出处:https://awadrahman.medium.com/hands-on-graph-neural-networks-for-social-network-using-pytorch-30231c130b38
参考:https://www.youtube.com/watch?v=8owQBFAHw7E 视频是用TensorFlow实现的,用的是Cora数据集。和本次的不一样
完整代码https://github.com/Awadelrahman/GNN4SocialNWTutorial/blob/main/SocialGNN.ipynb
框架:torch_geometric (PyTorch Geometric)
核心模型:GCNConv
数据集:musae-github
我们要研究的特定问题是一个典型的节点分类问题。我们有一个大型的GitHub开发者社交网络,名为male-github,是从公共API中收集的。节点代表了至少在10个资源库上挂过星的开发者(平台用户),边是他们之间的相互追随者关系(注意,相互这个词表示无定向关系)。节点的特征是根据位置、已加星的仓库、雇主和电子邮件地址来提取的。我们的任务是预测GitHub用户是网络还是机器学习开发者。这个目标特征是由每个用户的工作职位得出的。论文参考的数据集是 “多尺度归属节点嵌入”。Multi-scale Attributed Node Embedding.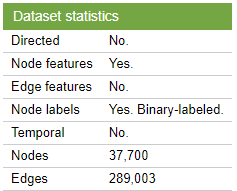
下载数据集后,我们可以看到 3 个重要文件:
musae_git_edges.csv包含边的索引。
musae_git_features.json其中包含节点的特征。
musae_git_target.csv其中包含目标,即节点标签。
导包
从torch_geometric我们需要导入AddTrainValTestMask,这将有助于我们稍后分离训练和测试集
%matplotlib inlineimport jsonimport collectionsimport numpy as npimport pandas as pdimport matplotlibimport matplotlib.pyplot as pltimport torchimport torch.nn as nnimport torch.nn.functional as Ffrom torch_geometric.data import Datafrom torch_geometric.transforms import AddTrainValTestMask as maskingfrom torch_geometric.utils.convert import to_networkxfrom torch_geometric.nn import GCNConvimport networkx as nx
数据集
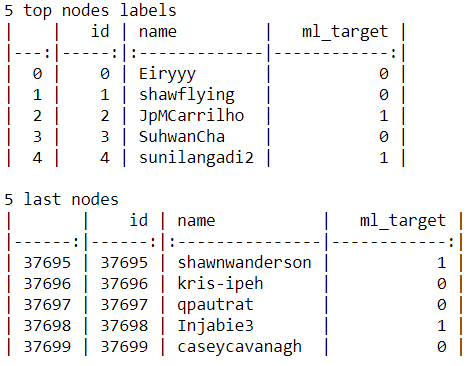
我假设数据集文件是在一个名为data的子文件夹中。我们读取这些文件并绘制标签文件中的前5行和最后5行。尽管我们看到了4列,但这里只有2列与我们有关:节点的ID(即用户)和ml_target,如果用户是机器学习社区的用户,则为1,否则为0。现在,我们确信我们的任务是一个二元分类问题,因为我们只有两个类别。
with open("data/musae_git_features.json") as json_data:data_raw = json.load(json_data)edges=pd.read_csv("data/musae_git_edges.csv")target_df=pd.read_csv("data/musae_git_target.csv")print("5 top nodes labels")print(target_df.head(5).to_markdown())print()print("5 last nodes")print(target_df.tail(5).to_markdown())
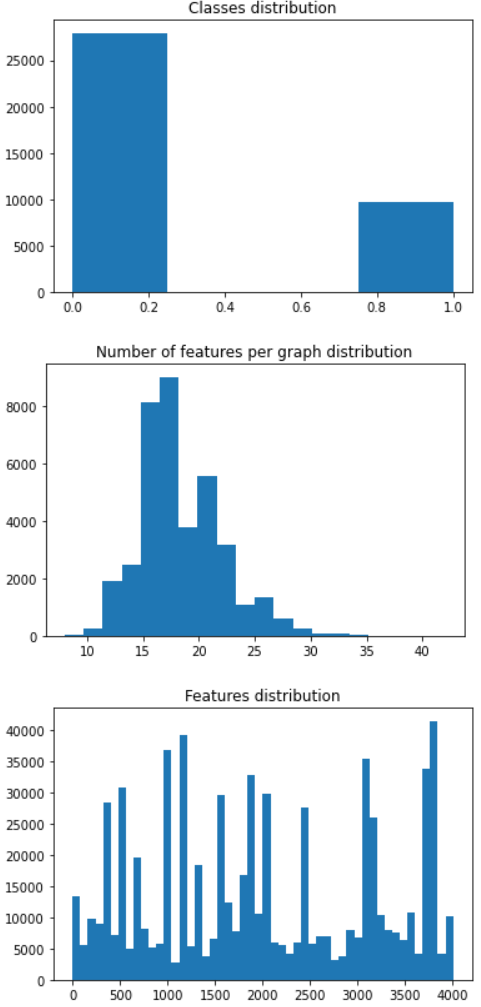
我们需要查看类平衡的另一个重要属性,这是因为严重的类不平衡可能导致分类器简单地猜测多数类,而不对代表性不足的类进行任何评估。通过绘制直方图(频率分布),我们看到了一些不平衡,因为机器学习(标签=1)比其他类别少。这会导致一些问题,但我们可以说,就目前而言,这不是一个严重的问题。
我们还可以根据特征的数量看到节点是如何不同的。第二个直方图告诉我们大多数用户有 15 到 23 个特征,很少有超过 30 个特征少于 5 个特征的用户。第三个直方图显示了用户最常见的特征,我们可以看到分布上的不同峰值
plt.hist(target_df.ml_target,bins=4);plt.title("Classes distribution")plt.show()plt.hist(feat_counts,bins=20)plt.title("Number of features per graph distribution")plt.show()plt.hist(feats,bins=50)plt.title("Features distribution")plt.show()
