PREDICT THEN PROPAGATE: GRAPH NEURAL NETWORKS MEET PERSONALIZED PAGERANK
预测后传播:图神经网络满足个性化PageRank
ICLR 2019
其他参考:
https://zhuanlan.zhihu.com/p/417615165论文分享|无限层数GNN之PPNP
https://zhuanlan.zhihu.com/p/149161553APPNP:一个更强大的用于半监督分类的图卷积网络模型
摘要
用于图的半监督分类的神经消息传递算法最近取得了很大的成功。然而,在对节点进行分类时,这些方法只考虑距离几个传播步骤的节点,而且这个利用的邻域的大小很难扩展。本文利用图卷积网络(GCN)与PageRank之间的关系,推导出一种基于个性化PageRank的改进传播方案。我们利用这个传播过程构造了一个简单的模型,个性化神经预测传播(PPNP)及其快速近似APPNP。该模型的训练时间与以前的模型相当或更快,参数个数与以前的模型相当或更少。它利用一个大的、可调整的邻域进行分类,并且可以很容易地与任何神经网络相结合。我们表明,在迄今为止对GCN类模型所做的最深入的研究中,该模型的性能优于最近提出的几种半监督分类方法。我们的实现可以在网上获得。(https://www.kdd.in.tum.de/ppnp)
1.Introduction
图在现实世界中无处不在,它是通过科学模型来描述的。它们被用来研究信息的传播,优化传递,推荐新书,推荐朋友,或者寻找一个政党的潜在选民。深度学习方法在许多重要的图问题上取得了巨大的成功,例如链接预测(Grover&Leskovec,2016;Bojchevski等人,2018)、图分类(Duvenaud等人,2015;Niepert等人,2016;Gilmer等人,2017)和半监督节点分类(Yang等人,2016;Kipf&Well,2017)。
有许多方法可以利用图上的深度学习算法。节点嵌入方法使用随机行走或矩阵分解来直接训练单个节点嵌入,通常不使用节点特征,通常以无监督的方式,即不利用节点类(Perozzi等人,2014;Don等人,2015;Nandanwar&Murty,2016;Grover&Leskovec,2016;邱等人,2018)。许多其他方法在监督设置中既使用图形结构又使用节点特征。这些例子包括谱图卷积神经网络(Bruna等人,2014;Defferrard等人,2016)、消息传递(或邻居聚合)算法(Kearnes等人,2016;Kipf&Well,2017;Hamilton等人,2017;Pham等人,2017;Monti等人,2017;Gilmer等人,2017),以及通过递归神经网络进行邻居聚合(Scarselli等人,2009;Li等人,2016;Dai等人,2017。在这些类别中,消息传递算法类由于其灵活性和良好的性能最近受到了特别的关注。
一些工作旨在通过使用注意机制(Kearnes等人,2016年;Hamilton等人,2017年;Veliˇckovi‘c等人,2018年)、随机行走(Abu-El-Haija等人,2018a;Ying等人,2018年;Li等人,2018年)、边缘特征(Kearnes等人,2016年;Gilmer等人,2017年;Schlichtkrull等人,2018年)来改进基本邻域聚合方案,并使其更。然而,所有这些方法对于每个节点都只使用非常有限的邻域信息。希望较大的邻域为模型提供更多信息,特别是对于外围或稀疏标签设置中的节点。
增加这些算法所使用的邻域大小,即它们的范围,并不是小事,因为该方案中的邻域聚合本质上是一种拉普拉斯平滑,过多的层导致过度平滑(Li等人,2018)。Xu等人(2018)通过建立Kipf & Welling(2017)称为图卷积网络(GCN)的消息传递算法与随机行走之间的关系强调了同样的问题。利用这种关系,我们看到,随着层数的增加,GCN会收敛到这种随机行走的极限分布。极限分布是整个图的属性,没有考虑到随机行走的起始(根)节点。因此,它不适合描述根节点的邻居。因此,GCN的性能在高层数(或聚集/传播步骤)下必然会恶化。
为了解决这个问题,在本文中,我们首先强调了极限分布和PageRank之间的内在联系(Page等人,1998)。然后,我们提出了一种算法,该算法使用从个性化PageRank派生的传播方案。该算法增加了传送回根节点的机会,这确保了PageRank分数对每个根节点的本地邻域进行编码(Page等人,1998年)。传送概率允许我们在保持局部性(即,保持靠近根节点以避免过度平滑)和利用来自大型邻居的信息的需要之间取得平衡。我们证明了这种传播方案允许使用更多(实际上是无穷多个)传播步骤,而不会导致过度平滑。
此外,虽然传播和分类在消息传递中本质上是交织在一起的,但是我们提出的算法将神经网络从传播方案中分离出来。这允许我们在不改变神经网络的情况下实现更大的范围,而在消息传递方案中,每个额外的传播步骤都需要额外的层。它还允许独立开发传播算法和根据节点特征生成预测的神经网络。也就是说,我们可以将任何最先进的预测方法与我们的传播方案相结合。我们甚至发现,在推理过程中加入我们的传播方案,可以显著提高在不使用任何图信息的情况下训练的网络的准确性。
