来源:https://mydoc.myencyclopedia.top/pub-html/01_plot_cora.html
B站链接:https://www.bilibili.com/video/BV1f3411i7MQ?p=1
内置 Cora 数据集
下一步,我们会通过 geometric 类库加载 cora 数据集。这一步通常来说需要从网上下载,但是预制的 docker image 已经为大家下载好了 planetoid 图数据集。Planetoid 包含了 Cora,Pubmed 和 Citeseer。
因此,加载数据集这一步执行非常快
import numpy as npimport torchimport torch.nn as nnimport torch.nn.functional as Ffrom torch_geometric.data import Datafrom torch_geometric.nn import GATConvfrom torch_geometric.datasets import Planetoidimport torch_geometric.transforms as Tname_data = 'Cora'dataset = Planetoid(root='./data/', name=name_data)
数据集说明
样本特征,标签,邻接矩阵 该数据集共2708个样本点,每个样本点都是一篇科学论文,所有样本点被分为8个类别,类别分别是1)基于案例;2)遗传算法;3)神经网络;4)概率方法;5)强化学习;6)规则学习;7)理论
每篇论文都由一个1433维的词向量表示,所以,每个样本点具有1433个特征。词向量的每个元素都对应一个词,且该元素只有0或1两个取值。取0表示该元素对应的词不在论文中,取1表示在论文中。所有的词来源于一个具有1433个词的字典。
每篇论文都至少引用了一篇其他论文,或者被其他论文引用,也就是样本点之间存在联系,没有任何一个样本点与其他样本点完全没联系。如果将样本点看做图中的点,则这是一个连通的图,不存在孤立点。[
](https://blog.csdn.net/yeziand01/article/details/93374216)
dataset.data#Data(x=[2708, 1433], edge_index=[2, 10556], y=[2708], train_mask=[2708], val_mask=[2708], test_mask=[2708])np.unique(dataset[0].y)#array([0, 1, 2, 3, 4, 5, 6]) 一共有7个类别
