数据增强
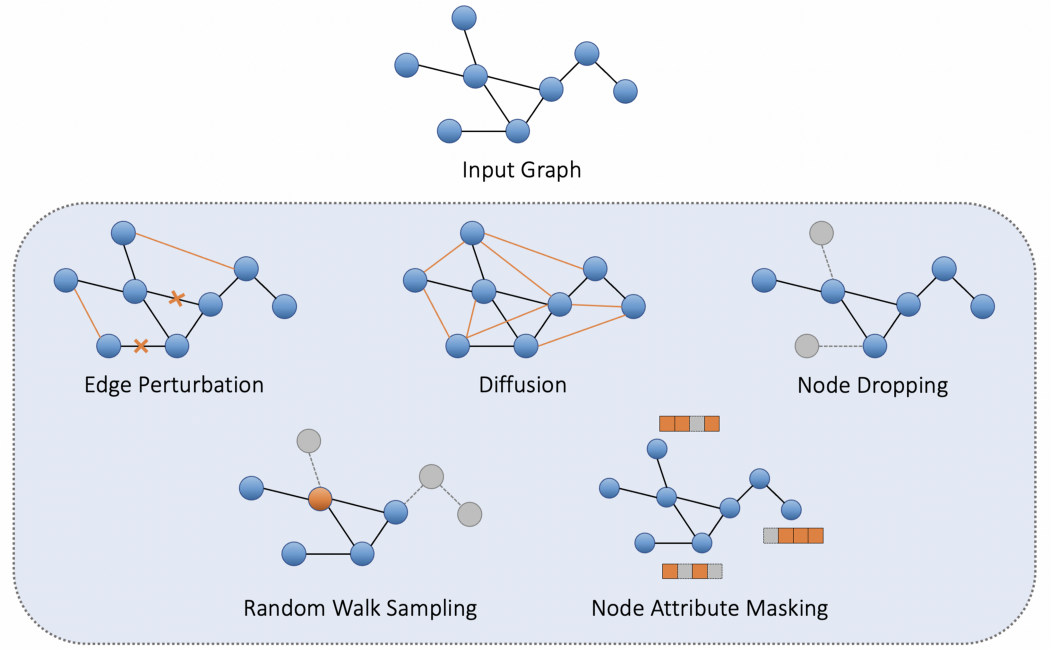
1. 边扰动:在这些增强中,我们以很小的概率在现有图中随机添加或删除边以创建新图。我们也有我们想要扰动的最大比例的边,这样我们就不会最终改变图的基本结构。以下视图生成的代码片段如下:
class EdgePerturbation():"""Edge perturbation on the given graph or batched graphs. Class objects callable viamethod :meth:`views_fn`.Args:add (bool, optional): Set :obj:`True` if randomly add edges in a given graph.(default: :obj:`True`)drop (bool, optional): Set :obj:`True` if randomly drop edges in a given graph.(default: :obj:`False`)ratio (float, optional): Percentage of edges to add or drop. (default: :obj:`0.1`)"""'''对给定的图或成批的图进行边缘扰动add:随机增加边drop:随机删除边ratio:增加或删除的边的百分比,默认0.1'''def __init__(self, add=True, drop=False, ratio=0.1):self.add = addself.drop = dropself.ratio = ratiodef do_trans(self, data):node_num, _ = data.x.size()_, edge_num = data.edge_index.size()perturb_num = int(edge_num * self.ratio)edge_index = data.edge_index.detach().clone()idx_remain = edge_indexidx_add = torch.tensor([]).reshape(2, -1).long()if self.drop:idx_remain = edge_index[:, np.random.choice(edge_num, edge_num-perturb_num, replace=False)]if self.add:idx_add = torch.randint(node_num, (2, perturb_num))new_edge_index = torch.cat((idx_remain, idx_add), dim=1)new_edge_index = torch.unique(new_edge_index, dim=1)return Data(x=data.x, edge_index=new_edge_index)
2. 扩散:在这些增强中,使用热核a heat kernel 将邻接矩阵转换为扩散矩阵,该热核提供图的全局视图,而不是邻接矩阵提供的局部视图。
class Diffusion():"""Diffusion on the given graph or batched graphs, used in`MVGRL <https://arxiv.org/pdf/2006.05582v1.pdf>`_. Class objects callable viamethod :meth:`views_fn`.Args:mode (string, optional): Diffusion instantiation mode with two options::obj:`"ppr"`: Personalized PageRank; :obj:`"heat"`: heat kernel.(default: :obj:`"ppr"`)alpha (float, optinal): Teleport probability in a random walk. (default: :obj:`0.2`)t (float, optinal): Diffusion time. (default: :obj:`5`)add_self_loop (bool, optional): Set True to add self-loop to edge_index.(default: :obj:`True`)"""'''在给定的图形或成批的图形上进行扩散mode 扩散实例化模式,有两个选项。"ppr"`: 个性化的PageRank; "heat"`:热核(默认::obj:`"ppr"`)。alpha (float, optinal): 随机行走中的传送概率。(默认: :obj:`0.2`)t (float, optinal): 扩散时间。(默认: :obj:`5`)add_self_loop (bool, optional): 设置为 "True",在edge_index上添加自我循环。'''