https://mp.weixin.qq.com/s?__biz=MzI2MDE5MTQxNg==&mid=2649695390&idx=1&sn=ad628f54c97968d6fff55907c47cb77e&chksm=f276e149c501685fe8c328851132248bc3f44b994de285d073db32305b0a14cd7373f5a4780d&mpshare=1&scene=1&srcid=#rd
只截取了一部分内容。这里是基于DGL 0.3版本的
如何使用 DGL
DGL 消息传递 API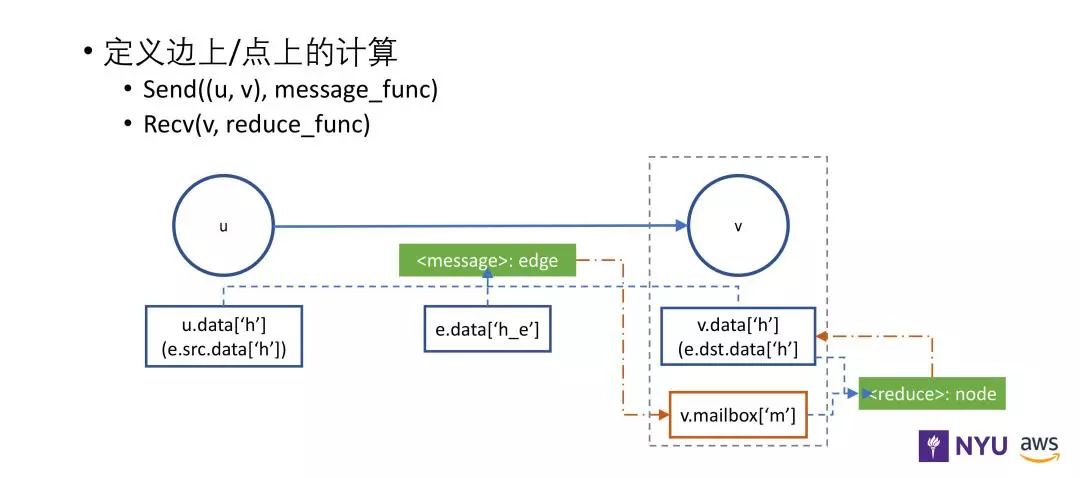
DGL 的 API 主要有两部分,一是 message function(消息函数),二是 reduce function(累和函数)。
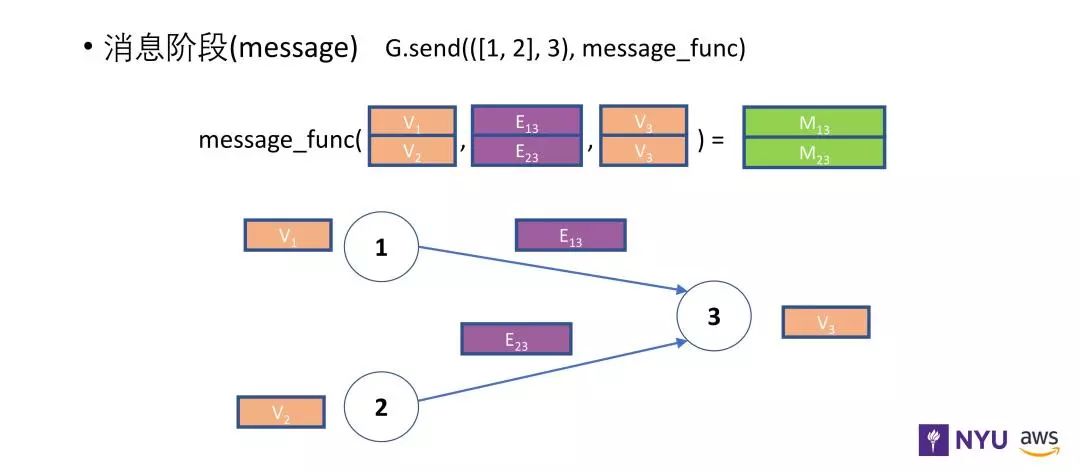
