索引:
标准的深度学习模型具有一堆卷积/池/全连接层,其次是最终的全连接层。该最终全连接将输出与类数量相同的载体。因此,如果您有3个类,则最终全连接将输出维度3的向量。
通常,该矢量可能包含任意的实数,例如[-1,3,2]。由此,您需要计算loss。最常用的方法是使用softmax_with_cross_entropy层,这基本上是一个softmax层,其次是跨熵损失标准。
Softmax层对给定载体的每个元素应用以下操作: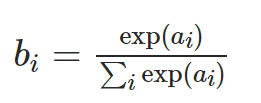
其中ai是输入向量之一,bi是输出向量之一。因此,对于示例[-1,3,2],bi的值是: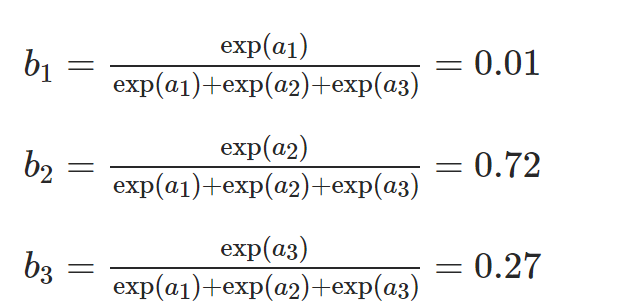
b1,b2,b3> 0和b1 + b2 + b3 = 1。这是类的概率分布。
现在,交叉熵损失准则看的是真实类的负概率。也就是说,如果真实类别是3,那么损失将是-log0.27。当你把损失降到最低时,你就把真实类的概率推向了1。
有了这个背景,很容易看出我们如何引入温度参数。让我们再次以粗体看声明 - 请注意,即使我在指数函数中有一个因素也是如此。也就是说,而不是做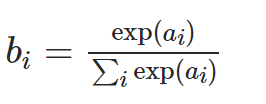
我可以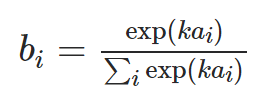
这是因为指数化的结果仍然是正数,而分母保证了它们加起来仍然是1。 所以,这又是一个有效的概率分布。
如果我们把k=2,我们得到b=[0.003,0.880,0.119] 。
如果我们把k=0.5,我们得到b=[0.08,0.57,0.35] 。
这两个都是有效的分布(除去舍入误差)。你会注意到,当你增加k时,分布变得更加峰回路转—原来大的数值变得更大,原来小的数值变得更小。另一方面,当你减少k时,分布变得更平坦—原来大的值变得更小,原来小的值变得更大。
现在,我们可以不在指数中乘以k,而是除以T,其中增加T使分布更平坦,反之亦然。 T是这里的 “温度参数”,它的名字来自统计力学
(举例:T是正无穷,那么不同的ai之间区别不大,都与趋于零,结果变成均匀分布。这称为“软标签”。反之,硬标签)
如果我们在训练时将t设置比较大,那么预测的概率分布会比较平滑,那么loss会很大,loss大的话,计算出的梯度也越大,参数更新步长较大,能够避免陷入局部最优解
温度如何影响学习?
据我所知,温度和准确性之间没有直接关系。通常情况下,你可以从一个大的温度值开始,在训练过程中逐渐降低,这个过程叫做退火(再次借用物理学的名字)。开始时温度大,概率分布中就没有接近零的值,所以梯度更容易传播。
你可以把它看成是学习率—学习率和准确性之间没有直接的关系,只是设置正确的学习率并适当地衰减有助于训练,而完全错误的学习率会抑制训练。

若有收获,就点个赞吧
0 人点赞