y表示论文的标签。(因为有2708个结点,所以相应的有2708个y)
可视化
然后我们将 cora 转换成 networkx 格式。networkx 是 python 中一个比较流行的图类库。我们在后面 visualization 中也会利用networkx 的功能。
Cora 有 7 种节点类型,我们将每种节点类型赋予不同颜色,有助于更好 visualization。
from torch_geometric.utils import to_networkxcora = to_networkx(dataset.data)print(cora.is_directed()) #Truenode_classes = dataset.data.y.data.numpy()print(node_classes) #[3 4 4 ... 3 3 3]node_color = ["red","blue","green","yellow","peru","violet","cyan"]node_label = np.array(list(cora.nodes))
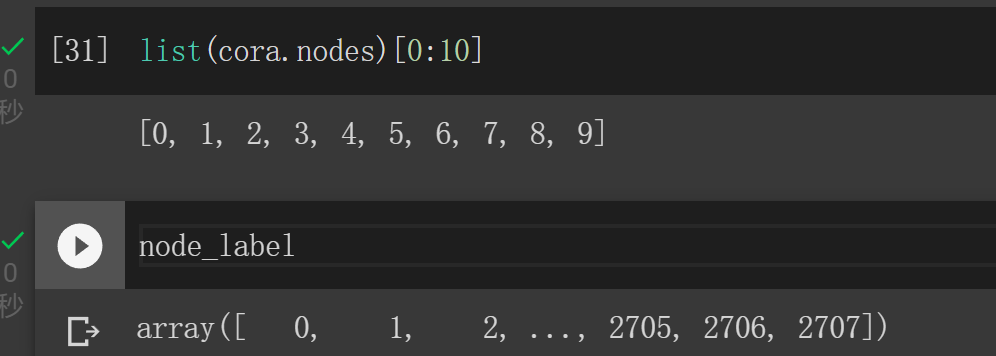
接着,调用 networkx 的 spring_layout 计算每个节点的弹簧布局下的位置,这一步执行会比较耗时。
import matplotlib.pyplot as pltimport networkx as nxpos = nx.layout.spring_layout(cora)
我们首先来看一下 matplotlib 的渲染效果。
plt.figure(figsize=(16,12))for i in np.arange(len(np.unique(node_classes))):node_list = node_label[node_classes == i] #将class为i的node组成 node_listnx.draw_networkx_nodes(cora, pos, nodelist=list(node_list),node_size=50,node_color=node_color[i],alpha=0.8)nx.draw_networkx_edges(cora, pos,width=1,edge_color="black")plt.show()
len(np.unique(node_classes)) =7