def __init__(self, mode="ppr", alpha=0.2, t=5, add_self_loop=True):self.mode = modeself.alpha = alphaself.t = tself.add_self_loop = add_self_loopdef do_trans(self, data):node_num, _ = data.x.size()if self.add_self_loop:sl = torch.tensor([[n, n] for n in range(node_num)]).t()edge_index = torch.cat((data.edge_index, sl), dim=1)else:edge_index = data.edge_index.detach().clone()orig_adj = to_dense_adj(edge_index)[0]orig_adj = torch.where(orig_adj>1, torch.ones_like(orig_adj), orig_adj)d = torch.diag(torch.sum(orig_adj, 1))if self.mode == "ppr":dinv = torch.inverse(torch.sqrt(d))at = torch.matmul(torch.matmul(dinv, orig_adj), dinv)diff_adj = self.alpha * torch.inverse((torch.eye(orig_adj.shape[0]) - (1 - self.alpha) * at))elif self.mode == "heat":diff_adj = torch.exp(self.t * (torch.matmul(orig_adj, torch.inverse(d)) - 1))else:raise Exception("Must choose one diffusion instantiation mode from 'ppr' and 'heat'!")edge_ind, edge_attr = dense_to_sparse(diff_adj)return Data(x=data.x, edge_index=edge_ind, edge_attr=edge_attr)
3. 节点删除:在这些增强中,我们随机删除一小部分节点以创建新图。链接到该特定节点的所有边也会被删除。以下视图生成的代码片段是:
class UniformSample():"""Uniformly node dropping on the given graph or batched graphs.Class objects callable via method :meth:`views_fn`.Args:ratio (float, optinal): Ratio of nodes to be dropped. (default: :obj:`0.1`)"""'''均匀删除结点ratio:删除的概率 默认0.1'''def __init__(self, ratio=0.1):self.ratio = ratiodef do_trans(self, data):node_num, _ = data.x.size()_, edge_num = data.edge_index.size()keep_num = int(node_num * (1-self.ratio))idx_nondrop = torch.randperm(node_num)[:keep_num]mask_nondrop = torch.zeros_like(data.x[:,0]).scatter_(0, idx_nondrop, 1.0).bool()edge_index, _ = subgraph(mask_nondrop, data.edge_index, relabel_nodes=True, num_nodes=node_num)return Data(x=data.x[mask_nondrop], edge_index=edge_index)
torch.randperm(n) 返回一个0到n-1的数组
scatter函数解析
https://www.cnblogs.com/dogecheng/p/11938009.html 和
https://zhuanlan.zhihu.com/p/339043454
scatter(dim, index, src) 的参数有 3 个
- dim:沿着哪个维度进行索引
- index:用来 scatter 的元素索引
- src:用来 scatter 的源元素,可以是一个标量或一个张量
mask_nondrop = torch.zeros_like(data.x[:,0]).scatter_(0, idx_nondrop, 1.0).bool()
构造一个n行(x的行数,即总的node数)1列的全0矩阵,按行填入1 (这里不确定)
4.基于随机游走的采样:在这些增强中,我们在图上执行随机游走并继续添加节点,直到我们达到固定的预定数量的节点并从中形成子图。通过随机游走,我们的意思是,如果您当前在一个节点处,那么您将随机遍历该节点的一条边。以下视图生成的代码片段是:
class RWSample():"""Subgraph sampling based on random walk on the given graph or batched graphs.Class objects callable via method :meth:`views_fn`.Args:ratio (float, optional): Percentage of nodes to sample from the graph.(default: :obj:`0.1`)add_self_loop (bool, optional): Set True to add self-loop to edge_index.(default: :obj:`False`)"""'''基于随机游走ratio:采样比例添加自环'''def __init__(self, ratio=0.1, add_self_loop=False):self.ratio = ratioself.add_self_loop = add_self_loopdef do_trans(self, data):node_num, _ = data.x.size()sub_num = int(node_num * self.ratio)if self.add_self_loop:sl = torch.tensor([[n, n] for n in range(node_num)]).t()edge_index = torch.cat((data.edge_index, sl), dim=1)else:edge_index = data.edge_index.detach().clone()idx_sub = [np.random.randint(node_num, size=1)[0]]idx_neigh = set([n.item() for n in edge_index[1][edge_index[0]==idx_sub[0]]])count = 0while len(idx_sub) <= sub_num:count = count + 1if count > node_num:breakif len(idx_neigh) == 0:breaksample_node = np.random.choice(list(idx_neigh))if sample_node in idx_sub:continueidx_sub.append(sample_node)idx_neigh.union(set([n.item() for n in edge_index[1][edge_index[0]==idx_sub[-1]]]))idx_sub = torch.LongTensor(idx_sub).to(data.x.device)mask_nondrop = torch.zeros_like(data.x[:,0]).scatter_(0, idx_sub, 1.0).bool()edge_index, _ = subgraph(mask_nondrop, data.edge_index, relabel_nodes=True, num_nodes=node_num)return Data(x=data.x[mask_nondrop], edge_index=edge_index)
5. 节点属性屏蔽:在这些扩充中,我们屏蔽了一些节点的特征以创建扩充图。这里的掩码是通过从预先指定的均值和方差的高斯采样掩码的每个条目来创建的。希望是学习对节点特征不变且主要取决于图结构的表示。
class NodeAttrMask():"""Node attribute masking on the given graph or batched graphs.Class objects callable via method :meth:`views_fn`.Args:mode (string, optinal): Masking mode with three options::obj:`"whole"`: mask all feature dimensions of the selected node with a Gaussian distribution;:obj:`"partial"`: mask only selected feature dimensions with a Gaussian distribution;:obj:`"onehot"`: mask all feature dimensions of the selected node with a one-hot vector.(default: :obj:`"whole"`)mask_ratio (float, optinal): The ratio of node attributes to be masked. (default: :obj:`0.1`)mask_mean (float, optional): Mean of the Gaussian distribution to generate masking values.