特征编码
节点特征告诉我们哪个特征附加到每个节点。我们可以通过编写我们的函数来对这些特征进行单热编码encode_data。我们的计划是使用这个函数来编码图形的一个轻量级子集(例如只有 60 个节点)以实现可视化。这是功能
def encode_data(light=False,n=60):if light==True:nodes_included=nelif light==False:nodes_included=len(data_raw)data_encoded={}for i in range(nodes_included):#one_hot_feat=np.array([0]*(max(feats)+1))this_feat=data_raw[str(i)]one_hot_feat[this_feat]=1data_encoded[str(i)]=list(one_hot_feat)if light==True:sparse_feat_matrix=np.zeros((1,max(feats)+1))for j in range(nodes_included):temp=np.array(data_encoded[str(j)]).reshape(1,-1)sparse_feat_matrix=np.concatenate((sparse_feat_matrix,temp),axis=0)sparse_feat_matrix=sparse_feat_matrix[1:,:]return(data_encoded,sparse_feat_matrix)elif light==False:return(data_encoded, None)
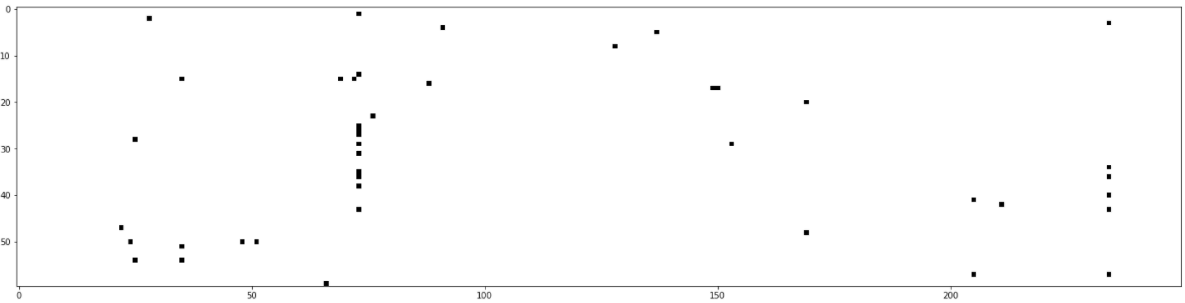
我们可以为前 60 个用户绘制代码的前 250 个特征列(总数为 4005)。下面,我们可以看到我们为节点特征构建的矩阵有多稀疏。
data_encoded_vis,sparse_feat_matrix_vis=encode_data(light=True,n=60)plt.figure(figsize=(25,25));plt.imshow(sparse_feat_matrix_vis[:,:250],cmap='Greys');
图构建和可视化
为了构建我们的图,我们将使用torch_geometric.data.Data,它是一个普通的python对象,用来为一个具有各种(可选)属性的单一图建模。我们将使用这个类来构造我们的图对象,并传递以下属性,注意所有参数都是Torch张量。
- x: 将分配给编码的节点特征,其形状为[number_of_nodes, number_of_features]。
- y: 将分配给节点标签,其形状为 [number_of_nodes]
- edgeindex:为了表示一个无向图,我们需要以这样一种方式扩展原始边索引,即我们可以有两个单独的有向_边连接相同的两个节点,但彼此指向相反。例如,我们需要在节点 100 和节点 200 之间有 2 条边,一条边点从 100 到 200,另一条点从 200 到 100。如果给定边 indecies,这是一种表示无向图的方法。张量形状将为[2,2*number_of_original_edges]。
这里值得一提的是,这个Data类在某种意义上是非常抽象的,您可以添加任何您认为它描述您的图形的属性。例如,我们可以添加一个元数据属性g[“meta_data”]=”bla bla bla”,它可以灵活地封装您想要的任何信息。现在,我们将构建construct_graph执行以下操作的函数:
def construct_graph(data_encoded,light=False):node_features_list=list(data_encoded.values())node_features=torch.tensor(node_features_list)node_labels=torch.tensor(target_df['ml_target'].values)edges_list=edges.values.tolist()edge_index01=torch.tensor(edges_list, dtype = torch.long).Tedge_index02=torch.zeros(edge_index01.shape, dtype = torch.long)#.Tedge_index02[0,:]=edge_index01[1,:]edge_index02[1,:]=edge_index01[0,:]edge_index0=torch.cat((edge_index01,edge_index02),axis=1)g = Data(x=node_features, y=node_labels, edge_index=edge_index0)g_light = Data(x=node_features[:,0:2],y=node_labels ,edge_index=edge_index0[:,:55])if light:return(g_light)else:return(g)