消息函数通过边获得变量,用 e.src.data 获得这条边出发节点的特征信息,通过 e.dst.data 获得目标节点的特征信息。边也拥有自己的特征信息,如上图中的 e.data。消息函数可以获得出发节点和目标节点的特征信息,描述了需要发给目标节点做下一步计算的信息。
上图描述了消息传递模型,消息函数把节点 1 和节点 2 的信息都发送给节点 3 ,可以发送的信息包括v1 、v2 和 v3 以及每条边上的信息。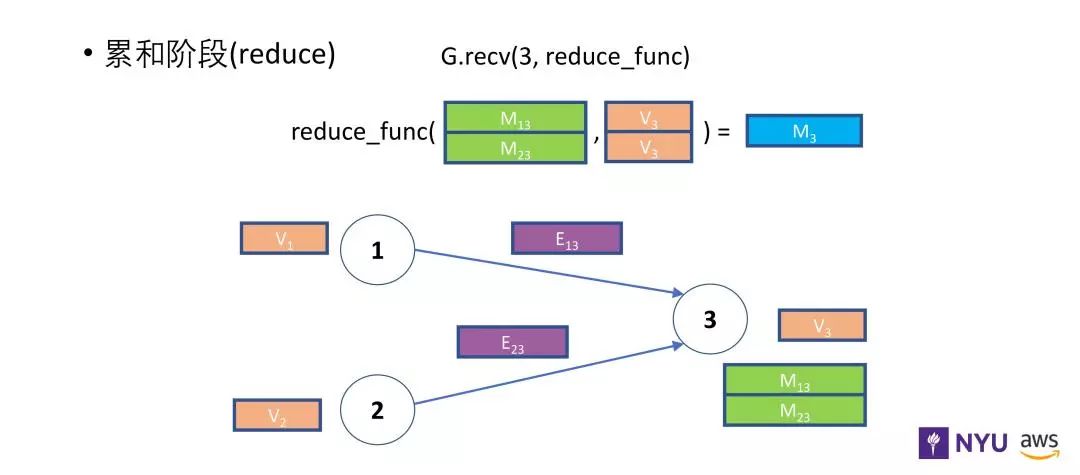
目标节点在获得其他节点以及边的特征信息之后,通过累和函数计算出一个新的表示。通过上图可以看到,累和函数获得了消息函数传递过来的信息 M13、M23 同时还有自身的节点信息。上述的整个过程就是 DGL 现有的核心。
比如一个最简单的图神经网络案例。每个节点获得所有邻居节点的特征信息求和,并通过一个非线性函数得到该节点新的表示。
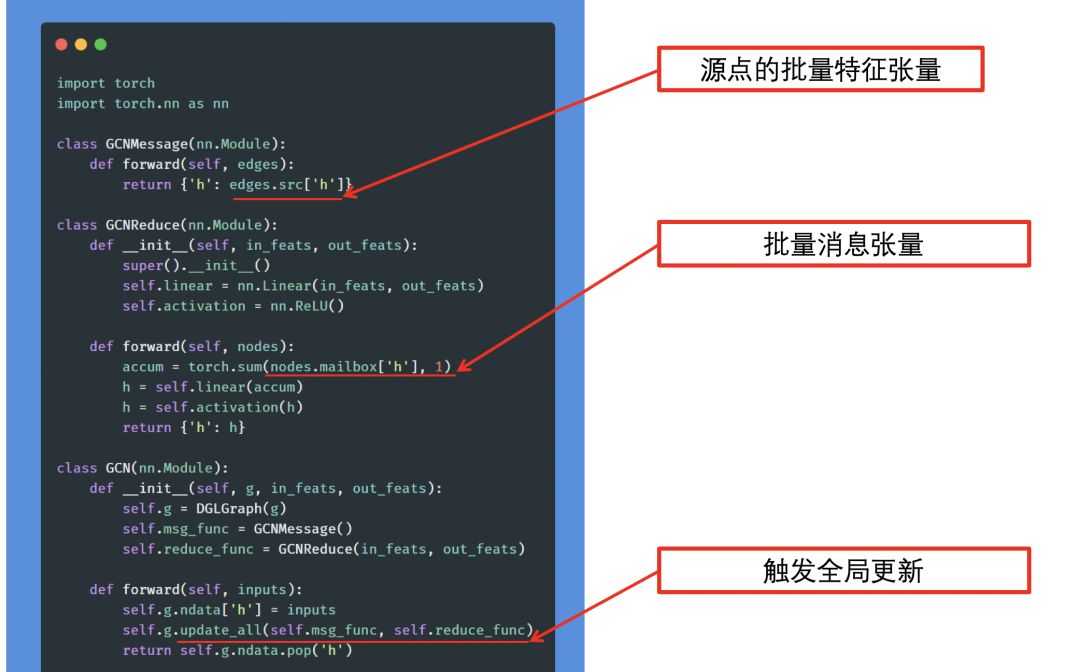
具体的实现过程
消息融合