(default: :obj:`0.5`)mask_std (float, optional): Standard deviation of the distribution to generate masking values.Must be non-negative. (default: :obj:`0.5`)"""def __init__(self, mode='whole', mask_ratio=0.1, mask_mean=0.5, mask_std=0.5, return_mask=False):self.mode = modeself.mask_ratio = mask_ratioself.mask_mean = mask_meanself.mask_std = mask_stdself.return_mask = return_maskdef do_trans(self, data):node_num, feat_dim = data.x.size()x = data.x.detach().clone()if self.mode == "whole":mask = torch.zeros(node_num)mask_num = int(node_num * self.mask_ratio)idx_mask = np.random.choice(node_num, mask_num, replace=False)x[idx_mask] = torch.tensor(np.random.normal(loc=self.mask_mean, scale=self.mask_std,size=(mask_num, feat_dim)), dtype=torch.float32)mask[idx_mask] = 1elif self.mode == "partial":mask = torch.zeros((node_num, feat_dim))for i in range(node_num):for j in range(feat_dim):if random.random() < self.mask_ratio:x[i][j] = torch.tensor(np.random.normal(loc=self.mask_mean,scale=self.mask_std), dtype=torch.float32)mask[i][j] = 1elif self.mode == "onehot":mask = torch.zeros(node_num)mask_num = int(node_num * self.mask_ratio)idx_mask = np.random.choice(node_num, mask_num, replace=False)x[idx_mask] = torch.tensor(np.eye(feat_dim)[np.random.randint(0, feat_dim, size=(mask_num))], dtype=torch.float32)mask[idx_mask] = 1else:raise Exception("Masking mode option '{0:s}' is not available!".format(mode))if self.return_mask:return Data(x=x, edge_index=data.edge_index, mask=mask)else:return Data(x=x, edge_index=data.edge_index)
图神经网络
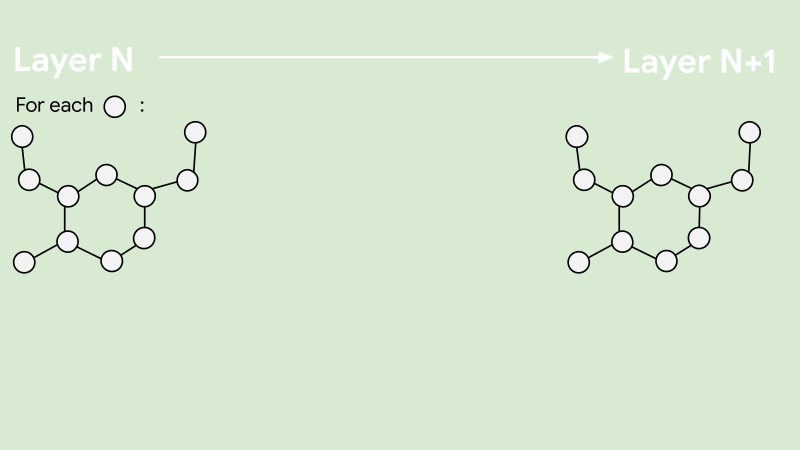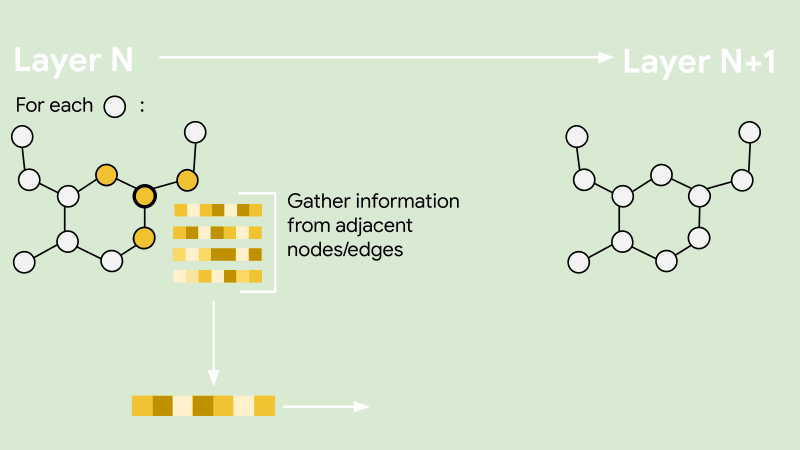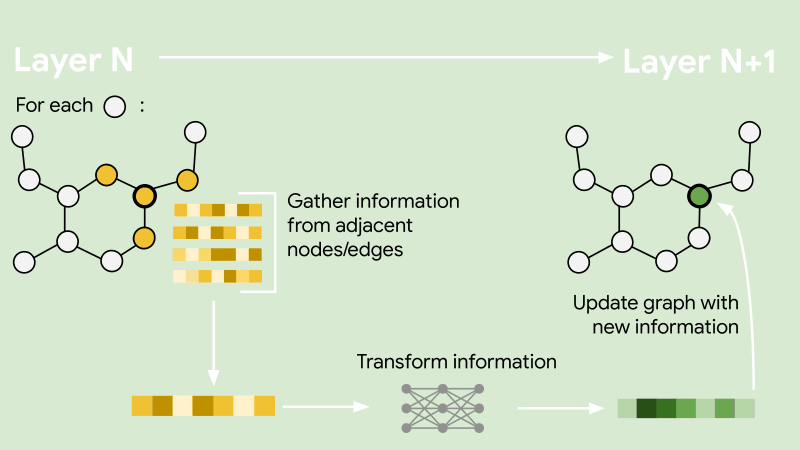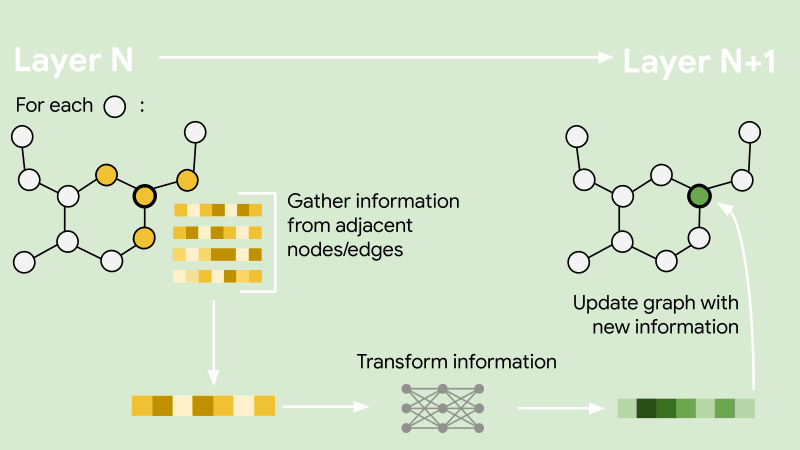
GraphSAGE
import torch.nn as nnfrom torch_geometric.nn import SAGEConvclass GraphSAGE(nn.Module):def __init__(self, feat_dim, hidden_dim, n_layers):super(GraphSAGE, self).__init__()self.convs = nn.ModuleList()self.acts = nn.ModuleList()self.n_layers = n_layersa = nn.ReLU()for i in range(n_layers):start_dim = hidden_dim if i else feat_dimconv = SAGEConv(start_dim, hidden_dim)self.convs.append(conv)self.acts.append(a)def forward(self, data):x, edge_index, batch = datafor i in range(self.n_layers):x = self.convs[i](x, edge_index)x = self.acts[i](x)return x
对比损失
目标是使正对之间的一致性高于负对。对于给定的图,它的正面是使用前面讨论的数据增强方法构建的,而小批量中的所有其他图构成为负面。我们的自我监督模型可以使用InfoNCE 目标[6] 或Jensen-Shannon Estimator [7] 进行训练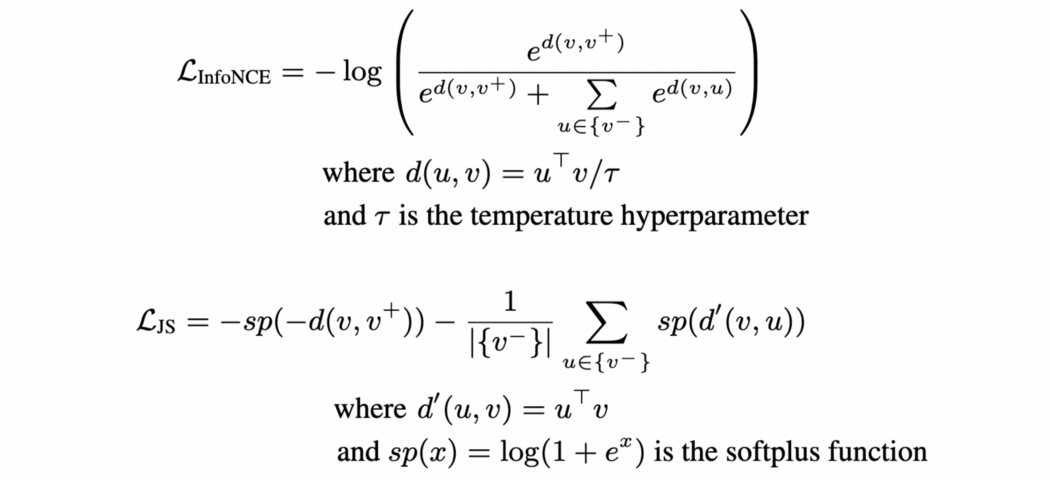
虽然这些指标的推导超出了本博客的范围,但这些指标背后的直觉植根于信息论,因此这些指标试图有效地估计视图之间的互信息。实现这些的代码片段如下