与大多数竞争模型相比,我们的模型实现了最先进的结果,同时需要更少的参数和更少的训练时间,计算复杂度与边的数量呈线性关系。我们在对消息传递模型进行的最彻底的研究(包括显著性测试)中展示了这些结果,这些研究使用的是具有基于文本的特性的图,这是目前为止已经完成的工作。
2. 图卷积网络及其有限的范围
GRAPH CONVOLUTIONAL NETWORKS AND THEIR LIMITED RANGE
我们首先介绍我们的符号并解释我们的模型所解决的问题。
我们首先来介绍本文所需要的符号表示和模型所要解决的问题。【以下根据原文进行了简写】 表示包含节点集合V和边集合E的图。
表示包含节点集合V和边集合E的图。 表示节点的数量,
表示节点的数量,  表示边的数量。
表示边的数量。 表示节点特征矩阵,其中,f 表示每一个节点的特征数量。
表示节点特征矩阵,其中,f 表示每一个节点的特征数量。 表示类/标签矩阵,c表示类别的数量。
表示类/标签矩阵,c表示类别的数量。 表示图的伴随矩阵,用来描述图的结构。
表示图的伴随矩阵,用来描述图的结构。 表示添加了自环的伴随矩阵。
表示添加了自环的伴随矩阵。
图卷积网络(GCN)是一种用于半监督分类的简单且广泛使用的消息传递算法。对于两个消息传递层,其等式为:
其中,  是被预测的节点标签。
是被预测的节点标签。 是添加自环的对称归一化邻接矩阵。其中,
是添加自环的对称归一化邻接矩阵。其中,  表示对角度矩阵。
表示对角度矩阵。 是可训练的权重矩阵。
是可训练的权重矩阵。
对于两个GCN层,只考虑两跳邻域中的邻居。像GCN这样的消息传递算法不能简单地扩展到使用更大的邻域,本质上有两个原因。首先,如果使用的层太多,平均聚合会导致过度平滑。因此,它失去了对当地社区的关注(Li等人,2018年)。其次,最常见的聚合方案在每一层中使用可学习的权重矩阵。因此,使用更大的邻域必然会增加神经网络的可学习参数的深度和数量(第二个方面可以通过使用权重共享来规避,但通常情况并非如此)。然而,所需的邻域大小和神经网络深度是两个完全正交的方面。这种固定的关系是一个很强的限制,会导致糟糕的妥协。
我们将从第一个问题开始。Xu等人(2018年)已经证明,对于k层gcn,节点x对y的影响分数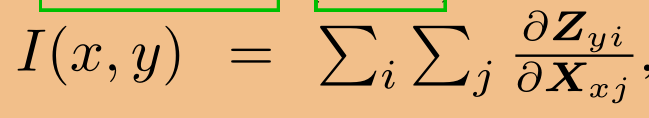 与从根节点x开始的略微修改的k步随机游动分布
与从根节点x开始的略微修改的k步随机游动分布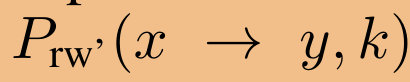 成正比。因此,节点x的信息以类似随机行走的方式传播到节点y。如果取极限k→∞,且图是不可约的非周期的,则这个随机游动概率分布
成正比。因此,节点x的信息以类似随机行走的方式传播到节点y。如果取极限k→∞,且图是不可约的非周期的,则这个随机游动概率分布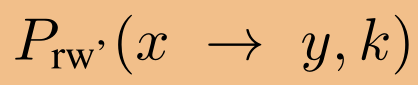 收敛到极限(或平稳)分布
收敛到极限(或平稳)分布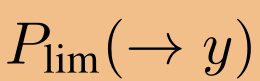 。这个分布可以通过求解方程
。这个分布可以通过求解方程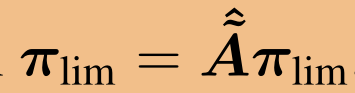 得到。显然,结果只依赖于图的整体,并且与随机游走的起始(根)节点x无关。因此,这种全局性质不适合描述根节点的邻域。
得到。显然,结果只依赖于图的整体,并且与随机游走的起始(根)节点x无关。因此,这种全局性质不适合描述根节点的邻域。
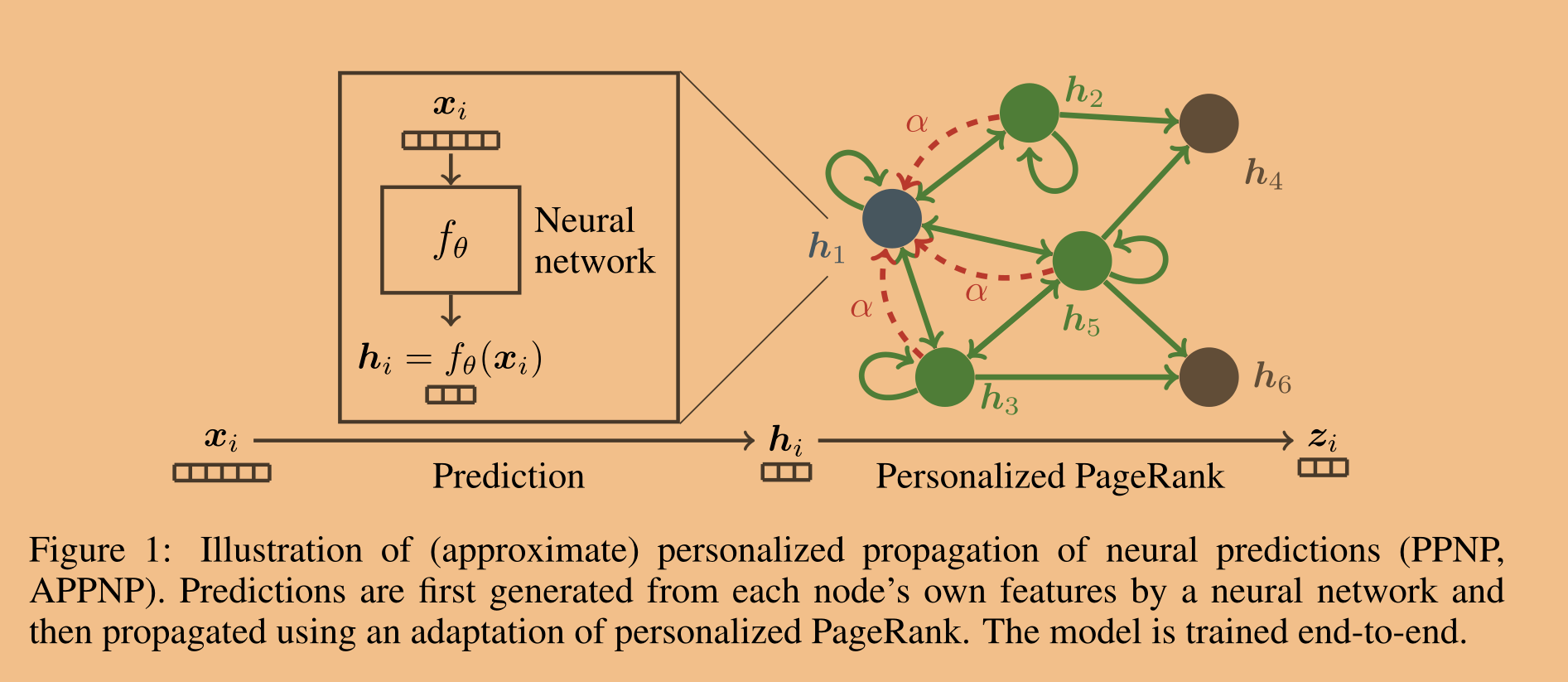
神经预测(PPNP,APPNP)的(近似)个性化传播图解。预测首先由神经网络从每个节点自身的特征中产生,然后使用个性化PageRank的改编来传播。该模型经过端到端的训练。
3.神经预测的个性化传播
From message passing to personalized PageRank.从消息传递到个性化的PageRank。我们可以通过认识到极限分布和PageRank之间的联系来解决焦点丢失的问题(Page等人,1998)。这两者之间的唯一区别是添加的自循环和ˆ˜A中的邻接矩阵归一化。原始页面排名是通过πPr=arwπPr来计算的,其中arw=AD−1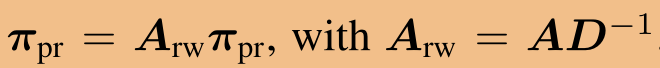 。在建立了这种连接之后,我们现在可以考虑使用将根节点考虑在内的页面排名的变体-个性化页面排名(Page等人,1998年)。我们通过远程传输向量ix定义根节点x,远程端口向量ix是一个热点指示符向量。
。在建立了这种连接之后,我们现在可以考虑使用将根节点考虑在内的页面排名的变体-个性化页面排名(Page等人,1998年)。我们通过远程传输向量ix定义根节点x,远程端口向量ix是一个热点指示符向量。
A:从消息传递到个性化PageRank
我们可以通过识别极限分布和PageRank之间的联系来解决失去关注的问题。两者之间的唯一区别是在  中添加了自环和邻接矩阵归一化。
中添加了自环和邻接矩阵归一化。
原始的PageRank由  来计算。建立了这种连接之后,我们现在可以考虑使用PageRank的变体,该变体考虑了根节点——个性化PageRank。
来计算。建立了这种连接之后,我们现在可以考虑使用PageRank的变体,该变体考虑了根节点——个性化PageRank。
我们经由传送向量  (它是一个one-hot的指示向量)定义根节点
