MNIST-Superpixel 数据集
Understanding Graph Neural Network with hands-on example| Part-2 Medium的链接https://medium.com/@rtsrumi07/understanding-graph-neural-network-with-hands-on-example-part-2-139a691ebeac
colab链接:https://colab.research.google.com/drive/1EMgPuFaD-xpboG_ZwZcytnlOlr39rakd
主要是了解GCN 模型在实际数据集上的使用,所以代码不是完整的
安装PyG
限定torch版本
# Enforce pytorch version 1.6.0import torchif torch.__version__ != '1.6.0':!pip uninstall torch -y!pip uninstall torchvision -y!pip install torch==1.6.0!pip install torchvision==0.7.0# Check pytorch version and make sure you use a GPU Kernel!python -c "import torch; print(torch.__version__)"!python -c "import torch; print(torch.version.cuda)"!python --version!nvidia-smi
相应的PyG GPU版本
# If something breaks in the notebook it is probably related to a mismatch between the Python version, CUDA or torchimport torchpytorch_version = f"torch-{torch.__version__}+cu{torch.version.cuda.replace('.', '')}.html"!pip install --no-index torch-scatter -f https://pytorch-geometric.com/whl/$pytorch_version!pip install --no-index torch-sparse -f https://pytorch-geometric.com/whl/$pytorch_version!pip install --no-index torch-cluster -f https://pytorch-geometric.com/whl/$pytorch_version!pip install --no-index torch-spline-conv -f https://pytorch-geometric.com/whl/$pytorch_version!pip install torch-geometric
加载数据集
from torch_geometric.datasets import MNISTSuperpixelsfrom torch_geometric.data import DataLoader# Load the MNISTSuperpixel datasetdata = MNISTSuperpixels(root=".")data
模型
我们应用三个卷积层,这意味着我们学习了3个邻居的信息。之后,我们应用一个pooling层来结合各个节点的信息,因为我们要进行graph级预测。
请记住,不同的学习问题(节点、边缘或图的预测)需要不同的GNN架构。
例如,对于节点级的预测,你会经常遇到掩码mask。另一方面,对于图层面的预测,你需要结合节点嵌入。
在层之间,我使用了tanh激活函数来创建对比度。之后,我通过对节点嵌入使用池化操作将节点嵌入合并为单个嵌入向量。在这种情况下,对节点状态执行了平均值和最大值运算(global_mean_pool , global_max_pool )。这样做的原因是我想在图形级别进行预测,因此需要复合嵌入。在节点级别处理预测时。
PyTorch Geometric 中有多种替代池化层可用,但我想在这里保持简单并利用这种均值和最大值的组合。
最后,线性输出层确保我收到一个连续且无界的输出值。扁平向量用作此函数的输入。
import torchfrom torch.nn import Linearimport torch.nn.functional as Ffrom torch_geometric.nn import GCNConv, TopKPooling, global_mean_poolfrom torch_geometric.nn import global_mean_pool as gap, global_max_pool as gmpembedding_size = 64class GCN(torch.nn.Module):def __init__(self):# Init parentsuper(GCN, self).__init__()torch.manual_seed(42)# GCN layersself.initial_conv = GCNConv(data.num_features, embedding_size)self.conv1 = GCNConv(embedding_size, embedding_size)self.conv2 = GCNConv(embedding_size, embedding_size)self.conv3 = GCNConv(embedding_size, embedding_size)# Output layerself.out = Linear(embedding_size*2, data.num_classes)def forward(self, x, edge_index, batch_index):# First Conv layerhidden = self.initial_conv(x, edge_index)hidden = F.tanh(hidden)# Other Conv layershidden = self.conv1(hidden, edge_index)hidden = F.tanh(hidden)hidden = self.conv2(hidden, edge_index)hidden = F.tanh(hidden)hidden = self.conv3(hidden, edge_index)hidden = F.tanh(hidden)# Global Pooling (stack different aggregations)hidden = torch.cat([gmp(hidden, batch_index),gap(hidden, batch_index)], dim=1)# Apply a final (linear) classifier.out = self.out(hidden)return out, hiddenmodel = GCN()print(model)print("Number of parameters: ", sum(p.numel() for p in model.parameters()))