为了绘制图形,我们构建了我们的draw_graph函数。我们需要将我们的同构图转换为 NetworkX 图,然后使用NetworkX.draw.
def draw_graph(data0):#node_labels=data0.yif data0.num_nodes>100:print("This is a big graph, can not plot...")returnelse:data_nx = to_networkx(data0)node_colors=data0.y[list(data_nx.nodes)]pos= nx.spring_layout(data_nx,scale =1)plt.figure(figsize=(12,8))nx.draw(data_nx, pos, cmap=plt.get_cmap('Set1'),node_color =node_colors,node_size=600,connectionstyle="angle3",width =1, with_labels = False, edge_color = 'k', arrowstyle = "-")
现在,我们可以通过调用绘制子图construct_graph用light=True。然后我们可以将它传递给draw_graph, 以显示下图。您可以看到节点如何通过边连接并用颜色标记。
g_sample=construct_graph(data_encoded=data_encoded_vis,light=True)draw_graph(g_sample)

构建和训练我们的 GNN 模型
我们通过调用编码整个数据开始encode_data使用light=False,并通过调用构造全图construct_graph用light=False。我们不会尝试将这个大图可视化,因为我假设您正在使用资源有限的本地计算机
data_encoded,_=encode_data(light=False)g=construct_graph(data_encoded=data_encoded,light=False)
机器学习管道中数据准备后通常的直接步骤是执行数据分离和数据集的子集拆分以训练模型并进一步验证它如何针对新数据执行并保存测试段以报告整体性能。
在我们的例子中,拆分不是直接的,因为我们有一个单独的巨型图,应该一次全部取出(还有一些其他方法可以处理图段,但让我们假设现在是这种情况)。为了告诉训练阶段应该在训练期间包含哪些节点并告诉推理阶段哪些是测试数据,我们可以使用掩码,这些掩码是二进制向量,指示(使用 0 和 1)哪些节点属于每个特定掩码
torch_geometric.transforms.AddTrainValTestMask类可以获取我们的图形,让我们设置我们希望如何形成掩码,它将通过添加节点级拆分train_mask,val_mask以及test_mask属性。在我们的训练中,我们使用 30% 作为验证集,60% 作为测试集,而我们只保留 10% 作为训练。你可能有不同的分流比,但这样我们可能会有更真实的表现,我们不会轻易过拟合(我知道你可能不同意我的观点)!我们还可以打印图形信息和每组(掩码)的节点数。括号内的数字是每个属性张量的形状。
sk=masking(split="train_rest", num_splits = 1, num_val = 0.3, num_test= 0.6)g=msk(g)print(g)print()print("training samples",torch.sum(g.train_mask).item())print("validation samples",torch.sum(g.val_mask ).item())print("test samples",torch.sum(g.test_mask ).item())

在这一点上,我相信你同意我的观点,我们已经准备好构建我们的 GNN 模型类。正如我们商定的,我们将使用torch_geometric.nn.GCNConv类,但是您可以在PyTorch 几何文档中尝试许多其他层。
我们将堆叠GCNConv两层,第一层的输入特征等于我们图中的特征数量和一些任意数量的输出特征f。然后我们应用一个relu激活函数并将潜在特征传递到第二层,第二层的输出节点等于我们的类数(即 2)。在forward函数中,GCNConv可以接受许多参数x作为节点特征,edge_index并且edge_weight在我们的例子中我们只使用前两个参数。
class SocialGNN(torch.nn.Module):def __init__(self,num_of_feat,f):super(SocialGNN, self).__init__()self.conv1 = GCNConv(num_of_feat, f)self.conv2 = GCNConv(f, 2)def forward(self, data):x = data.x.float()edge_index = data.edge_indexx = self.conv1(x=x, edge_index=edge_index)x = F.relu(x)x = self.conv2(x, edge_index)return x
