Medium链接:(会员)https://towardsdatascience.com/learning-on-graphs-with-missing-features-dd34be61b06
大多数图神经网络通常在所有节点都可用的全套特征的假设下运行。在现实世界的场景中,功能通常只有部分可用(例如,在社交网络中,只有一小部分用户可以知道年龄和性别)。我们展示了特征传播是一种有效且可扩展的方法,用于处理图机器学习应用程序中缺失的特征,尽管它很简单,但效果出奇地好。
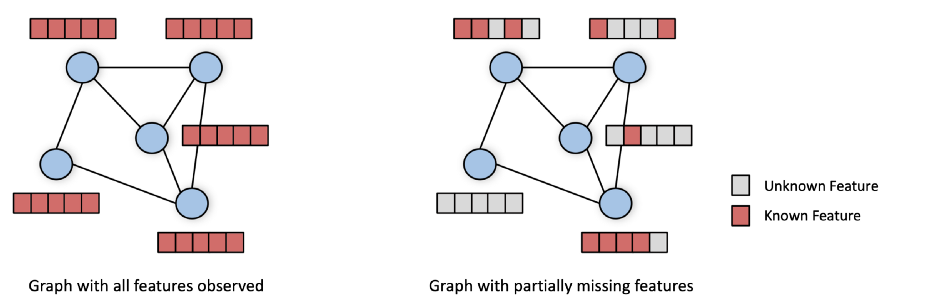
大多数图神经网络期望输入一个图,每个节点都有一个完整的特征向量(左)。一个更常见的现实世界场景是只有部分功能可用(右图)。
这篇文章是与Emanuele Rossi合着的。
Graph 神经网络 (GNN) 模型通常假设每个节点都有一个完整的特征向量。以一个 2 层 GCN 模型 [1] 为例,它具有以下形式:
Z = A σ ( AXW ₁) W 2
该模型的两个输入是(标准化)邻接矩阵A编码图结构和特征矩阵X包含作为行的节点特征向量并输出节点嵌入Z。GCN 的每一层都执行节点特征变换(由可学习矩阵W 1 和W 2 参数化),然后将变换后的特征向量传播到相邻节点。重要的是,GCN 假设X中的所有条目都被观察到。
在现实世界的场景中,我们经常会看到一些节点特征可能丢失的情况。例如,年龄、性别等人口统计信息可能仅对一小部分社交网络用户可用,而内容特征通常仅对最活跃的用户提供。在共同购买网络中,并非所有产品都有与之相关的完整描述。这种情况变得更加严重,随着人们对数字隐私的认识不断提高,越来越多的数据只有在用户明确同意的情况下才能获得。
在上述所有情况下,特征矩阵都有缺失值,大多数现有的 GNN 模型都不能直接应用。最近的几项工作派生了能够处理缺失特征的 GNN 模型(例如 [2-3]),但是这些模型在缺失特征率很高(>90%)的情况下受到影响,并且不能扩展到具有超过几百万条边的图.