import torchdef infonce(readout_anchor, readout_positive, tau=0.5, norm=True):"""The InfoNCE (NT-XENT) loss in contrastive learning. The implementationfollows the paper `A Simple Framework for Contrastive Learning ofVisual Representations <https://arxiv.org/abs/2002.05709>`.Args:readout_anchor, readout_positive: Tensor of shape [batch_size, feat_dim]tau: Float. Usually in (0,1].norm: Boolean. Whether to apply normlization."""batch_size = readout_anchor.shape[0]sim_matrix = torch.einsum("ik,jk->ij", readout_anchor, readout_positive)if norm:readout_anchor_abs = readout_anchor.norm(dim=1)readout_positive_abs = readout_positive.norm(dim=1)sim_matrix = sim_matrix / torch.einsum("i,j->ij", readout_anchor_abs, readout_positive_abs)sim_matrix = torch.exp(sim_matrix / tau)pos_sim = sim_matrix[range(batch_size), range(batch_size)]loss = pos_sim / (sim_matrix.sum(dim=1) - pos_sim)loss = - torch.log(loss).mean()return loss
import torchimport numpy as npimport torch.nn.functional as Fdef get_expectation(masked_d_prime, positive=True):"""Args:masked_d_prime: Tensor of shape [n_graphs, n_graphs] for global_global,tensor of shape [n_nodes, n_graphs] for local_global.positive (bool): Set True if the d_prime is masked for positive pairs,set False for negative pairs."""log_2 = np.log(2.)if positive:score = log_2 - F.softplus(-masked_d_prime)else:score = F.softplus(-masked_d_prime) + masked_d_prime - log_2return scoredef jensen_shannon(readout_anchor, readout_positive):"""The Jensen-Shannon Estimator of Mutual Information used in contrastive learning. Theimplementation follows the paper `Learning deep representations by mutual informationestimation and maximization <https://arxiv.org/abs/1808.06670>`.Note: The JSE loss implementation can produce negative values because a :obj:`-2log2` shift isadded to the computation of JSE, for the sake of consistency with other f-convergence losses.Args:readout_anchor, readout_positive: Tensor of shape [batch_size, feat_dim]."""batch_size = readout_anchor.shape[0]pos_mask = torch.zeros((batch_size, batch_size))neg_mask = torch.ones((batch_size, batch_size))for graphidx in range(batch_size):pos_mask[graphidx][graphidx] = 1.neg_mask[graphidx][graphidx] = 0.d_prime = torch.matmul(readout_anchor, readout_positive.t())E_pos = get_expectation(d_prime * pos_mask, positive=True).sum()E_pos = E_pos / batch_sizeE_neg = get_expectation(d_prime * neg_mask, positive=False).sum()E_neg = E_neg / (batch_size * (batch_size - 1))return E_neg - E_pos
