环境构建
CPU版本。 但是本人使用的时会报错,找不到torch_sparse先更改colab的torch版本
!pip install torch==1.7.0+cpu torchvision==0.8.1+cpu torchaudio===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
!pip install --no-index torch-scatter -f https://pytorch-geometric.com/whl/torch-1.7.0+cpu.html!pip install --no-index torch-sparse -f https://pytorch-geometric.com/whl/torch-1.7.0+cpu.html!pip install --no-index torch-cluster -f https://pytorch-geometric.com/whl/torch-1.7.0+cpu.html!pip install --no-index torch-spline-conv -f https://pytorch-geometric.com/whl/torch-1.7.0+cpu.html!pip install torch-geometric
因此,改用了GPU版本
下面的代码会根据torch和cuda版本下载对应的PYG版本。
代码来源https://gist.github.com/ameya98/b193856171d11d37ada46458f60e73e7
# Add this in a Google Colab cell to install the correct version of Pytorch Geometric.import torchdef format_pytorch_version(version):return version.split('+')[0]TORCH_version = torch.__version__TORCH = format_pytorch_version(TORCH_version)def format_cuda_version(version):return 'cu' + version.replace('.', '')CUDA_version = torch.version.cudaCUDA = format_cuda_version(CUDA_version)!pip install torch-scatter -f https://data.pyg.org/whl/torch-{TORCH}+{CUDA}.html!pip install torch-sparse -f https://data.pyg.org/whl/torch-{TORCH}+{CUDA}.html!pip install torch-cluster -f https://data.pyg.org/whl/torch-{TORCH}+{CUDA}.html!pip install torch-spline-conv -f https://data.pyg.org/whl/torch-{TORCH}+{CUDA}.html!pip install torch-geometric
测试
from torch_geometric.data import Data
PyG简单入门
# 边的连接信息# 注意,无向图的边要定义两次edge_index = torch.tensor([# 这里表示节点0和1有连接,因为是无向图 那么1和0也有连接# 上下对应着看[0, 1, 1, 2],[1, 0, 2, 1],],# 指定数据类型dtype=torch.long)# 节点的属性信息x = torch.tensor([# 三个节点# 每个节点的属性向量维度为1[-1],[0],[1],])# 实例化为一个图结构的数据data = Data(x=x, edge_index=edge_index)# 查看图数据print(data) #Data(x=[3, 1], edge_index=[2, 4])# 图数据中包含什么信息print(data.keys) #['edge_index', 'x']# 查看节点的属性信息print(data['x'])>>>tensor([[-1],[ 0],[ 1]])# 节点数print(data.num_nodes) #3# 边数print(data.num_edges) #4# 节点属性向量的维度print(data.num_node_features)# 1# 图中是否有孤立节点print(data.has_isolated_nodes()) #False# 图中是否有环print(data.has_self_loops()) #False# 是否是有向图print(data.is_directed()) #False
下载ENZYMES数据集
接下来拿ENZYMES数据集(包含600个图,每个图分为6个类别,图级别的分类)举例如何使用PyG的公共数据集
BRENDA酶数据库,起源于德国不伦瑞克在1987年建立的国家生物技术研究中心(GBF),目前由德国科隆大学生物化学研究所负责运营。BRENDA可以提供酶的分类、命名法、生化反应、专一性、结构、细胞定位、提取方法、文献、应用与改造及相关疾病的数据。人们不仅可以通过互联网(http://www.brenda-enzymes.org)免费获得,还也可以将其作为商业用户的内部数据库(需要请求其分销商Biobase)。
from torch_geometric.datasets import TUDataset# 导入数据集dataset = TUDataset(# 指定数据集的存储位置# 如果指定位置没有相应的数据集# PyG会自动下载root='../data/ENZYMES',# 要使用的数据集name='ENZYMES',)# 数据集的长度print(len(dataset))# 数据集的类别数print(dataset.num_classes)# 数据集中节点属性向量的维度print(dataset.num_node_features)# 600个图,我们可以根据索引选择要使用哪个图data = dataset[0]print(data)# 随机打乱数据集dataset = dataset.shuffle()>>>60063Data(edge_index=[2, 168], x=[37, 3], y=[1])Done!
可以看到数据集下载到了colab自己的文件中了
Data(edge_index=[2, 168], x=[37, 3], y=[1])的说明:
第一张图有168条有向边,37个节点,每个节点3个label,整张图有一个类别
加载ENZYMES数据集
from torch_geometric.loader import DataLoader# 数据集dataset = TUDataset(root='../data/ENZYMES',name='ENZYMES',use_node_attr=True,)# 建立数据集加载器# 每次加载32个数据到内存中loader = DataLoader(# 要加载的数据集dataset=dataset,# ENZYMES包含600个图# 每次加载32个batch_size=32,# 每次加入进来之后是否随机打乱数据(可以增加模型的泛化性)shuffle=True)for batch in loader:print(batch)print(batch.num_graphs)

y=[32]——32个图。
node_labels: (0,1,2); node_features: 21
dataset[0].num_features
输出是21。说明总的特征数是21
之前 data = dataset[0],输出是Data(edge_index=[2, 168], x=[37, 3], y=[1])
x只有3,而现在这里的x有21。个人推测是输出data的时候,数据集里没有使用use_node_attr=True,所以输出的3是结点的label数。
而现在使用了use_node_attr=True,输出的是节点的特征数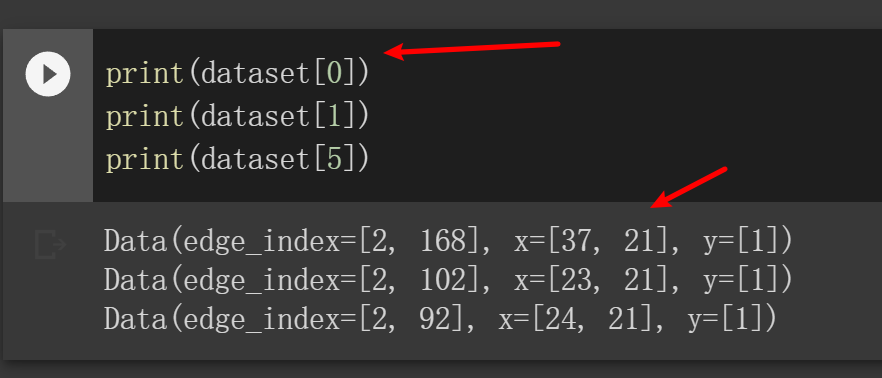
ptr可能是当前batch目前累计看到的图的节点数量。具体实验文章https://blog.csdn.net/qq_40206371/article/details/120615976

若有收获,就点个赞吧
0 人点赞