在在与 Maria Gorinova、Ben Chamberlain (Twitter)、Henry Kenlay 和 Xiaowen Dong (Oxford) 合着的一篇新论文 [4] 中,我们提出了特征传播 (FP) [4] 作为一种简单但高效且令人惊讶的有效解决方案问题。简而言之,FP 通过在图上传播已知特征来重构缺失的特征。然后可以将重建的特征输入任何 GNN 以解决下游任务,例如节点分类或链接预测。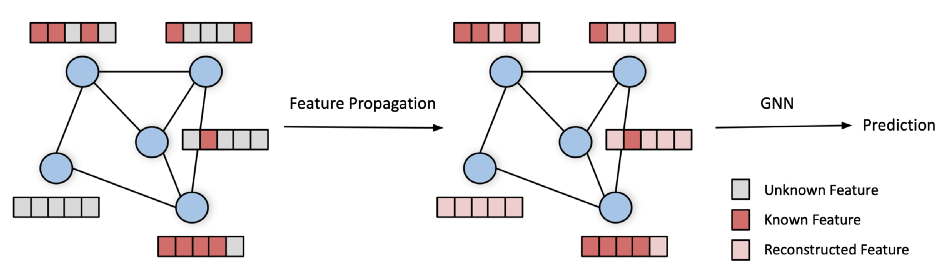
特征传播框架。输入是缺少节点特征的图(左)。在初始步骤中,特征传播通过迭代地扩散图中的已知特征来重构缺失的特征(中)。随后,图和重建的节点特征被输入到下游 GNN 模型中,然后产生预测(右)。
传播步骤非常简单:首先,未知特征用任意值初始化[5]。通过应用(归一化的)邻接矩阵来传播特征,然后将已知特征重置为其真实值。我们重复这两个操作,直到特征向量收敛[6]。
特征传播是一种简单且令人惊讶的强大方法,用于在缺少特征的图上进行学习。特征的每个坐标都被单独处理(x表示X的一列)。