graph data 有一个特点,就是它的边会远多于节点的数量,比如说节点有 100个,但是边可能有 2000,甚至更多。按照上面的方法处理,每一个节点的信息都要先拷贝到边上,再发给目标节点,在这个过程中,很多拷贝是重复的,因为一个节点可以有多条边。也即消息张量的大小会正比于图中边的数量。所以当图增大的时候,消息张量消耗的内存空间也会显著上升,可能是 O(n2)。
比如模型 GraphSage 中 Reddit 的数据: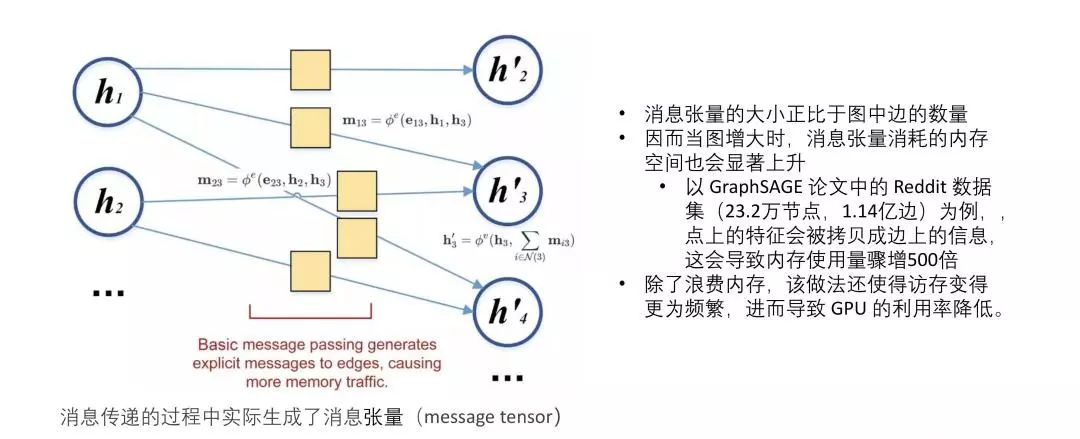
内存使用量骤增 500 倍
DGL 的解决方法是消息融合(Fuse Message Passing)。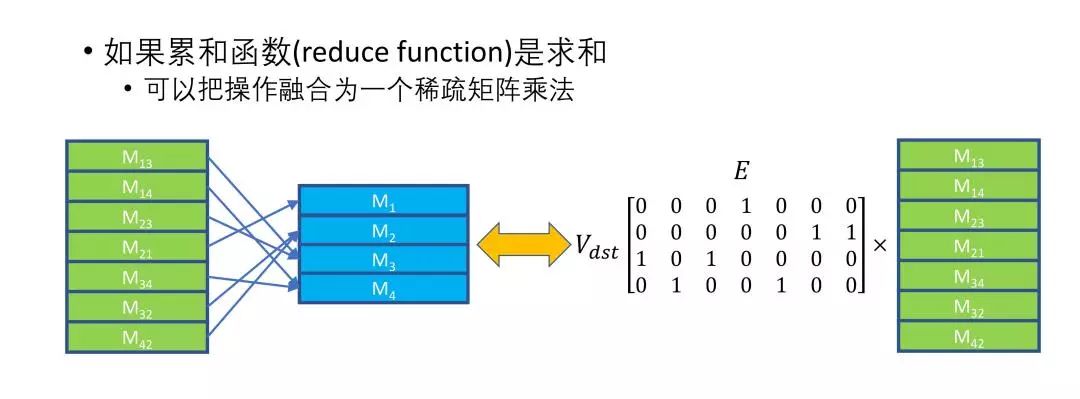
对所有邻居节点的特征信息求和等于邻接矩阵乘上特征张量。所以我们提供了一个矩阵乘法的优化,这样更加高效。
消息融合的不足之处:支持的函数有限。下一个版本的改进方案:

若有收获,就点个赞吧
0 人点赞
