From thousands to billions: An overview of methods for scaling Graph Neural Networks
Medium链接(需要会员)
表征学习也被称为特征学习,是一种专注于学习数据表征的机器学习专业。这些表征的目的是捕捉对建立预测模型有用的内在因素。也就是说。
“学习数据的表征,使其在建立分类器或其他预测器时更容易提取有用的信息。”
在这篇文章中,我们对图数据的表示学习感兴趣,重点是可扩展性,也就是适用于大型图。我们认为大图是指有1000万个或更多节点的图。作为一个例子,比特币交易网络有数十亿个节点,对应于加密货币持有人之间的交易。通常情况下,边的数量将是图中节点数量的数倍。
为了解释主要概念,我们将使用一个引证网络作为一个工作例子。让我们考虑利用论文的文本内容和引用链接的信息来预测一篇研究论文的主题的问题。Cora(见图1)是一个研究得很好的引文网络,其中节点代表与表明一小部分词(词汇)存在或不存在的特征向量相关的论文。节点之间的边代表引文关系。每篇论文被标记为6个主题中的一个。节点特征向量的维度为1453,节点和边的总数分别约为2700和5400。严格来说,这不是一个大的数据集,但它很容易理解和可视化,并且在机器学习文献中经常被用作基准,因此它是本文的一个很好的选择。我们的目的是训练一个多类分类模型来预测论文的主题。

Figure 1: Visualisation of the Cora citation network. Node colours indicate the paper’s subject (one of seven) and node size the degree (number of neighbours.)
有几种表示图的数据结构,每一种都有自己的优势和劣势.我们用它的邻接矩阵A来表示一个图。。在一般情况下,一个图有N个节点和E条边,一个二进制邻接矩阵的大小是N×N(对Cora来说是2700×2700),它将有E个非零条目。现实世界的图往往是稀疏的,这样的边数(Cora为5400)远远小于可能的边数总数。一个完全连接的无定向图将有N(N-1)/2(对Cora来说约为360万)条边。因为图是稀疏的,A可以使用稀疏矩阵表示法非常有效地存储在内存中。
节点特征可以存储在一个大小为N×d的密集矩阵中,其中d是节点特征向量的维度。对于Cora,特征矩阵X的大小为2700 x 1453。请注意,这是一个密集的矩阵,所以不可能使用稀疏矩阵表示法进行有效的存储。
我们应该牢记上述存储要求和数据矩阵的大小,因为我们需要它们来计算不同图表示学习算法的存储和计算要求。
GCN
图神经网络(GNN)是在图结构数据上进行表示学习的首选方法。图神经网络的文献很多,而且增长很快。我们从图卷积网络(GCNs)的概述开始探索可扩展的图表示学习,该方法启动了最近对GNNs的兴趣。然后,我们证明了为什么GCN是不可扩展的,然后调查了几个可扩展的方法。
GCN是作为ChebNet的一个可扩展版本提出的。我们不会进一步讨论GCN和以前的工作之间的关系,因为这超出了本文的范围。首先,我们介绍一下图卷积神经网络层的核心思想,其次我们研究一下它的内存和计算要求。
图卷积层是用以下简单的公式定义的。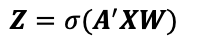
其中,Z是由该层输出的学习过的节点表征;X是节点特征矩阵;A’是加入了自循环的归一化图邻接矩阵;W是可学习的参数,σ是一个非线性函数,例如,sigmoid,逐元应用(applied element-wise)。
归一化的邻接矩阵由以下公式给出。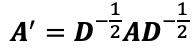
其中D是度数矩阵;度数矩阵是一个正方形的对角线矩阵,对角线存储了图中每个节点的程度(邻居的数量)。仔细研究计算Z的方程式可以发现,一个节点的表示是由其相邻节点的表示(它与边相连的那些节点)加上它自己的表示的加权和计算出来的。权重是节点度数的函数。
一个图卷积网络可以通过堆叠上述的一个或多个层来创建。最后一层的输出可以用来以半监督的方式训练一个节点分类器。通常,只有少数节点会有标签,所以我们把损失定义为这个有标签的节点子集的函数;但是,从上面的方程可以看出,在计算评估损失所需的节点表示时,我们会考虑图中所有的节点,无论是否有标签。
Why is GCN not scalable?