FP 可以从数据同质性(“平滑性”)的假设中推导出来,即邻居倾向于具有相似的特征向量。同质性的水平可以使用狄利克雷能量来量化,这是一种测量节点特征与其邻居平均值之间的平方差的二次形式。Dirichlet 能量[7] 的梯度流是图热扩散方程,以已知特征作为边界条件。FP 是使用具有单位步长的显式前向 Euler 方案作为该扩散方程的离散化获得的 [8]。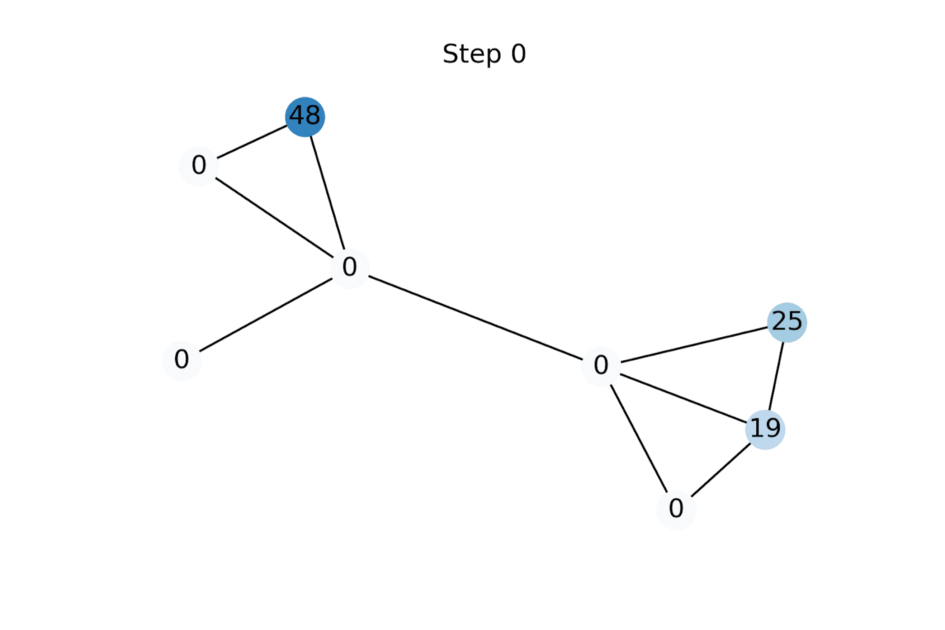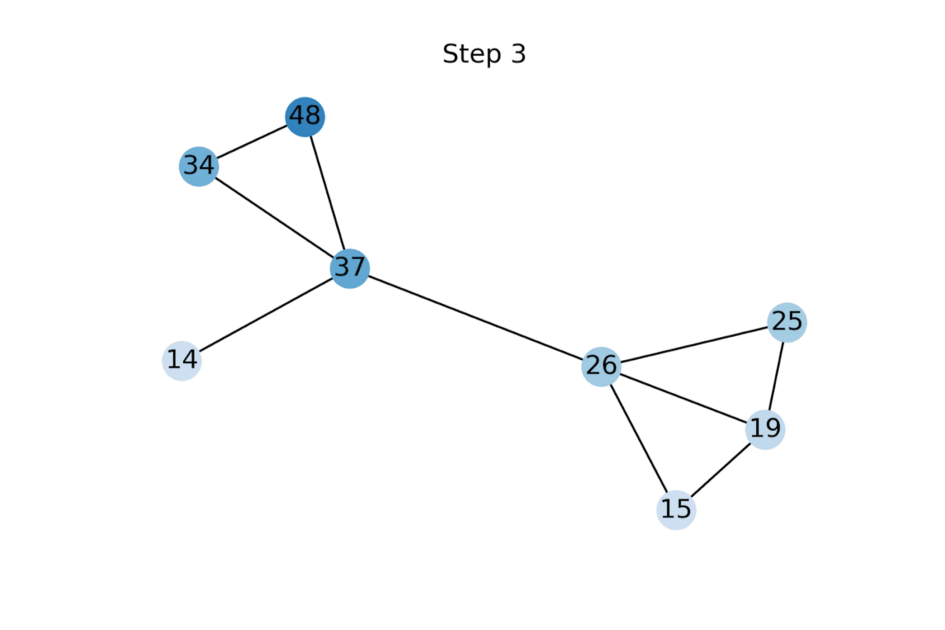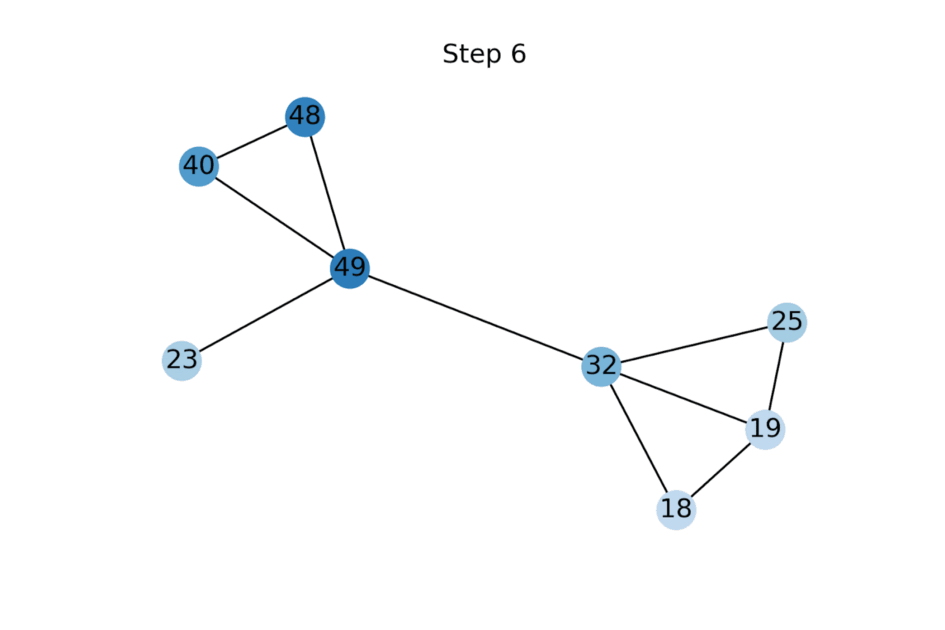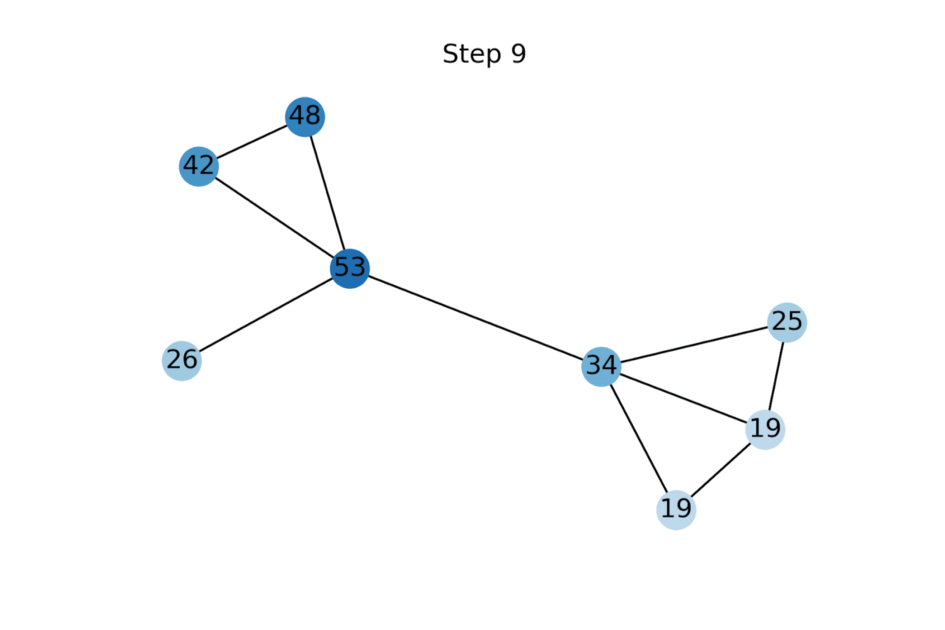
动画展示了随着特征传播的更多迭代应用而标量节点特征的演变示例。未知特征被初始化为零,但很快收敛到使给定图上的狄利克雷能量最小化的值。
特征传播与标签传播(LP)[9]相似。然而,关键的区别在于 LP 是一种与特征无关的方法,它通过传播图中的已知标签直接预测每个节点的类。另一方面,FP 用于首先重建缺失的节点特征,然后将其馈送到下游 GNN。这使得 FP 能够利用观察到的特征,并在我们试验的所有基准测试中都优于 LP。此外,在实践中经常发生带有标签的节点集和带有特征的节点集不一定完全重叠,因此这两种方法并不总是可以直接比较。