(它是一个one-hot的指示向量)定义根节点  。我们对个性化PageRank的调整可以使用递归方程为节点 x 获得:
。我们对个性化PageRank的调整可以使用递归方程为节点 x 获得:
通过求解这个等式,我们可以获得:
指示向量 可以使我们即使在极限分布中也可以保留节点的本地邻域。
可以使我们即使在极限分布中也可以保留节点的本地邻域。
在该模型中,根节点x对节点y的影响分数I(x,y)与我们的个性化PageRank 的第y个元素成正比。该值对于每个根节点都是不同的。当我们离开根节点时,它下降的速度可以通过α进行调整。通过用单位矩阵
的第y个元素成正比。该值对于每个根节点都是不同的。当我们离开根节点时,它下降的速度可以通过α进行调整。通过用单位矩阵 替换指示符向量
替换指示符向量 ,我们获得了完全个性化的页面排名矩阵
,我们获得了完全个性化的页面排名矩阵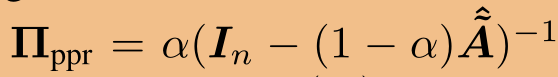 ,其元素(yx)指定节点x对节点y,
,其元素(yx)指定节点x对节点y,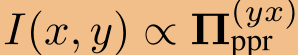 的影响分数。请注意,由于对称性
的影响分数。请注意,由于对称性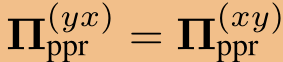 ,即x对y的影响等于y对x的影响。这个逆从
,即x对y的影响等于y对x的影响。这个逆从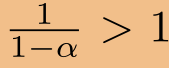 开始总是存在的,因此不可能是
开始总是存在的,因此不可能是 的特征值(见附录A)。
的特征值(见附录A)。
B:Personalized propagation of neural predictions (PPNP).
为了将上述影响力分数用于半监督分类,我们根据每个节点的自身特征生成预测,然后通过完全个性化的PageRank方案传播它们,以生成最终预测。 这是神经预测个性化传播的基础。
PPNP模型可以描述成如下等式: 

其中,X是特征矩阵,  是一个带有参数θ的生成预测结果
是一个带有参数θ的生成预测结果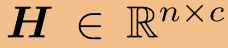 的神经网络。请注意,fθ独立地对每个节点的特征进行操作,从而允许并行化。此外,可以用任何传播矩阵(例如
的神经网络。请注意,fθ独立地对每个节点的特征进行操作,从而允许并行化。此外,可以用任何传播矩阵(例如 )替换
)替换 。
。
PPNP从传播方案中分离出了用于生成预测的神经网络。 这种分离还解决了上面提到的第二个问题:神经网络的深度现在完全独立于传播算法。 正如我们在将GCN连接到PageRank时所看到的那样,个性化PageRank甚至可以有效地使用无限多个邻域聚合层,这在传统消息传递框架中显然是不可能的。 此外,分离使我们可以灵活地使用任何方法来生成预测,例如 用于图像图形的深层卷积神经网络。
在生成预测并在预测过程中连续进行预测传播时,该模型是端到端训练的。 也就是说,梯度在反向传播过程中流经传播方案(隐式考虑了无限多个邻域聚合层)。 添加这些传播效果会大大提高模型的准确性。
C:Efficiency analysis.
直接计算完全个性化的页面排名矩阵Πppr,计算效率低并且导致密集的 矩阵。使用该矩阵将导致训练和推理的计算复杂度和内存需求为O(N2)。
矩阵。使用该矩阵将导致训练和推理的计算复杂度和内存需求为O(N2)。
要解决此问题,请重新考虑等式Z=α(in−(1−α)ˆ˜A)−1H.。与其把这个等式看作是密集的完全个性化的PageRank矩阵和预测矩阵的组合,我们还可以把它看作主题敏感PageRank的变体,每个类别对应一个主题(Haveliwala,2002)。在这个视图中,H的每一列都定义了一个节点上的(非标准化)分布,该分布充当一个传送集。因此,我们可以通过主题敏感PageRank的近似计算来近似PPNP。
D:Approximate personalized propagation of neural predictions (APPNP)
更 准确地说,APPNP通过通过幂迭代逼近主题感知的PageRank来实现线性计算复杂性。 虽然PageRank的功效迭代与常规的随机游走相关,但与主题相关的PageRank的功效迭代与重新启动的随机游走有关。 因此,主题感知的PageRank变体的每次幂迭代(随机遍历/传播)步骤都可以通过下式计算:
其中,预测矩阵H既是起始向量又是传送集,K定义迭代步数,并且  。 请注意,此方法保留了图的稀疏性,并且从不构造
。 请注意,此方法保留了图的稀疏性,并且从不构造  矩阵。
矩阵。
请注意,与GCN这样的模型不同,该模型的传播方案不需要训练任何其他参数,而GCN这样的模型通常每个附加传播层都需要更多参数。 因此,我们可以使用很少的参数传播很远。我们的实验表明,这种能力确实非常有益(见第6节)。因此,在消息传递框架中表达的类似模型将无法实现相同级别的性能。A similar model expressed in the message passing framework would therefore not be able to achieve the same level of performance.