让我们考虑训练GCN模型的局限性。我们把讨论的重点放在一个3层模型上,这样第3层的输出节点表示就由。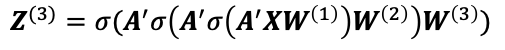
第i层产生一组节点嵌入,用Z^(i)表示,其中Z^(0)等于X,节点特征。
我们可以使用全批梯度下降法(full batch gradient descent)训练我们的3层模型。也就是说,每次都需要所有的节点信息来计算损失和梯度。 这是GCN的第一个限制。全批梯度下降法收敛缓慢,需要训练大量的epochs。由于这个原因,GCN的收敛性很差。它的计算成本也很高,需要对节点特征、邻接矩阵和权重矩阵进行乘法。最后,存储要求很高,因为我们需要存储节点特征和嵌入的密集矩阵作为每个图卷积层的输出。幸运的是,对于稀疏图来说,存储相邻矩阵可以有效地完成。简而言之,GCN的扩展性很差,原因有以下三个。
- 收敛速度慢。
- 计算昂贵的前向传递。
- 除了层权重之外,还需要大量的存储需求来存储每个图卷积层输出的密集节点表示。
How can we scale GCN to large graphs?
显然,如果我们希望类似GCN的模型能够扩展到更大的图形,那么我们就必须解决上述挑战。我们需要扩展GCN,使其能够使用小批量梯度下降法进行训练,减少每层的乘法次数,减少模型的大小,并存储更少的数据或尽量减少为每个小批量执行计算所需的数据量。接下来,我们介绍了扩展GCN以解决这些问题的模型。
邻域采样Neighbourhood sampling
让我们首先考虑通过调整GCN来解决上述所有的问题,以适应小批量训练。如果我们可以使用小批量梯度下降法进行训练,那么训练的收敛速度会更快,而且我们不必一次性将整个图形存储在GPU内存中,也许可以扩展到更大的图形。
如果我们考虑到图中影响输出节点的学习表示的节点数量,我们就可以实现这些目标。让N_c成为我们有标签的节点集合。通常情况下,有标签的节点集要比图中节点的总数小得多。
让我们只考虑Nc中的一个节点,并从3层图卷积网络中的最后一个图卷积层开始向后推进。我们将把这个感兴趣的节点称为中心节点。
我们可以看到,在第一层,直接影响中心节点的输出表示的节点是其一跳邻居。在第二层图卷积层影响输出表示的节点是一跳加两跳的邻居,第三层的输出也是如此。换句话说,在估计中心节点的表示时,需要考虑的节点集合随着网络深度(图卷积层的数量)的函数呈指数增长。这在文献中通常被称为邻域爆炸问题。
然而,计算中心节点的损失并不一定涉及图中的所有节点,而只是一个子集(其感受野中的节点集)。这个子集是k深度邻域中的节点集,其中k是我们GNN中图形卷积层的数量。这暗示了一个高效的小批量训练的解决方案。
我们可以消除很多不必要的计算(矩阵乘法),这些计算并不涉及估计mini-batch中的节点的损失;mini-batch是一个有标签的节点子集。
让我们再考虑一个有待解决的问题。如果一个节点的邻域包括一个中心节点,该怎么办?枢纽节点是指连接良好的节点,也就是在图中有很多邻居。这样的节点在现实世界的图中很常见,这些图表现出幂律的度分布(power law degree distributions);除了少数连接良好且具有高度的节点外,图中大多数节点的度都很小。后者就是枢纽节点。如果一个中心节点在小批量节点的k-hop邻域,那么图中的大部分节点都会影响该节点的学习表示。换句话说,对于现实世界的图,在最坏的情况下,对于迷你批中的每个节点,我们需要访问图中所有(或大多数)节点的数据。对我们来说,这又回到了原点。
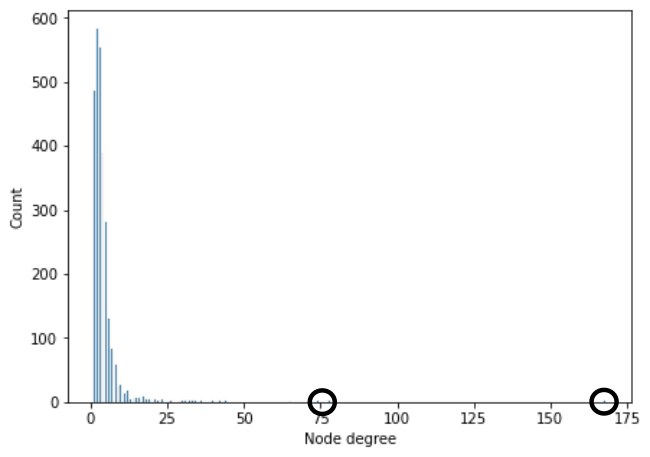
Figure 2: The node degree distribution for the Cora citation network. We can see that most nodes have degree less than 20. Circles indicate 3 hub nodes with degrees 74, 78, and 168.