我们使用七个标准节点分类基准对 FP 进行了广泛的实验验证,其中我们随机删除了可变部分的节点特征(独立于每个通道)。FP 后跟一个 2 层 GCN 在重建特征上的表现明显优于简单的基线以及最新的最先进的方法 [2-3]。
FP 在特征缺失率高 (>90%) 的情况下尤为突出,而所有其他方法往往会受到影响。例如,即使丢失了 99% 的特征,与所有特征都存在的相同模型相比,FP 平均仅损失约 4% 的相对准确度。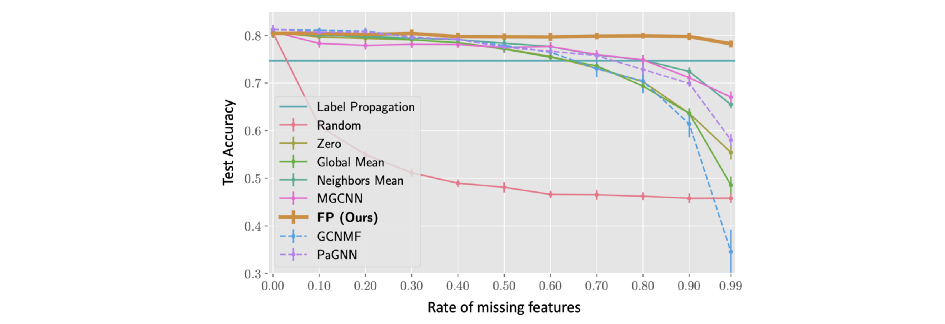
Cora 数据集上不同特征缺失率的节点分类准确度(从 0% 是大多数 GNN 的标准状态到 99% 的极端情况)。
FP 的另一个关键特性是它的可扩展性。虽然竞争方法无法扩展到具有几百万条边的图之外,但 FP 可以扩展到十亿条边的图。我们用了不到一小时的时间在我们的内部 Twitter 图表上运行它,使用单台机器大约有 10 亿个节点和 100 亿条边。
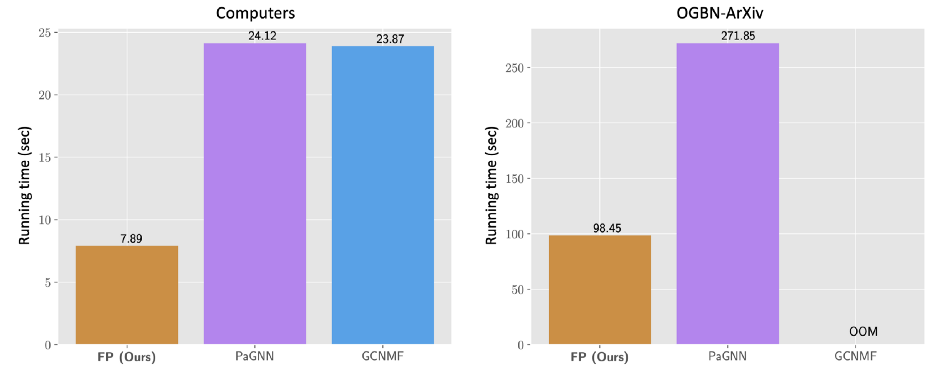
FP+GCN 和最新最先进的方法 GCNMF 和 PaGNN [2-3] 的运行时间(以秒为单位)。FP+GCN 比其他两种方法快 3 倍。GCNMF 在 OGBN-Arxiv 上出现内存不足 (OOM),而 GCNMF 和 PaGNN 在 OGBN-Products(约 123M 边)上出现 OOM,其中 FP 的重建部分(无需训练下游模型)仅需约 10 秒。