PPNP通过定点迭代的重新表述说明了与原始图形神经网络(GNN)模型的联系(Scarselli等人,2009年)。后者使用学习的定点迭代,而我们的方法使用预定的迭代(自适应个性化PageRank),并在传播之前应用学习的特征变换。
在PPNP和APPNP中,影响每个节点的邻域大小都可以通过传送概率α来调整。选择α的自由使我们能够针对不同类型的网络调整模型,因为不同的图形类型需要考虑不同的邻域大小,如第6节所示,Grover&Leskovec(2016年)和Abu-El-Haija等人对此进行了描述。(2018b)。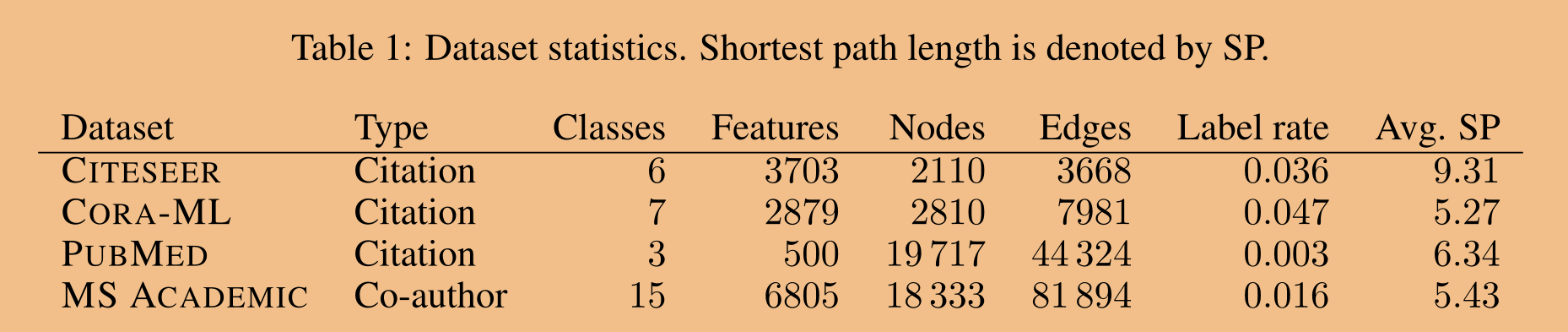
4 相关工作
有几项工作试图改善消息传递算法的训练,并通过添加跳过连接skip connections 来增加每个节点处的可用邻域(Li等人,2016;Pham等人,2017;Hamilton等人,2017;Ying等人,2018)。最近的一种方法将跳过连接与聚合方案相结合(Xu等人,2018年)。然而,这些模型的范围仍然有限,这一点从使用的消息传递层数量较少中可见一斑。虽然可以在算法使用的神经网络中添加跳过连接,但这不会影响传播方案。因此,我们解决射程问题的方法与这些模型无关。
Li等人(2018)通过将消息传递与共同训练和自我训练相结合来促进训练。这种组合实现的改进与其他半监督分类模型的报告结果相似(Buchnik & Cohen, 2018)。请注意,大多数算法,包括我们的算法,都可以使用自我训练和共同训练来改进。然而,这些方法所使用的每一个额外步骤都对应着一个完整的训练周期,因此大大增加了训练时间。
最近的工作中提出了通过将剩余(跳过)连接与批归一化相结合来避免过度平滑问题的深层GNN(Kawamoto等人,2018年;Chen等人,2019年)。然而,我们的模型通过解耦预测和传播来简化体系结构,从而解决了这个问题,并且不依赖于会使模型进一步复杂化并引入额外超参数的ad-hoc技术。此外,由于PPNP在不引入附加层和参数的情况下增加了射程,因此与深度GNN相比,训练更容易、更快。
5 实验设置
近年来,由于训练设置的变化和过度拟合,许多实验评价都存在表面的统计评价和实验偏差。后者是由使用单个训练/验证/测试拆分的实验、不清楚区分验证和测试集以及对每个数据集甚至单独的数据拆分微调超参数造成的。消息传递算法对数据拆分和权重初始化都非常敏感(我们的评估清楚地表明了这一点)。因此,一个精心设计的评估方案是极其重要的。我们的工作旨在建立这样一个彻底的评估方案。
首先,我们在多个随机拆分和初始化上运行每个实验100次。其次,我们将数据分成可见集和测试集,这两个集不会改变。测试集仅用于报告最终性能一次;尤其是,从未用于执行超参数和模型选择。为了进一步防止过拟合,我们在数据集中使用相同的层数和隐藏单元数、丢失率d、L2正则化参数λ和学习率l,因为所有数据集都使用词袋作为特征。为了防止实验偏差,我们在CITESEER和CORA-ML上分别使用网格搜索优化了所有模型的超参数,并在模型之间使用相同的提前停止准则。
最后,为了确保实验设置的统计稳健性,我们通过自举计算了置信区间,并报告了主要索赔的配对t-检验的p值。据我们所知,这是迄今为止对类GCN模型进行的最严格的研究。附录C提供了有关实验装置的更多详细信息。(这段话看不懂)
Dataset 数据集。我们使用四个文本分类数据集进行评估。CITESEER(Sen等人,2008年)、CORA-ML(McCallum等人,2000;Bojchevski&Günnemann,2018)和PubMed(Namata等人,2012)是引文图,其中每个节点代表一篇论文,边代表它们之间的引用。在微软的学术图表(Shchur等人,2018年)中,边代表合作关系。我们使用每个图的最大连通分量。所有图表都使用文字袋表示论文摘要作为特征。
虽然大图不一定具有更大的直径(Leskovec等人,2005年),但请注意,这些图确实具有5到10之间的平均最短路径长度,因此常规的两层GCN不能覆盖整个图。表1报告了数据集统计数据。
Baseline models.基线模型。我们与五种最先进的模型进行比较。GCN(Kipf & Welling,2017),GCN网络(N-GCN)(Abu-El-Haija等人,2018a),图注意网络(GAT)(Veliˇckovi´c等人,2018),自举特征传播(bt.FP)(Buchnik & Cohen,2018)和跳跃知识网络与串联(JK)(Xu等人,2018)。对于GCN,我们还展示了(未经优化的)vanilla版本(V. GCN)的结果,以证明早期停止和超参数优化的强大影响。所有模型的超参数都列在附录D中。
GCN (Kipf & Welling, 2017), network of GCNs (N-GCN) (Abu-El-Haija et al., 2018a), graph attention networks (GAT) (Veliˇckovi´c et al., 2018), bootstrapped feature propagation (bt. FP) (Buchnik & Cohen, 2018) and jumping knowledge networks with concatenation (JK) (Xu et al., 2018).
