PyG的官方文档Google机翻
原地址:https://pytorch-geometric.readthedocs.io/en/latest/notes/introduction.html
其他文章:
https://zhuanlan.zhihu.com/p/78452993番外篇:PyG框架及Cora数据集简介
https://zhuanlan.zhihu.com/p/91229616图神经网络库PyTorch geometric(PYG)零基础上手教程(
苘郁蓁)
https://blog.csdn.net/Yichar/article/details/107856411PyG文档之二:快速入门
https://zhuanlan.zhihu.com/p/113862170CS224w 图神经网络(Graph Neural Networks)
我们将通过自包含的示例简要介绍 PyG 的基本概念。PyG 的核心提供以下主要功能:
图的数据处理
图用于对对象(节点)之间的成对关系(边)进行建模。PyG 中的单个图由 的实例描述torch_geometric.data.Data,默认情况下它包含以下属性:
- data.x:具有形状的节点特征矩阵 [num_nodes, num_node_features]
- data.edge_index:具有形状和类型的COO 格式的图形连接[2, num_edges]torch.long
- data.edge_attr: 带形状的边缘特征矩阵 [num_edges, num_edge_features]
- data.y:要训练的目标(可能具有任意形状),例如,形状的节点级目标或形状的图形级目标[num_nodes, ][1, ]
- data.pos:具有形状的节点位置矩阵 [num_nodes, num_dimensions]
这些属性都不是必需的。事实上,Data对象甚至不限于这些属性。例如,我们可以将其扩展data.face为将来自 3D 网格的三角形的连通性保存在具有 shape和 type的张量中。[3, num_faces]torch.long
PyTorch 并将torchvision示例定义为图像和目标的元组。我们在 PyG 中省略了这个符号,以允许以一种清晰易懂的方式使用各种数据结构。
我们展示了一个具有三个节点和四个边的未加权和无向图的简单示例。每个节点只包含一个特征:
import torchfrom torch_geometric.data import Dataedge_index = torch.tensor([[0, 1, 1, 2],[1, 0, 2, 1]], dtype=torch.long)x = torch.tensor([[-1], [0], [1]], dtype=torch.float)data = Data(x=x, edge_index=edge_index)>>> Data(edge_index=[2, 4], x=[3, 1])
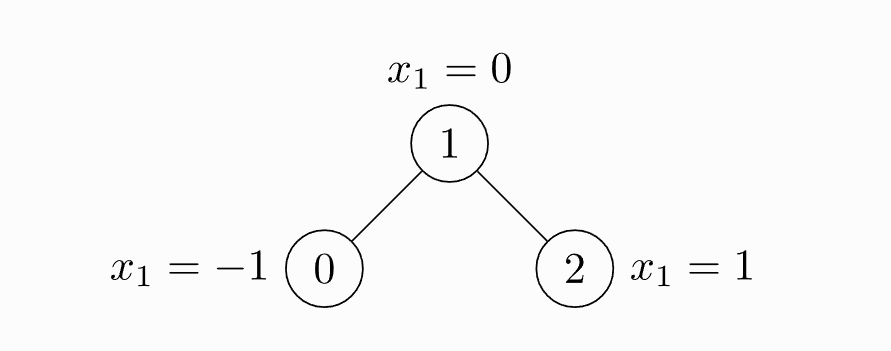
请注意edge_index,即定义所有边的源节点和目标节点的张量,不是索引元组列表。如果您想以这种方式编写索引,您应该contiguous在将它们传递给数据构造函数之前转置并调用它:
import torchfrom torch_geometric.data import Dataedge_index = torch.tensor([[0, 1],[1, 0],[1, 2],[2, 1]], dtype=torch.long)x = torch.tensor([[-1], [0], [1]], dtype=torch.float)data = Data(x=x, edge_index=edge_index.t().contiguous())>>> Data(edge_index=[2, 4], x=[3, 1])
尽管该图只有两条边,但我们需要定义四个索引元组来说明一条边的两个方向。
笔记
您可以随时打印出您的数据对象并接收有关其属性及其形状的简短信息。
除了持有许多节点级、边级或图级属性外,Data还提供了许多有用的实用功能,例如:
print(data.keys)>>> ['x', 'edge_index']print(data['x'])>>> tensor([[-1.0],[0.0],[1.0]])for key, item in data:print("{} found in data".format(key))>>> x found in data>>> edge_index found in data'edge_attr' in data>>> Falsedata.num_nodes>>> 3data.num_edges>>> 4data.num_node_features>>> 1data.has_isolated_nodes()>>> Falsedata.has_self_loops()>>> Falsedata.is_directed()>>> False# Transfer data object to GPU.device = torch.device('cuda')data = data.to(device)
您可以在 找到所有方法的完整列表torch_geometric.data.Data。
通用基准数据集
PyG 包含大量常见的基准数据集,例如所有 Planetoid 数据集(Cora、Citeseer、Pubmed)、来自http://graphkernels.cs.tu-dortmund.de 的所有图分类数据集及其清理版本、QM7 和 QM9数据集,以及一些 3D 网格/点云数据集,如 FAUST、ModelNet10/40 和 ShapeNet。
初始化数据集很简单。数据集的初始化将自动下载其原始文件并将其处理为之前描述的Data格式。 例如,要加载 ENZYMES 数据集(由 6 个类中的 600 个图形组成),请键入:
from torch_geometric.datasets import TUDatasetdataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES')>>> ENZYMES(600)len(dataset)>>> 600dataset.num_classes>>> 6dataset.num_node_features>>> 3