一个FP 的当前限制之一是它不能很好地处理异嗜图,即邻居倾向于具有不同特征的图。这并不奇怪,因为 FP 源自同质假设(通过扩散方程最小化 Dirichlet 能量)。此外,FP 假设不同的特征通道是不相关的,这在现实生活中很少见。通过替代更复杂的扩散机制,可以同时满足这两个限制。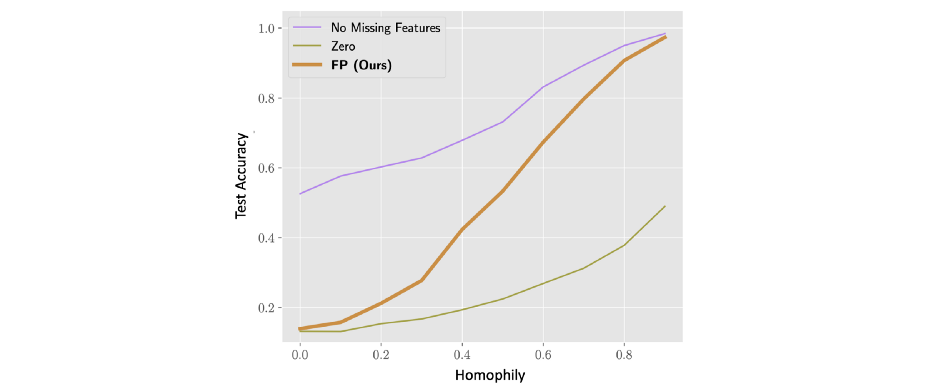
当 99% 的特征缺失时,具有各种同质性水平的合成图上的节点分类准确度(0 是极度异质性,1 是极度同质性)。虽然在高度同质性设置中 FP 的表现几乎与具有完整特征的情况一样好,但在低同质性设置中,两者之间的差距很大,并且 FP 的性能恶化到一个简单的基线,其中缺失的特征被替换为零。
尽管在实际应用中无处不在,但在缺少节点特征的图上获得收益是一个几乎未被探索的研究领域。我们相信,我们的特征传播模型是提高在缺少节点特征的图上学习能力的重要一步。它还提出了关于在这种情况下学习的理论能力的深刻问题,作为关于信号和图结构的假设的函数。FP 的简单性和可扩展性,以及与更复杂的方法相比的惊人的好结果,即使在极端缺失的特征状态下,也使其成为大规模工业应用的良好候选者。

若有收获,就点个赞吧
0 人点赞