Model hyperparameters.模型超参数。为了确保公平的模型比较,我们使用了一个神经网络来进行PPNP,它在结构上非常类似于GCN,并且具有相同数量的参数。我们使用两层,h=64个隐藏单元。我们在第一层的权值上应用λ=0.005的L2正则化,在两层和邻接矩阵上使用丢包率d=0.5的丢包率。对于APPNP,每个幂迭代步骤都会对邻接丢弃进行重采样。对于传播,我们对APPNP使用传送概率α=0.1和K=10次幂迭代步骤。由于结构上的差异,我们在微软学术图表上使用α=0.2(参见图5及其讨论)。这种浅层神经网络与相对较高的幂迭代步数相结合,在超参数优化过程中取得了最好的效果(见附录G)。
6 结果
总体准确度。表2总结了精度(微观F1得分)的结果。宏观F1得分也有类似的趋势(见附录E)。这两个模型在所有数据集上的表现都明显优于最先进的基准模型。我们的严格设置可能低估了PPNP和APPNP实现的改善-这一结果在统计学上具有显著性p<0.05,通过配对t检验进行了检验(见附录F)。这种彻底的设置进一步表明,当协调训练、适当优化超参数和考虑多数据拆分时,最近工作报告的优势实际上消失了。具有优化超参数的简单GCN在我们的设置上优于最近提出的几个模型。
平均准确度,不确定性显示了通过自举法计算的95%的置信度。之前报道的改进在我们严格的实验设置中消失了,而PPNP和APPNP在所有数据集上的表现都明显优于比较的模型。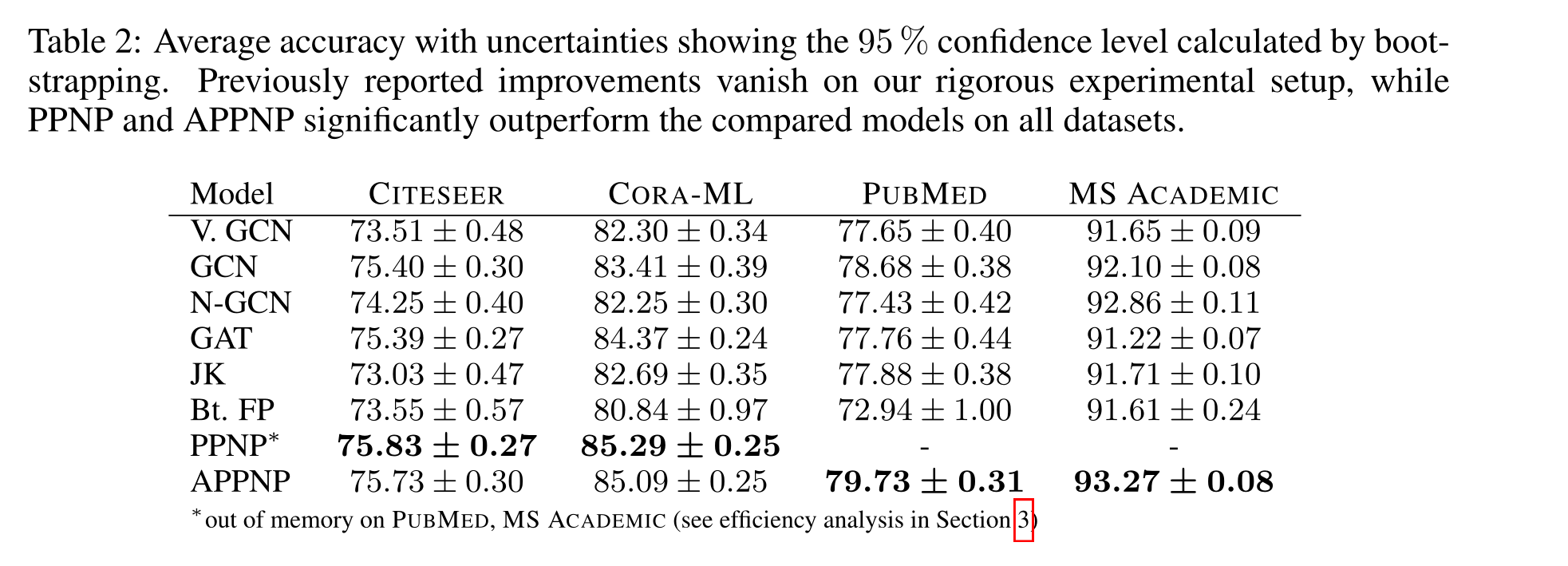
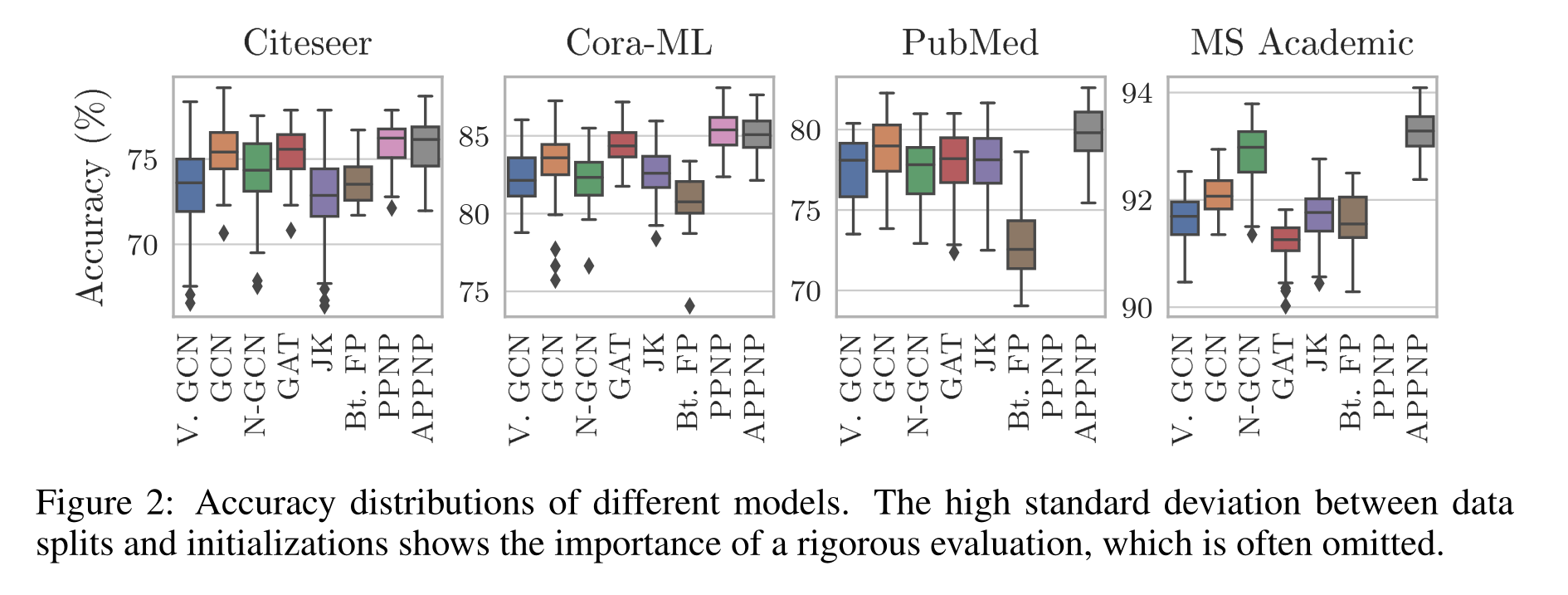
不同模型的精度分布。数据拆分和初始化之间的高标准偏差表明了严格评估的重要性,这一点经常被忽略。
图2显示了每个模型的精度分布有多广。这是由随机初始化和不同的数据分割(训练/早停/测试)造成的。这表明统计上严格的评估对于决定性的模型比较是多么重要。此外,它还显示了每种方法的灵敏度(稳健性),例如PPNP、APPNP和GAT通常具有较低的方差。