GCN((initial_conv): GCNConv(1, 64)(conv1): GCNConv(64, 64)(conv2): GCNConv(64, 64)(conv3): GCNConv(64, 64)(out): Linear(in_features=128, out_features=10, bias=True))Number of parameters: 13898
打印层的模型摘要后,可以看到每个层中有 10 个特征被馈送到消息传递层,产生大小为 64 的隐藏状态,最终使用均值和最大值操作组合。嵌入大小 (64) 的选择是一个超参数,取决于数据集中图形的大小等因素。
最后,这个模型有 13898 个参数,这似乎是合理的,因为我有 9000 个样本。出于演示目的,使用了总数据集的 15%。
训练
批次大小为 64(这意味着我们的批次中有 64 个图)并使用 shuffle 选项在批次中分布图。主数据集的 15% 的前 80% 将用于训练数据,主数据集的 15% 的其余 20% 将用于测试数据。在我的分析中,交叉熵用作损失度量。选择 Adam(自适应运动估计)作为优化器,初始学习率为 0.0007。
然后是简单的迭代 Data Loader 加载的每批数据;幸运的是,这个函数为我们处理了一切,就像它在 train 函数中所做的一样。这个训练函数被命名为 # epochs 次,在这个例子中是 500。
from torch_geometric.data import DataLoaderimport warningswarnings.filterwarnings("ignore")# Cross EntrophyLossloss_fn = torch.nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.0007)# Use GPU for trainingdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")model = model.to(device)# Wrap data in a data loaderdata_size = len(data)NUM_GRAPHS_PER_BATCH = 64loader = DataLoader(data[:int(data_size * 0.8)],batch_size=NUM_GRAPHS_PER_BATCH, shuffle=True)test_loader = DataLoader(data[int(data_size * 0.8):],batch_size=NUM_GRAPHS_PER_BATCH, shuffle=True)def train(data):# Enumerate over the datafor batch in loader:# Use GPUbatch.to(device)# Reset gradientsoptimizer.zero_grad()# Passing the node features and the connection infopred, embedding = model(batch.x.float(), batch.edge_index, batch.batch)# Calculating the loss and gradientsloss = torch.sqrt(loss_fn(pred, batch.y))loss.backward()# Update using the gradientsoptimizer.step()return loss, embeddingprint("Starting training...")losses = []for epoch in range(500):loss, h = train(data)losses.append(loss)if epoch % 10 == 0:print(f"Epoch {epoch} | Train Loss {loss}")
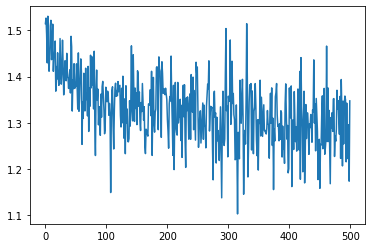
train loss
# Visualize learning (training loss)import seaborn as snslosses_float = [float(loss.cpu().detach().numpy()) for loss in losses]loss_indices = [i for i,l in enumerate(losses_float)]plt = sns.lineplot(loss_indices, losses_float)plt
预测
import pandas as pdtest_batch = next(iter(test_loader))with torch.no_grad():test_batch.to(device)pred, embed = model(test_batch.x.float(), test_batch.edge_index, test_batch.batch)pred=torch.argmax(pred,dim=1)print(test_batch.y[0])#Actual REsultprint(pred[0])#Predicted Result>>>tensor(1, device='cuda:0')tensor(1, device='cuda:0')
import torchimport networkx as nximport matplotlib.pyplot as pltdef visualize(h, color, epoch=None, loss=None):plt.figure(figsize=(7,7))plt.xticks([])plt.yticks([])if torch.is_tensor(h):h = h.detach().cpu().numpy()plt.scatter(h[:, 0], h[:, 1], s=140, c=color, cmap="Set2")if epoch is not None and loss is not None:plt.xlabel(f'Epoch: {epoch}, Loss: {loss.item():.4f}', fontsize=16)else:nx.draw_networkx(G, pos=nx.spring_layout(G, seed=42), with_labels=False,node_color=color, cmap="Set2")plt.show()
dataset=data[1]print(f'Is undirected: {dataset.is_undirected()}')from torch_geometric.utils import to_networkxG = to_networkx(dataset, to_undirected=True)visualize(G, "yellow")visualize(G, "red")

若有收获,就点个赞吧
0 人点赞