我们现在可以访问数据集中的所有 600 个图:
data = dataset[0]>>> Data(edge_index=[2, 168], x=[37, 3], y=[1])data.is_undirected()>>> True
我们可以看到数据集中的第一个图包含 37 个节点,每个节点有 3 个特征。有 168/2 = 84 条无向边,并且该图恰好分配给一个类。此外,数据对象正好持有一个图形级目标。
我们甚至可以使用切片、long 或 bool 张量来分割数据集。 例如,要创建 90/10 训练/测试拆分,请键入:
train_dataset = dataset[:540]>>> ENZYMES(540)test_dataset = dataset[540:]>>> ENZYMES(60)
如果您不确定在拆分之前数据集是否已经打乱,您可以通过运行来随机排列它:
dataset = dataset.shuffle()>>> ENZYMES(600)
这相当于做:
perm = torch.randperm(len(dataset))dataset = dataset[perm]>> ENZYMES(600)
让我们尝试另一个!让我们下载 Cora,半监督图节点分类的标准基准数据集:
from torch_geometric.datasets import Planetoiddataset = Planetoid(root='/tmp/Cora', name='Cora')>>> Cora()len(dataset)>>> 1dataset.num_classes>>> 7dataset.num_node_features>>> 1433
在这里,数据集仅包含一个无向引用图:
data = dataset[0]>>> Data(edge_index=[2, 10556], test_mask=[2708],train_mask=[2708], val_mask=[2708], x=[2708, 1433], y=[2708])data.is_undirected()>>> Truedata.train_mask.sum().item()>>> 140data.val_mask.sum().item()>>> 500data.test_mask.sum().item()>>> 1000
这一次,Data对象为每个节点持有一个标签,以及额外的节点级属性:train_mask、val_mask和test_mask,其中
- train_mask 表示针对哪些节点进行训练(140 个节点),
- val_mask表示用于验证的节点,例如,执行提前停止(500 个节点),
- test_mask 表示针对哪些节点进行测试(1000 个节点)。
小批量
神经网络通常以批处理方式进行训练。PYG通过创建稀疏块对角邻接矩阵(通过定义实现在小批量并行化edge_index),并在节点尺寸级联特征和目标矩阵。这种组合允许在一批中的示例上有不同数量的节点和边: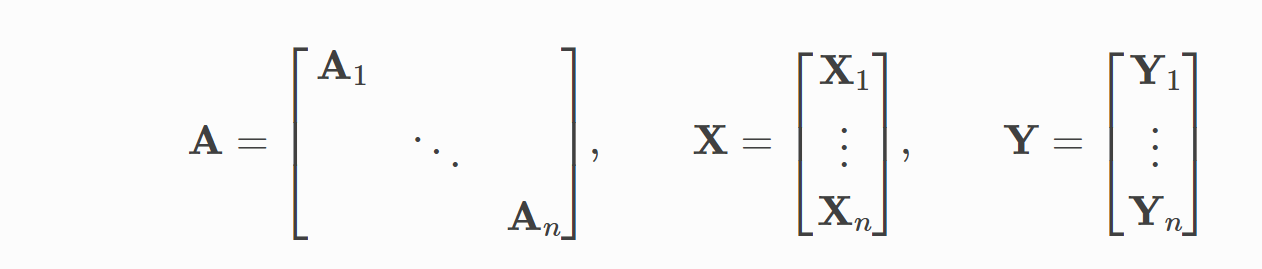
PyG 包含它自己的torch_geometric.loader.DataLoader,它已经处理了这个连接过程。让我们通过一个例子来了解它: ```python from torch_geometric.datasets import TUDataset from torch_geometric.loader import DataLoader
dataset = TUDataset(root=’/tmp/ENZYMES’, name=’ENZYMES’, use_node_attr=True) loader = DataLoader(dataset, batch_size=32, shuffle=True)
for batch in loader: batch
>>> DataBatch(batch=[1082], edge_index=[2, 4066], x=[1082, 21], y=[32])batch.num_graphs>>> 32
[torch_geometric.data.Batch](https://pytorch-geometric.readthedocs.io/en/latest/modules/data.html#torch_geometric.data.Batch)继承自[torch_geometric.data.Data](https://pytorch-geometric.readthedocs.io/en/latest/modules/data.html#torch_geometric.data.Data)并包含一个名为 的附加属性**batch**。<br />**batch** 是一个列向量,它将每个节点映射到批处理中的相应图形:<br />batch=[0⋯01⋯n−2n−1⋯n−1]⊤<br />_例如_,您可以使用它对每个图的节点维度中的节点特征进行平均:```pythonfrom torch_scatter import scatter_meanfrom torch_geometric.datasets import TUDatasetfrom torch_geometric.loader import DataLoaderdataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES', use_node_attr=True)loader = DataLoader(dataset, batch_size=32, shuffle=True)for data in loader:data>>> DataBatch(batch=[1082], edge_index=[2, 4066], x=[1082, 21], y=[32])data.num_graphs>>> 32x = scatter_mean(data.x, data.batch, dim=0)x.size()>>> torch.Size([32, 21])
您可以在此处了解有关 PyG 内部批处理程序的更多信息,例如,如何修改其行为。有关分散操作的文档,请有兴趣的读者参阅文档。torch-scatter