研究人员为这个问题提出了一个优雅的解决方案,这个方案在实践中运行良好,并能很好地扩展到非常大的图形。该方法被称为 “图形采样和聚合”(Graph Sample and Aggregate,GraphSAGE)。
其核心思想是,我们不是从所有邻居那里汇总信息,而是对它们中的固定数量进行抽样,例如10。我们需要用替换法取样,这样,如果一个节点的邻居少于所需数量,我们仍然可以取到正确的数量,尽管有些节点可能被取样超过一次。当我们遇到一个中心节点时,我们不需要担心它有大量的邻居。最重要的是,在更新小型批次中单个节点的表示时,考虑到的图的大小现在被限制在一个容易计算的最大值。
如果我们为每个节点抽取m个邻居,并且我们有一个k层的图神经网络,那么我们总是需要m x k个节点。对于大小为b的迷你批次,节点的总数变成了b x m x k。我们可以选择b、m和k的值来充分利用GPU内存。只要我们有一个例行程序来快速采样图形并将其发送到GPU进行训练,我们就有了一个快速且非常可扩展的算法。有了GraphSAGE巧妙的节点采样方法,原始图的大小就不再重要了。
图采样Graph Sampling
节点采样无疑为可扩展的GNN铺平了道路。有一些替代方法可以实现类似的性能(就模型精度而言),在某些情况下甚至更有计算效率,因为它们允许将采样作为预处理步骤进行。这些方法专注于图形采样,而不是节点采样,作为将GNN扩展到大型图形的核心机制。
节点抽样是解决邻域爆炸问题的一个出色的方法。另一种避免这个问题的方法是首先保持图的大小。我们知道,GCN可以很容易地处理小图。那么,如果我们把我们的大图划分为一组GCN可以轻松处理的小图呢?如果我们把这些子图中的每一个都当作一个小型批次(假设每个子图都包括一个标记节点的子集),那么在一个训练时代,我们为每个子图更新一次GCN的参数。
我们将把图的分割部分看作是一个预处理步骤,可以执行一次,并有可能在分布式算法中实现,以减少其计算成本。然后,我们可以使用所描述的方法有效地训练GCN模型。剩下要说明的是如何划分图形,即什么是好的划分,以及后者的选择对我们训练的模型有什么影响(想想偏见和方差bias and variance)。
让我们把Cluster-GCN看作是通过图抽样实现可扩展GNN的第一个方法。在论文中,作者清楚地展示了Cluster-GCN比GCN的优势。Cluster-GCN当然是一种可扩展的算法,它可以处理任何大小的图,只要所述的图可以被有效地划分为一组子图。
作者考虑了两种不同的分区算法。一种是随机的;也就是每个子图由一个均匀随机的节点子集和这些节点之间的所有边组成。他们表明,随机分区的表现很差。然后他们考虑使用METIS图的分区算法METIS graph partitioning algorithm。METIS生成了一组子图,使得每个子图都是紧密连接的,而子图之间的边数是最小化的。METIS分区的表现大大优于随机分区。
然而,子图之间的边的损失(连接被分配到不同子图的节点的边)引起了一个强烈的bias,阻碍了模型的性能。因此,Cluster-GCN扩展了基本算法,即通过组合一组随机的子图(两个子图就够了)来构建一个mini-batch,在这个过程中重新引入图间边。对于每个epoch和每个mini-batch,组合的子图集是不同的,因此原始图中的所有边都有非零的机会被用来传播信息。这一改进对一些标准的基准数据集产生了最先进的结果。
Cluster-GCN的唯一问题是,使用METIS进行图形分割可能是一个非常昂贵的预处理步骤。不幸的是,这限制了Cluster-GCN对中等规模图形的适用性。此外,介绍Cluster-GCN的论文并没有对模型的偏差和方差进行仔细分析。这些问题被基于图形采样的归纳学习方法(GraphSAINT)所纠正。 https://www.thejournal.club/c/paper/209589/