现在,我们可以将迄今为止所见的构建块拼凑起来,并在没有任何标记数据的情况下训练我们的模型。如需更多实践经验,请参阅我们的Colab Notebook,它结合了各种自我监督学习技术。我们提供了一个易于使用的界面来训练您自己的模型,以及尝试不同增强、GNN 和对比损失的灵活性。我们的整个代码库都可以在Github上找到
下游任务
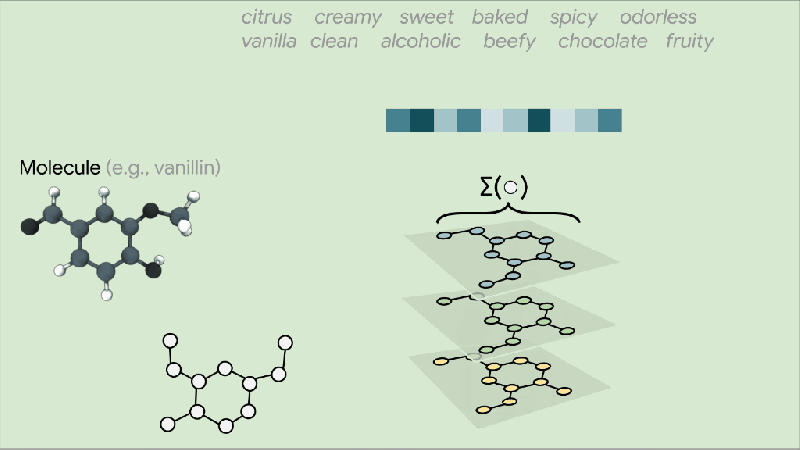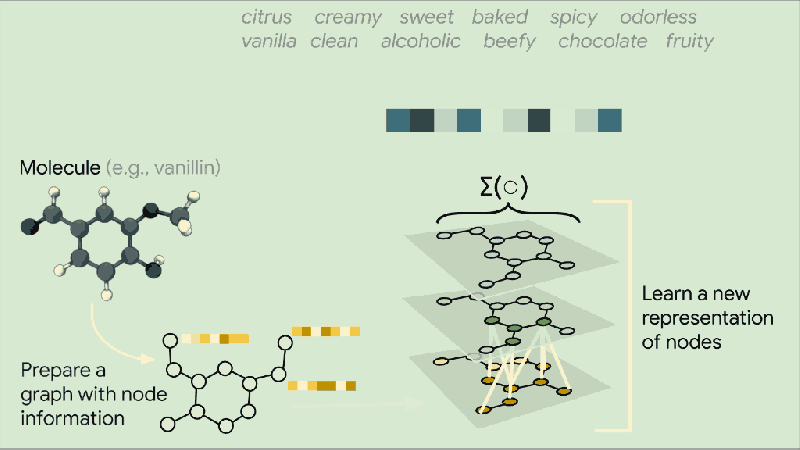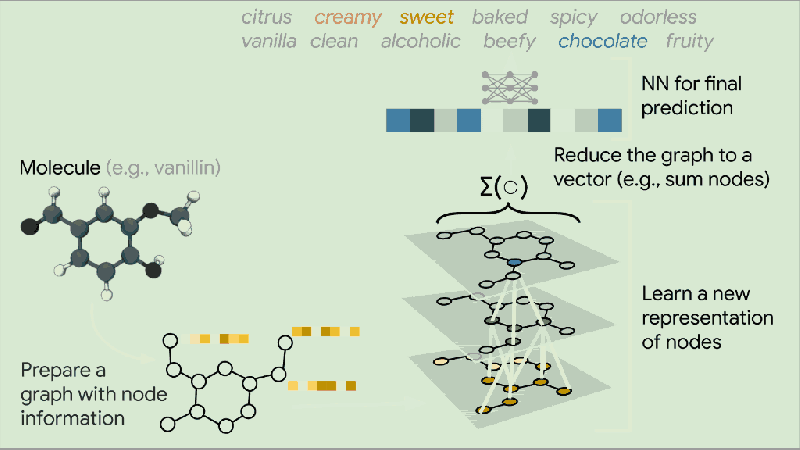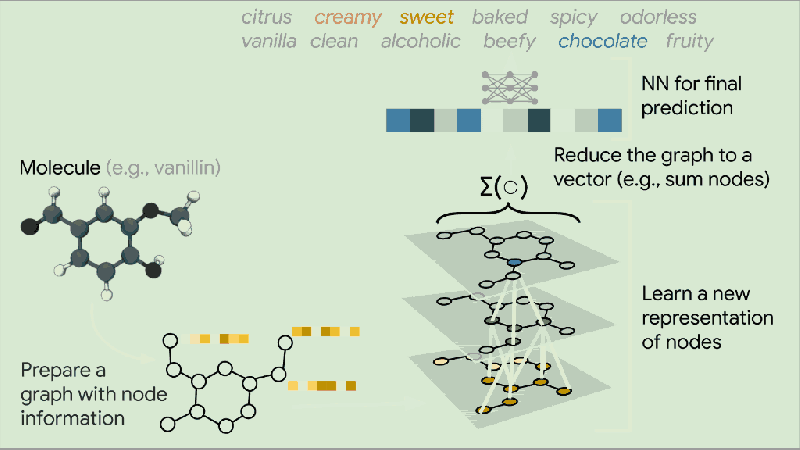
上图说明了将分子图分类为多个气味类别的任务
让我们考虑图分类的任务,它指的是根据一些结构图属性将图分类为不同类的问题。在这里,我们希望以一种在给定手头任务的情况下在潜在空间中可分离的方式嵌入整个图。我们的模型包括一个 GNN 编码器和一个分类器头,如下面的代码片段所示:
import osimport torchimport torch.nn as nnclass GraphClassificationModel(nn.Module):"""Model for graph classification.GNN Encoder followed by linear layer.Args:feat_dim (int): The dimension of input node features.hidden_dim (int): The dimension of node-level (local) embeddings.n_layers (int, optional): The number of GNN layers in the encoder. (default: :obj:`5`)gnn (string, optional): The type of GNN layer, :obj:`gcn` or :obj:`gin` or :obj:`gat`or :obj:`graphsage` or :obj:`resgcn` or :obj:`sgc`. (default: :obj:`gcn`)load (string, optional): The SSL model to be loaded. The GNN encoder will beinitialized with pretrained SSL weights, and only the classifier head willbe trained. Otherwise, GNN encoder and classifier head are trained end-to-end."""def __init__(self, feat_dim, hidden_dim, n_layers, output_dim, gnn, load=None):super(GraphClassificationModel, self).__init__()# Encoder is a wrapper class for easy instantiation of pre-implemented graph encoders.self.encoder = Encoder(feat_dim, hidden_dim, n_layers=n_layers, gnn=gnn)if load:ckpt = torch.load(os.path.join("logs", load, "best_model.ckpt"))self.encoder.load_state_dict(ckpt["state"])for param in self.encoder.parameters():param.requires_grad = Falseif gnn in ["resgcn", "sgc"]:feat_dim = hidden_dimelse:feat_dim = n_layers * hidden_dimself.classifier = nn.Linear(feat_dim, output_dim)def forward(self, data):embeddings = self.encoder(data)scores = self.classifier(embeddings)return scores
数据集:多特蒙德工业大学收集了大量不同的图形数据集,称为TUDatasets,可通过PyG中的 torchgeometric.datasets.TUDataset 访问。我们将在较小的数据集之一MUTAG上进行实验。该数据集中的每个图表都代表一种化合物,并且它还具有相关的二元标签,表示它们“对特定革兰氏阴性细菌的诱变作用”。该数据集包括 188 个图,每个图平均有 18 个节点,20 条边。我们打算在这个数据集上执行二进制分类。