数据转换
变换是torchvision变换图像和执行增强的常用方法。PyG 带有自己的转换,它期望一个Data对象作为输入并返回一个新的转换Data对象。torch_geometric.transforms.Compose在将处理过的数据集保存到磁盘 ( pre_transform) 或访问数据集中的图形( ) 之前,可以使用和 将转换链接在一起transform。
让我们看一个例子,我们在 ShapeNet 数据集(包含 17,000 个 3D 形状点云和来自 16 个形状类别的每个点标签)上应用变换。
from torch_geometric.datasets import ShapeNetdataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'])dataset[0]>>> Data(pos=[2518, 3], y=[2518])
我们可以通过转换从点云生成最近邻图,将点云数据集转换为图数据集:
import torch_geometric.transforms as Tfrom torch_geometric.datasets import ShapeNetdataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'],pre_transform=T.KNNGraph(k=6))dataset[0]>>> Data(edge_index=[2, 15108], pos=[2518, 3], y=[2518])
笔记
我们在pre_transform将数据保存到磁盘之前使用来转换数据(导致加载时间更快)。请注意,下次初始化数据集时,它已经包含图形边缘,即使您没有传递任何转换。如果pre_transform与已处理数据集中的不匹配,您将收到警告。
此外,我们可以使用transform参数来随机增加一个Data对象,例如,将每个节点位置平移一个小数:
import torch_geometric.transforms as Tfrom torch_geometric.datasets import ShapeNetdataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'],pre_transform=T.KNNGraph(k=6),transform=T.RandomTranslate(0.01))dataset[0]>>> Data(edge_index=[2, 15108], pos=[2518, 3], y=[2518])
您可以在 找到所有已实现转换的完整列表torch_geometric.transforms。
图的学习方法
在学习了 PyG 中的数据处理、数据集、加载器和转换之后,是时候实现我们的第一个图神经网络了!
我们将使用一个简单的 GCN 层并在 Cora 引文数据集上复制实验。有关 GCN 的高级解释,请查看其博客文章。
我们首先需要加载 Cora 数据集:
from torch_geometric.datasets import Planetoiddataset = Planetoid(root='/tmp/Cora', name='Cora')>>> Cora()
请注意,我们不需要使用转换或数据加载器。现在让我们实现一个两层的 GCN:
import torchimport torch.nn.functional as Ffrom torch_geometric.nn import GCNConvclass GCN(torch.nn.Module):def __init__(self):super().__init__()self.conv1 = GCNConv(dataset.num_node_features, 16)self.conv2 = GCNConv(16, dataset.num_classes)def forward(self, data):x, edge_index = data.x, data.edge_indexx = self.conv1(x, edge_index)x = F.relu(x)x = F.dropout(x, training=self.training)x = self.conv2(x, edge_index)return F.log_softmax(x, dim=1)
构造函数定义了两个GCNConv层,它们在我们网络的前向传递中被调用。请注意,非线性未集成到conv调用中,因此需要在之后应用(这在 PyG 中的所有运算符中都是一致的)。在这里,我们选择使用 ReLU 作为我们的中间非线性,并最终在类别数量上输出一个 softmax 分布。让我们在训练节点上训练这个模型 200 个 epochs:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model = GCN().to(device)data = dataset[0].to(device)optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)model.train()for epoch in range(200):optimizer.zero_grad()out = model(data)loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])loss.backward()optimizer.step()
最后,我们可以在测试节点上评估我们的模型:
model.eval()pred = model(data).argmax(dim=1)correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()acc = int(correct) / int(data.test_mask.sum())print('Accuracy: {:.4f}'.format(acc))>>> Accuracy: 0.8150
这就是实现您的第一个图神经网络所需的全部内容。了解有关图神经网络的更多信息的最简单方法是研究examples/目录中的示例并浏览torch_geometric.nn. 快乐黑客!

若有收获,就点个赞吧
0 人点赞