这里我不懂为什么**node_list = node_label[node_classes == i] **可以筛选出想要的条件,所以就有了如下的操作
以i=0时,node_list为例子
当i=0时,node_list的输出
可以看到,输出的是class为0的节点的下标
node_label是一个0-2707的数组(相当于下标)
node_classes是结点的类别
node_classes==0 是有True,False构成的数组
node_label[node_classes == 0]就返回了所以True的下标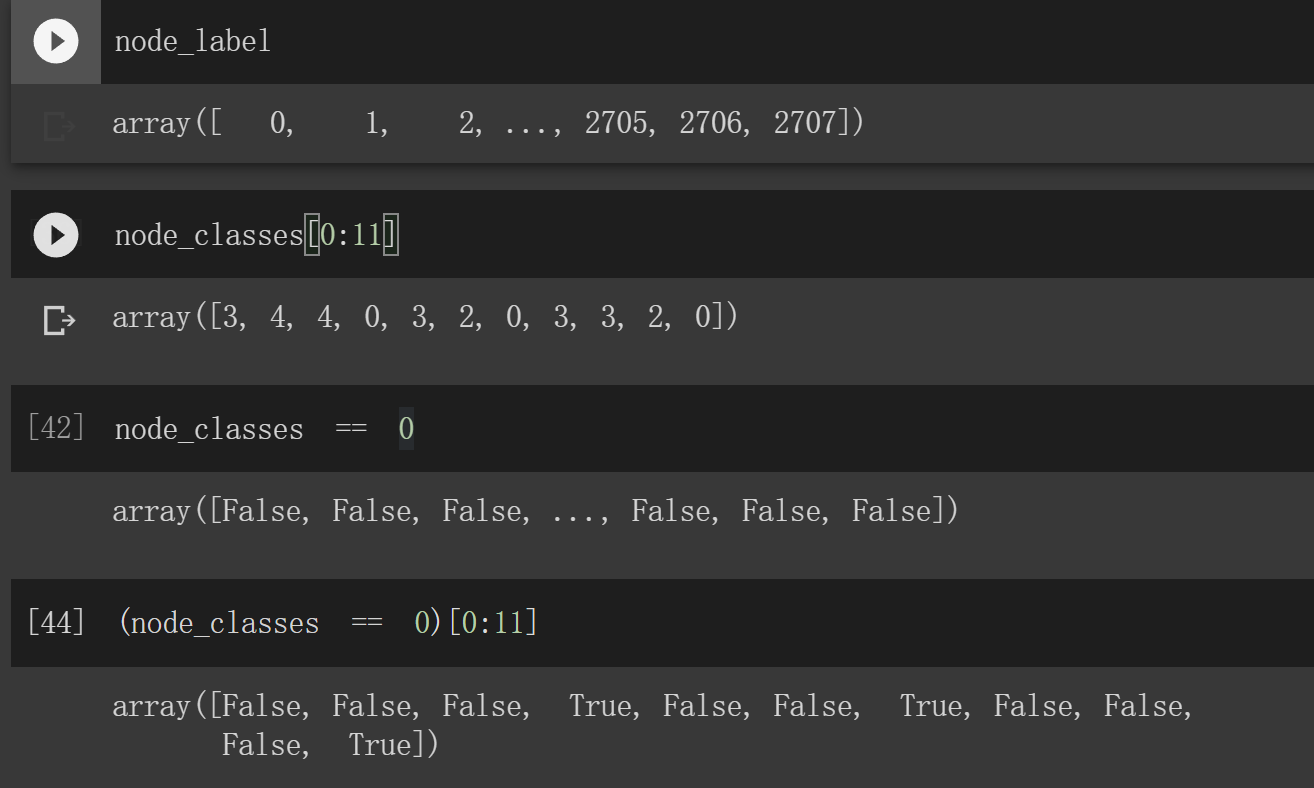

绘图的结果
因为 matplotlib 只能画出一张静态图片, 无法做 interaction,也无法动态缩放。因此渲染效果不是特别好,尤其是对于 cora 这种数据量比较大的 graph 尤为显著。
我们看到图片种尽管有七种颜色的节点,但是当中存在的这块密集的点,我们很难看出节点和节点之间的关系。
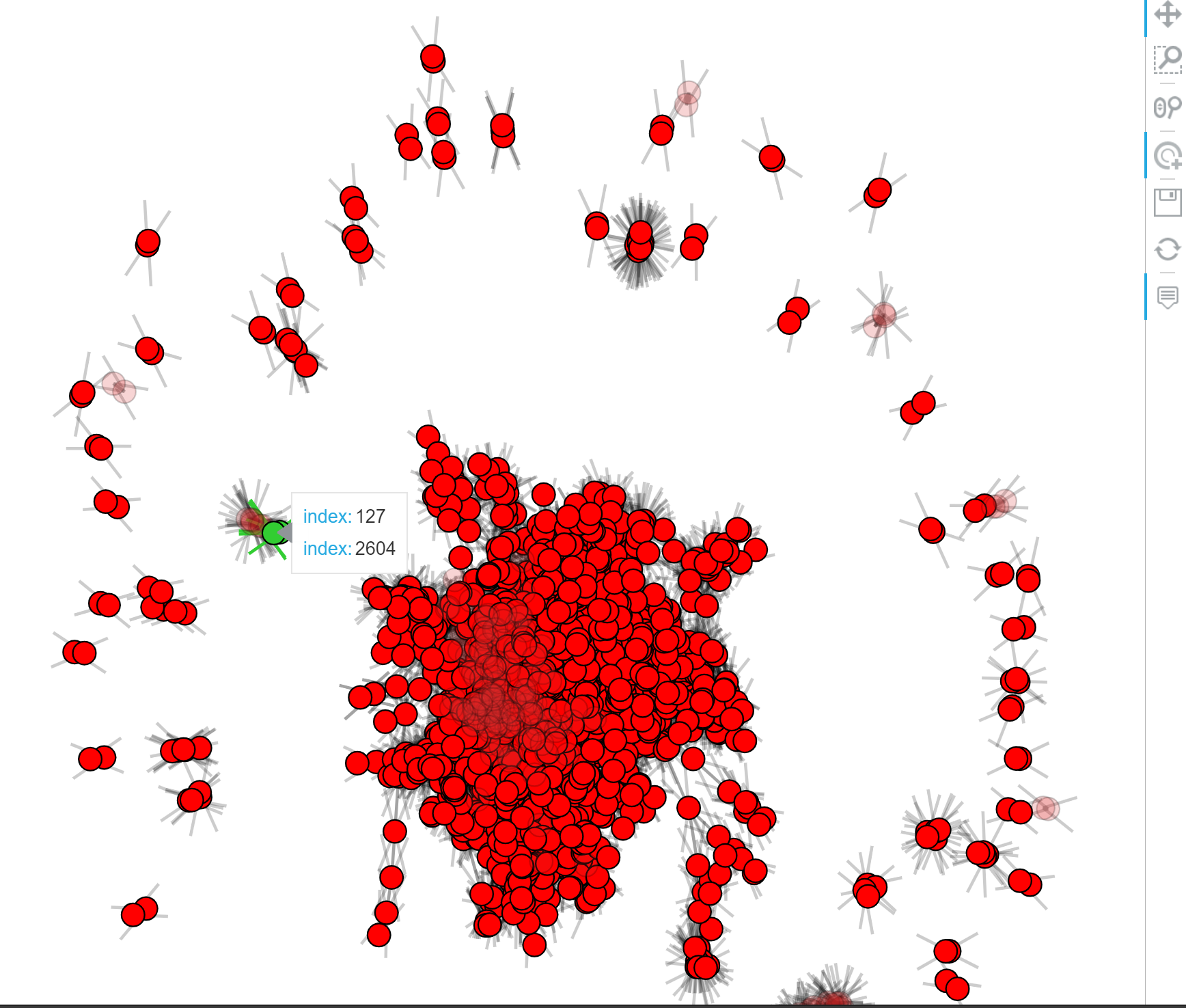
我们换一个类库 hvplot,它的渲染和交换效果如下。
代码和 matplotlib 大致一致。注意渲染的时候 hvplot 需要将多个图片数据以乘法形式返回,借助 reduce 函数我们将 7 种节点的图相乘,再乘以描绘边的图,呈现出叠加的完整图片。
import hvplot.networkx as hvnxoptions = {'width': 800,'height': 1000}plt_nodes = []for i in np.arange(len(np.unique(node_classes))):nodelist = node_label[node_classes == i]plt = hvnx.draw_networkx_nodes(cora, pos, nodelist=list(nodelist), node_color=node_color[i], **options)plt_nodes.append(plt)plt_edges = hvnx.draw_networkx_edges(cora, pos, arrowstyle='->', edge_width=2, colorbar=True, **options)import functoolsimport operatorplt_edges * functools.reduce(operator.mul, plt_nodes)

若有收获,就点个赞吧
0 人点赞