Training time per epoch.每个epoch的训练时间。我们在表3中报告了每个epoch的平均训练时间。我们决定只比较每个epoch的训练时间,因为所有的超参数都经过了单独的精确度优化,而且使用的提前停止标准非常宽松。显然,(精确的)PPNP只能应用于中等大小的图表,而APPNP则适用于大数据。平均而言,APPNP比GCN慢约25%,因为它的矩阵乘法次数更多。它的可伸缩性与GCN的图形大小相似,因此比GAT等其他更复杂的模型要快得多。这是可以观察到的,尽管与参考实现相比,我们的实现将GAT的培训时间改进了大约2倍。
表3:每个epoch的平均训练时间。PPNP和APPNP仅比GCN稍慢,比GAT等更复杂的方法快得多。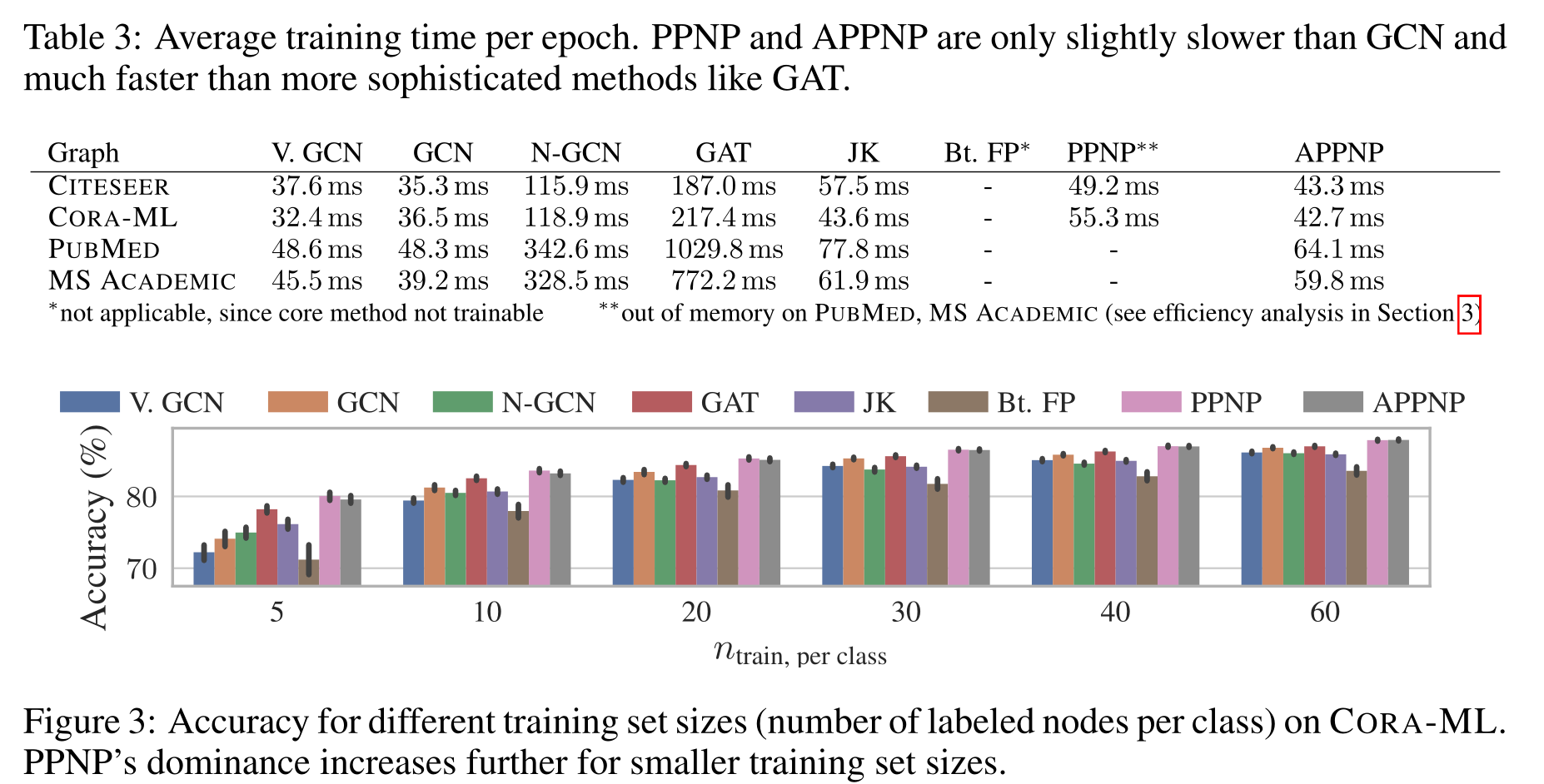
图3:CORA-ML上不同训练集大小(每类标记节点数)的准确性。随着训练集规模的减小,PPNP的优势进一步增强。
Training set size.训练集大小。由于真实数据集的标签率通常很低,因此研究模型在少量训练样本下的性能是非常重要的。图3显示了每类的训练节点数量 如何影响CORA-ML的准确性(其他数据集请参见附录H)。在这种稀疏的标记环境中,PPNP和APPNP的优势进一步增加。这可以归因于它们更大的范围,这允许它们更好地传播信息,远离(几个)训练节点。当比较APPNP和GCN的准确性时,我们看到了进一步的证据,这取决于节点和训练集之间的距离(就最短路径而言)。附录I显示,对于远离训练节点的节点,APPNP和GCN之间的性能差距趋于增大。也就是说,距离训练集越远的节点从范围的增加中受益越多。
如何影响CORA-ML的准确性(其他数据集请参见附录H)。在这种稀疏的标记环境中,PPNP和APPNP的优势进一步增加。这可以归因于它们更大的范围,这允许它们更好地传播信息,远离(几个)训练节点。当比较APPNP和GCN的准确性时,我们看到了进一步的证据,这取决于节点和训练集之间的距离(就最短路径而言)。附录I显示,对于远离训练节点的节点,APPNP和GCN之间的性能差距趋于增大。也就是说,距离训练集越远的节点从范围的增加中受益越多。