GraphSAINT遵循我们已经描述过的图形分区和小批量训练的基本方法。它与Cluster-GCN的不同之处在于,它使用了一种更有效的图划分算法,并更仔细地处理了偏差和方差问题。
关于分区方法,GraphSAINT使用随机游走。随机游走很容易实现和并行化。给定一个图形节点,通过跟踪随机选择的出站边缘来生成一个随机游走。每次跟踪一条边时,随机游走器都会发出节点的标识符。然后,它继续选择另一条边进行跟踪,以此类推,直到指定的步数(一个需要调整的超参数)。在随机游走结束后,我们产生了一组节点标识符。这些节点和它们之间的边构成一个子图。通常情况下,一个子图将是几个从不同节点开始的随机游走的结果。随机游走的计算效率很高,实现起来很简单,而且很容易并行化。因此,这个预处理步骤比使用METIS这样的分区算法要便宜得多。
为了解决偏差问题,GraphSAINT建议使用GCN层计算的节点表示乘以一个系数,以纠正分区算法引起的偏差。此外,损失也被一个易于计算的因子所纠正。这些系数是采样节点和边的概率的函数。每个节点和边的这些概率可以在图形分区的预处理步骤中估计出来,从而一石二鸟。差异可以通过使用边缘分布的启发式估计(给定边缘被抽样的概率)对子图进行抽样来控制。这个启发式方法只是那些由边缘连接的节点的节点度的一个函数,所以很容易计算。该启发式对枢纽节点进行惩罚,并优先考虑连接较少的节点。这一启发式方法得到了经验评估结果的支持。
与Cluster-GCN相比,GraphSAINT可以扩展到更大的图形,并实现了最先进的性能。GraphSAINT的预处理步骤在计算上更有效率,预处理加上模型训练的总时间比Cluster-GCN小得多。
其他方法
节点和图形采样并不是可扩展的GNN的唯一两种方法。FastGCN是另一种采样方法,它侧重于在图卷积层内进行逐层采样。与GCN相比,FastGCN可以扩展到更大的图形,但存在高变异性的问题。VR-GCN通过控制方差对FastGCN进行了改进;作者表明,使用他们的方差减少技术,只需对一条边/节点进行采样,同时仍能获得高分类精度。
另一类方法通过避免昂贵的邻接矩阵和节点特征矩阵的计算来简化GNNs。简化GNN(SCCN)简单地计算邻接矩阵的功率,然后与节点特征矩阵相乘一次;实际上,这个操作是根据图的结构对节点特征进行平滑处理。平滑化的节点特征被用作MLP的输入。SGCN与GCN的性能相匹配,并且在计算上更有效率。一个矩阵乘法步骤可以在一个分布式系统中作为预处理步骤计算一次。训练MLP可以在任何GPU上有效进行。
PPNP和APPNP做了类似的事情,只是在这种情况下,首先对节点特征进行MLP训练(在这个阶段没有像SGCN那样进行平滑处理)。然后,MLP预测被传播/扩散到整个图中,使用个性化网页排名(PPR)分数来确定节点传递的信息量。由于对于大型图来说,精确计算PPR的成本很高,所以APPNP采用了一个近似的PPR,通过一个合适的递归关系很容易计算。PPNP/APPNP模型可以进行端到端的训练,也可以只为训练或推理时间保留传播。
结论
在这篇文章中,我们介绍了基于GCN的GNN,并解释了为什么这种模型不能扩展到大图。然后我们介绍了几种扩展这种GNN的方法。这些方法包括节点采样、图采样和层采样。最后,我们考虑了通过将图结构传播与神经网络训练解耦来简化GNN的方法,从而在保持模型性能的同时提高计算效率。
我们的技术清单当然不是详尽无遗的,但应该为任何对这一工作感兴趣的人提供一个良好的起点。

若有收获,就点个赞吧
0 人点赞
