说明
没有自己构造GCNLayer,而已使用dgl的GraphConv
环境准备
安装的是GPU版本的DGL,但实际使用没有使用GPU
import torch
pip install dgl-cu110 -f https://data.dgl.ai/wheels/repo.html
import dglimport numpy as npimport networkx as nximport torch.nn as nnimport torch.nn.functional as Ffrom dgl.nn.pytorch import GraphConvimport itertoolsimport matplotlib.animation as animationimport matplotlib.pyplot as plt%matplotlib inline
构造
# 构造俱乐部人员关系def build_karate_club_graph():# 所有78条边都存储在两个numpy数组中。一个用于源端点# 另一个用于目标端点。src = np.array([1, 2, 2, 3, 3, 3, 4, 5, 6, 6, 6, 7, 7, 7, 7, 8, 8, 9, 10, 10,10, 11, 12, 12, 13, 13, 13, 13, 16, 16, 17, 17, 19, 19, 21, 21,25, 25, 27, 27, 27, 28, 29, 29, 30, 30, 31, 31, 31, 31, 32, 32,32, 32, 32, 32, 32, 32, 32, 32, 32, 33, 33, 33, 33, 33, 33, 33,33, 33, 33, 33, 33, 33, 33, 33, 33, 33])dst = np.array([0, 0, 1, 0, 1, 2, 0, 0, 0, 4, 5, 0, 1, 2, 3, 0, 2, 2, 0, 4,5, 0, 0, 3, 0, 1, 2, 3, 5, 6, 0, 1, 0, 1, 0, 1, 23, 24, 2, 23,24, 2, 23, 26, 1, 8, 0, 24, 25, 28, 2, 8, 14, 15, 18, 20, 22, 23,29, 30, 31, 8, 9, 13, 14, 15, 18, 19, 20, 22, 23, 26, 27, 28, 29, 30,31, 32])# 在DGL中,边是有方向性的;让他们双向。g=dgl.graph((src,dst))bg=dgl.to_bidirected(g)return bg
g=build_karate_club_graph()g>>>Graph(num_nodes=34, num_edges=156,ndata_schemes={}edata_schemes={})
查看网络
# 由于实际图形是无向的,因此我们去掉边的方向,以达到可视化的目的nx_G = g.to_networkx().to_undirected()# 为了图更加美观,我们使用Kamada-Kawaii layoutpos = nx.kamada_kawai_layout(nx_G)nx.draw(nx_G, pos, with_labels=True, node_color=[[.2, .7, .7]])
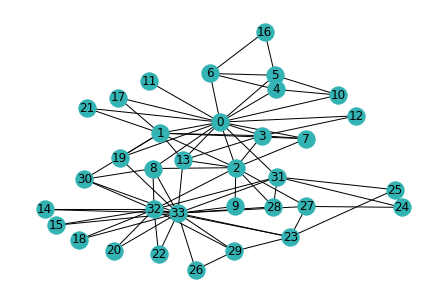
每一个结点特征都是一个独热码one-hot。这里只是展示了如何给图增加特征。实际上,该例子的特征是以单独构建了一个inputs然后传入的
#在DGL中,可以使用特征张量为所有节点一次性添加特征#使用一个沿着第一个维度批量节点特性的特性张量。g.ndata['feat'] = torch.eye(34)
#查看特征print(g.nodes[2].data['feat'])# print out node 10 and 11's input featuresprint(g.nodes[[10, 11]].data['feat'])#也可以这样查看 g.ndata['feat'][torch.tensor([2,10,11])]>>>tensor([[0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
#定义一个GCN模型,包含2个图卷积层#维度 34→5→2 最后只有2个维度,代表的是2个类别 0或33class GCN(nn.Module):def __init__(self, in_feats, hidden_size, num_classes):super(GCN, self).__init__()self.gcn1 = GraphConv(in_feats,hidden_size)self.gcn2 = GraphConv(hidden_size, num_classes)def forward(self, g, inputs):h = self.gcn1(g, inputs)h = torch.relu(h)h = self.gcn2(g, h)return h
net=GCN(34,5,2)net>>>GCN((gcn1): GraphConv(in=34, out=5, normalization=both, activation=None)(gcn2): GraphConv(in=5, out=2, normalization=both, activation=None))
我们使用one-hot向量初始化节点。因为是一个半监督的设定,仅有指导员(节点0)和俱乐部主席(节点33)被分配了label,实现如下:
训练
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)all_logits = []for epoch in range(100):logits = net(g, inputs) # 前向传播 net() 是一个GCN模型 G是一个图数据 inputs 是节点 embedding (one-hot向量)#print(logits)#break#保存logits以便于接下来可视化all_logits.append(logits.detach())logp = F.softmax(logits, 1) #logp = F.log_softmax(logits, 1)#print(logp)# break# 仅为标记过的节点(0和33)计算lossloss = F.nll_loss(logp[labeled_nodes], labels)print(logp[labeled_nodes])breakoptimizer.zero_grad()loss.backward()optimizer.step()print('Epoch %d | Loss: %.4f' % (epoch, loss.item()))
结果
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)all_logits = []for epoch in range(100):logits = net(g, inputs) # 前向传播 net() 是一个GCN模型 G是一个图数据 inputs 是节点 embedding (one-hot向量)#保存logits以便于接下来可视化all_logits.append(logits.detach())logp = F.softmax(logits, 1)# 仅为标记过的节点(0和33)计算lossloss = F.nll_loss(logp[labeled_nodes], labels)optimizer.zero_grad()loss.backward()optimizer.step()print('Epoch %d | Loss: %.4f' % (epoch, loss.item()))
最后一轮的logits(全部)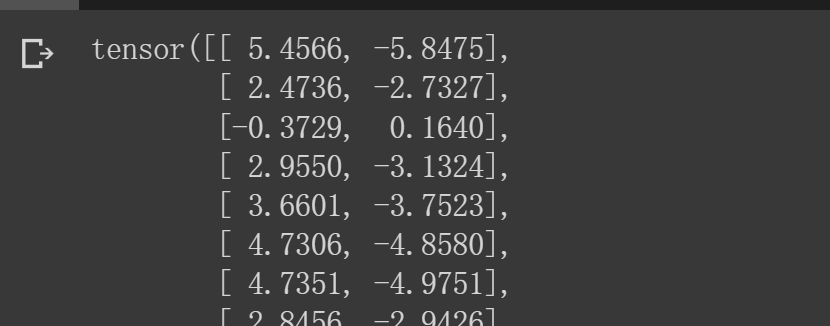
归一化之后(这里只输出了0和33)
print(logp[labeled_nodes])
[0]号的标签概率接近为[1,0]
[33]号标签概率接近为[0,1]
这里不太好理解,所以我把logp = F.log_softmax(logits, 1)改成了logp = F.softmax(logits, 1)
这里不懂,因为我的标签设置的是[0,1]

若有收获,就点个赞吧
0 人点赞