Number of power iteration steps.幂迭代步数。图4显示了精确度如何依赖于两种不同传播方案的功率迭代次数。第一种方法模仿GCNS中已知的标准传播(即APPNP中的α=0)。正如清楚地显示的那样,性能随着幂迭代次数K的增加而下降(因为我们接近全局PageRank解决方案)。然而,当使用个性化传播(α=0.1时)时,准确率提高,并且收敛到具有无限多个传播步骤的精确PPNP,从而证明个性化传播原理确实是有益的。如图所示,使用适度次数的幂迭代(例如K=10)就足以有效地近似精确的PPNP。有趣的是,我们发现这个数字与任何节点到训练集的最短路径距离重合。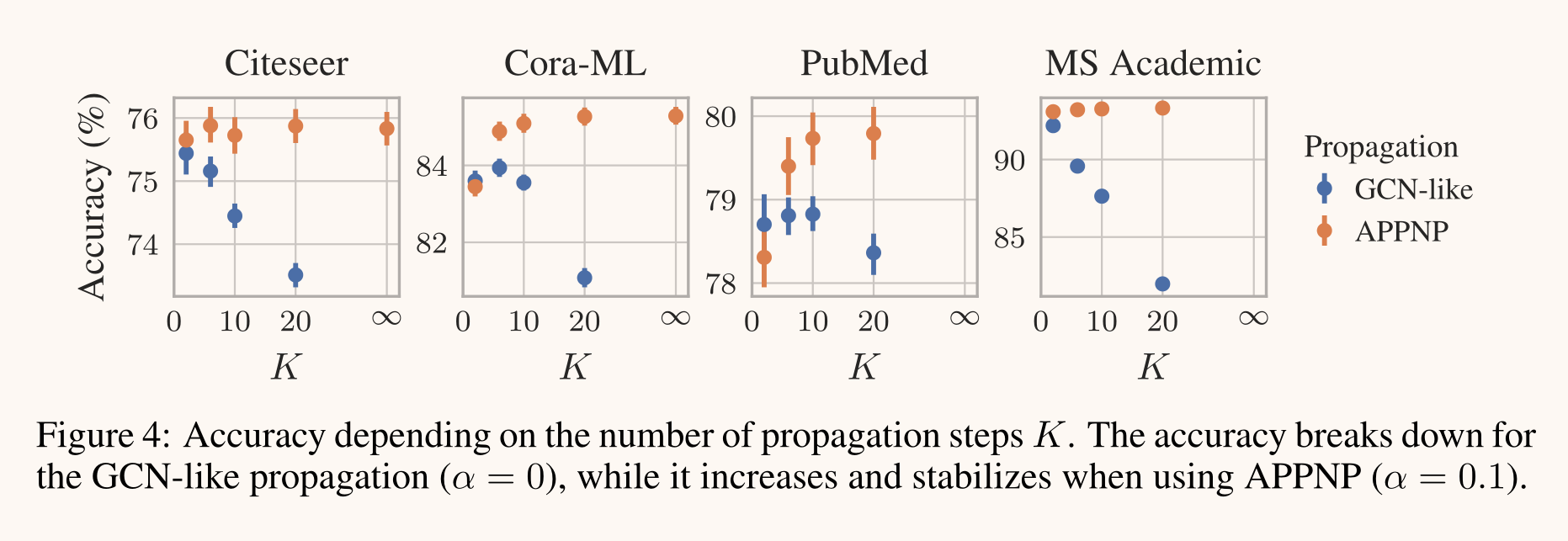
Teleport probability α.传送概率α。图5显示了超参数α对验证集精度的影响。虽然每个数据集的最佳传输概率略有不同,但我们始终发现传输概率在α∈[0.05,0.2]左右表现最好。对于调查中的数据集,这一概率应该进行调整,因为不同的图表显示出不同的邻域结构(Grover&Leskovec,2016;Abu-El-Haija等人,2018b)。请注意,α越高,收敛速度越快。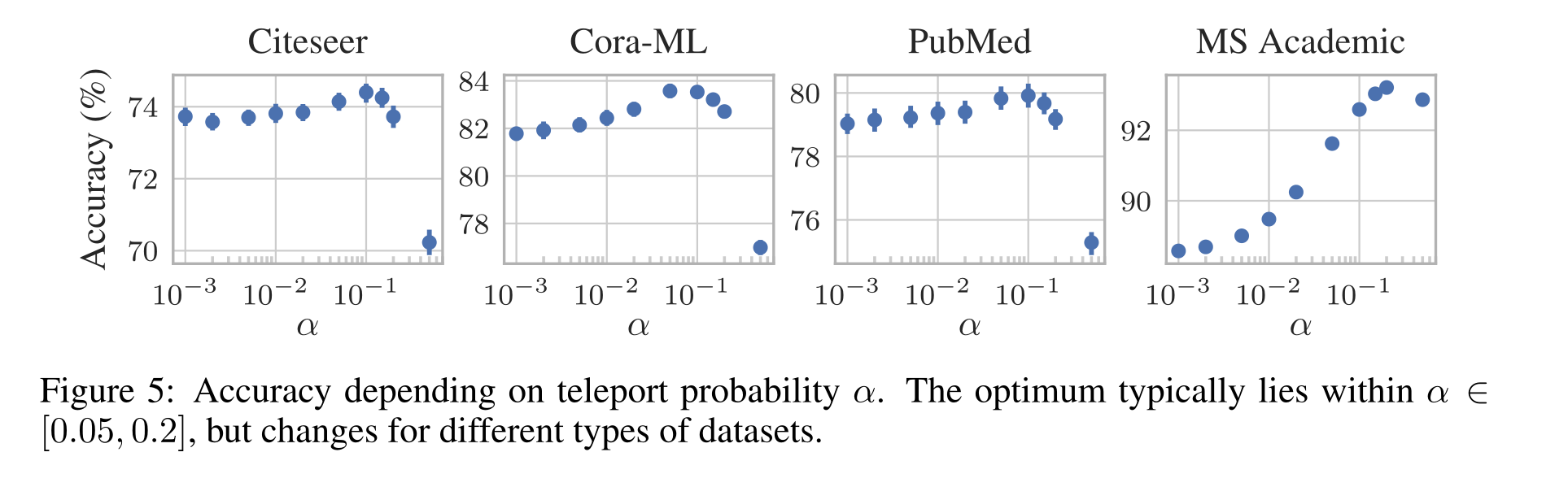
Neural network without propagation. 无传播的神经网络。PPNP和APPNP是端到端训练的,传播策略影响(I)训练过程中的θ神经网络和(Ii)推理过程中的分类决策。通过调查模型在没有传播的情况下如何执行,可以看出这种添加是否有价值以及有多大价值。图6显示了传播如何影响训练和推理。“从不”表示不使用传播的情况;实质上,我们仅使用这些特征来训练和应用标准的多层感知器fθ。