**数据预处理_**:我们将数据集分成 131 个训练、37 个验证和 20 个测试图样本。我们还通过将节点度数表示为 one-hot 编码来为每个节点添加额外的特征。还可以包括传统的手工制作的特征,如节点中心性、聚类系数和图元计数,以获得更丰富的表示。
import torchimport randomimport torch.nn.functional as Ffrom torch_geometric.utils import degreefrom torch_geometric.datasets import TUDatasetDATA_SPLIT = [0.7, 0.2, 0.1] # Train / val / test split ratiodef get_max_deg(dataset):"""Find the max degree across all nodes in all graphs."""max_deg = 0for data in dataset:row, col = data.edge_indexnum_nodes = data.num_nodesdeg = degree(row, num_nodes)deg = max(deg).item()if deg > max_deg:max_deg = int(deg)return max_degclass CatDegOnehot(object):"""Adds the node degree as one hot encodings to the node features.Args:max_degree (int): Maximum degree.in_degree (bool, optional): If set to :obj:`True`, will compute the in-degree of nodes instead of the out-degree. (default: :obj:`False`)cat (bool, optional): Concat node degrees to node features insteadof replacing them. (default: :obj:`True`)"""def __init__(self, max_degree, in_degree=False, cat=True):self.max_degree = max_degreeself.in_degree = in_degreeself.cat = catdef __call__(self, data):idx, x = data.edge_index[1 if self.in_degree else 0], data.xdeg = degree(idx, data.num_nodes, dtype=torch.long)deg = F.one_hot(deg, num_classes=self.max_degree + 1).to(torch.float)if x is not None and self.cat:x = x.view(-1, 1) if x.dim() == 1 else xdata.x = torch.cat([x, deg.to(x.dtype)], dim=-1)else:data.x = degreturn datadef split_dataset(dataset, train_data_percent=1.0):"""Splits the data into train / val / test sets.Args:dataset (list): all graphs in the dataset.train_data_percent (float): Fraction of training datawhich is labelled. (default 1.0)"""random.shuffle(dataset)n = len(dataset)train_split, val_split, test_split = DATA_SPLITtrain_end = int(n * DATA_SPLIT[0] * train_data_percent)val_end = train_end + int(n * DATA_SPLIT[1])train_dataset, val_dataset, test_dataset = [i for i in dataset[:train_end]], [i for i in dataset[train_end:val_end]], [i for i in dataset[val_end:]]return train_dataset, val_dataset, test_dataset# load MUTAG from TUDatasetdataset = TUDataset(root="/tmp/TUDataset/MUTAG", name="MUTAG", use_node_attr=True)# expand node features by adding node degrees as one hot encodings.max_degree = get_max_deg(dataset)transform = CatDegOnehot(max_degree)dataset = [transform(graph) for graph in dataset]
训练:当使用交叉熵损失和亚当优化器使用 GCN 编码器进行训练时,我们实现了 60% 的分类准确率。由于标记数据量有限,准确率不是很高。
现在,让我们看看我们是否可以使用之前学习的自我监督技术来提高性能。我们可以使用多种数据增强技术,例如 Edge Perturbation 和 Node Dropping,来独立训练 GNN 编码器并学习更好的图嵌入。现在,可以使用可用的标记数据集对预训练的嵌入和分类器头进行微调。在 MUTAG 数据集上进行尝试时,我们观察到准确率跃升至 75%,比以前提高了 15%!
