_weight=1.0))
2.7 测试流程
对应配置如下所示:
test_cfg = dict(# nms 前每个输出层最多保留1000个预测框nms_pre=1000,# 过滤掉的最小 bbox 尺寸min_bbox_size=0,# 分值阈值score_thr=0.05,# nms 方法和 nms 阈值nms=dict(type='nms', iou_threshold=0.5),# 最终输出的每张图片最多 bbox 个数max_per_img=100)
测试阶段流程如下:
(1) 对 5 个 head 输出特征图结果进行遍历,先按照预测分值排序,保留前 nms_pre 个预测结果
if nms_pre > 0 and scores.shape[0] > nms_pre:# Get maximum scores for foreground classes.if self.use_sigmoid_cls:max_scores, _ = scores.max(dim=1)else:# remind that we set FG labels to [0, num_class-1]# since mmdet v2.0# BG cat_id: num_classmax_scores, _ = scores[:, :-1].max(dim=1)_, topk_inds = max_scores.topk(nms_pre)anchors = anchors[topk_inds, :]bbox_pred = bbox_pred[topk_inds, :]scores = scores[topk_inds, :]
(2) 对剩下的 bbox 进行解码
bboxes = self.bbox_coder.decode(anchors, bbox_pred, max_shape=img_shape)
(3) 还原到原图尺度
mlvl_bboxes = torch.cat(mlvl_bboxes)if rescale:mlvl_bboxes /= mlvl_bboxes.new_tensor(scale_factor)
(4) 用 score_thr 阈值对所有结果进行过滤,然后将保留框进行 nms,最终输出框最大为 max_per_img 个
valid_mask = scores > score_thrinds = valid_mask.nonzero(as_tuple=False).squeeze(1)bboxes, scores, labels = bboxes[inds], scores[inds], labels[inds]dets, keep = batched_nms(bboxes, scores, labels, nms_cfg)
3 总结
本文结合源码深入详细的分析了 MMDetection 中的 RetinaNet 模型,不仅如此,本文还将所涉及到的所有配置参数都进行了仔细分析,希望读者通过阅读本文可以了解到:
- RetinaNet 算法的整个实现过程和细节
- MMDetection 中算法的配置参数具体含义和用法
- 对 MMDetection 有更加清晰深入的理解

若有收获,就点个赞吧
0 人点赞