“训练”表示在训练期间使用APPNP来学习fθ的情况;然而,在推理时,只使用fθ来预测类别标签。相反,“推理”表示在没有APPNP的情况下训练fθ(即关于特征的标准mlp)。这个具有固定权值的预先训练的网络然后与APPNP的传播一起用于推理。最后,“Inf.。&Training“表示常规的APPNP,它总是使用传播。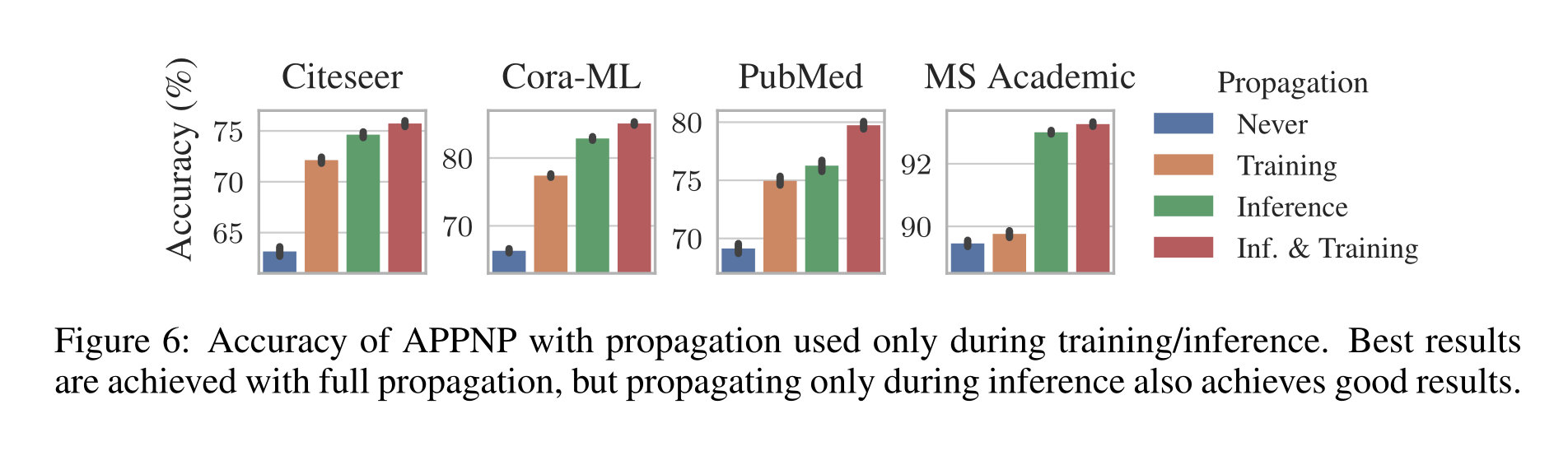
用常规的APPNP得到了最好的结果,这验证了我们的方法。然而,在大多数数据集上,当仅在推理过程中传播时,准确率下降的幅度令人惊讶地微乎其微。在训练期间跳过传播可以显著减少大型图的训练时间,因为所有节点都可以独立处理。这也表明,我们的模型可以与不包含任何图形信息的预先训练的神经网络相结合,并且仍然可以显著提高它们的精度。此外,图6显示,仅仅在培训期间进行传播也可以带来很大的改进。这表明,我们的模型也可以应用于在线/归纳学习,在这种学习中,只有输入(以前未观察到的)节点的特征而不是邻域信息可用。
7 结论
本文介绍了神经预测的个性化传播算法(PPNP)及其快速逼近算法APPNP。我们通过考虑GCN和PageRank之间的关系并将其扩展到个性化PageRank来推导该模型。这个简单的模型将预测和传播解耦,并且在不引入任何额外参数的情况下解决了许多消息传递模型中固有的有限范围问题。它使用来自一个大的、可调整的(通过远程传送概率α)邻域的信息来对每个节点进行分类。该模型具有较高的计算效率,优于目前已有的多图半监督分类方法,这是迄今为止对类GCN模型进行的最深入的研究。
对于未来的工作,将PPNP与更复杂的神经网络相结合将是有趣的,例如在计算机视觉或自然语言处理中使用。此外,个性化PageRank的更快或增量近似(Bahmani等人,2010;2011;Lofgren等人,2014)和更复杂的传播方案也将对该方法有利。

若有收获,就点个赞吧
0 人点赞