我们还在低维空间中可视化来自我们预训练的 GNN 编码器的嵌入。即使没有访问任何标签,自监督模型也能够将这两个类别分开,这是一项了不起的壮举!
这里还有一些例子,我们在不同的数据集上进行了相同的实验。请注意,它们都在 GCN 编码器上进行了训练,并通过边缘扰动和节点丢弃增强以及 InfoNCE 目标函数应用了自我监督。
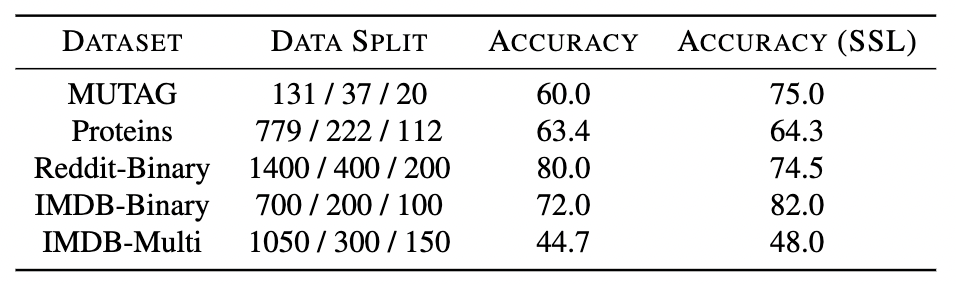
在多个数据集上比较有和没有自监督预训练的分类精度。
这种自我监督的预训练非常有效,尤其是在我们标记数据量有限的情况下。考虑一个我们只能访问 20% 的标记训练数据的设置。再一次,自我监督学习来拯救我们并显着提高模型性能!
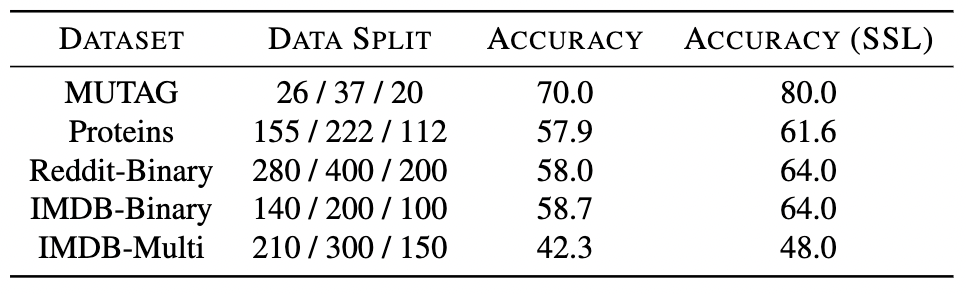
在多个数据集上比较有和没有自监督预训练的分类精度。在这里,我们仅使用 20% 的标记数据进行训练。
要试验更多数据集和自我监督技术,请按照我们的Google Colab或Github 存储库中的说明进行这项工作。
结论
总结这个博客,我们通过了解不同的数据增强技术以及通过对比学习将它们集成到图神经网络中来了解图的自我监督学习。我们还看到图分类任务的性能显着提高。
最近,许多研究都集中在寻找正确的增强策略,以便为各种图形应用程序学习更好的表示。在这里,我们总结了一些探索图自监督学习的最流行的方法。快乐阅读!
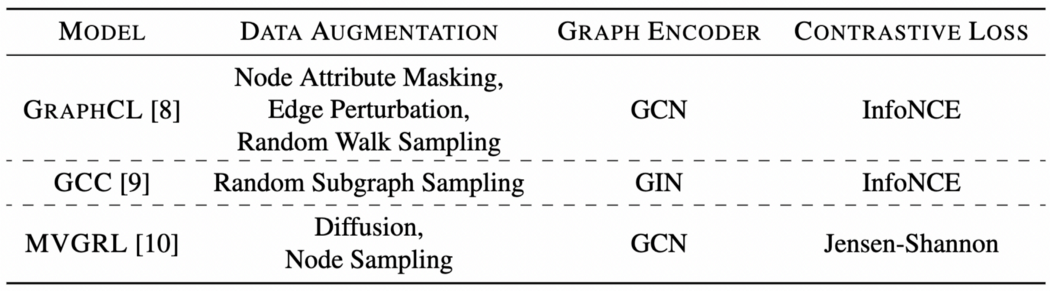
图上对比自我监督学习的流行方法。

若有收获,就点个赞吧
0 人点赞