由于我们的模型将预测图中所有节点的类别,但是我们希望根据我们所处的阶段计算特定集合的损失和准确度。例如,在训练期间,我们想计算训练损失和准确度仅基于训练集,在这里我们应该使用我们的面具。我们将定义函数,masked_loss并masked_accuracy为其传递相应的掩码,并返回相应的损失和准确度。这个想法是计算所有节点的损失和准确性,并将其乘以掩码以将不需要的节点归零。
这个想法是计算所有节点的损失和精度,并将其乘以掩码,将不需要的节点归零。
def masked_loss(predictions,labels,mask):mask=mask.float()mask=mask/torch.mean(mask)loss=criterion(predictions,labels)loss=loss*maskloss=torch.mean(loss)return (loss)def masked_accuracy(predictions,labels,mask):mask=mask.float()mask/=torch.mean(mask)accuracy=(torch.argmax(predictions,axis=1)==labels).long()accuracy=mask*accuracyaccuracy=torch.mean(accuracy)return (accuracy)
现在,我们可以定义我们将使用torch.optim.Adam优化器的训练函数。我们将在一定数量的 epoch 中运行训练,并跟踪最佳验证准确性。我们还绘制了训练的各个时期的损失和准确度。
def train_social(net,data,epochs=10,lr=0.01):optimizer = torch.optim.Adam(net.parameters(), lr=lr) # 00001best_accuracy=0.0train_losses=[]train_accuracies=[]val_losses=[]val_accuracies=[]test_losses=[]test_accuracies=[]for ep in range(epochs+1):optimizer.zero_grad()out=net(data)loss=masked_loss(predictions=out,labels=data.y,mask=data.train_mask)loss.backward()optimizer.step()train_losses+=[loss]train_accuracy=masked_accuracy(predictions=out,labels=data.y,mask=data.train_mask)train_accuracies+=[train_accuracy]val_loss=masked_loss(predictions=out,labels=data.y,mask=data.val_mask)val_losses+=[val_loss]val_accuracy=masked_accuracy(predictions=out,labels=data.y,mask=data.val_mask)val_accuracies+=[val_accuracy]test_accuracy=masked_accuracy(predictions=out,labels=data.y,mask=data.test_mask)test_accuracies+=[test_accuracy]if np.round(val_accuracy,4)> np.round(best_accuracy ,4):print("Epoch {}/{}, Train_Loss: {:.4f}, Train_Accuracy: {:.4f}, Val_Accuracy: {:.4f}, Test_Accuracy: {:.4f}".format(ep+1,epochs, loss.item(), train_accuracy, val_accuracy, test_accuracy))best_accuracy=val_accuracyplt.plot(train_losses)plt.plot(val_losses)plt.plot(test_losses)plt.show()plt.plot(train_accuracies)plt.plot(val_accuracies)plt.plot(test_accuracies)plt.show()
此时,我们构建了所有必需的函数并准备实例化我们的模型并对其进行训练。我们将用 16 个过滤器构建模型,并将nn.CrossEntropyLoss用作我们的损失标准。下面,我们可以看到我们的简单模型在测试集上达到了非常不错的准确率,超过 87%。我们还可以分别通过顶部和底部图的 epoch 看到学习曲线(损失)和准确度的发展。
num_of_feat=g.num_node_featuresnet=SocialGNN(num_of_feat=num_of_feat,f=16)criterion=nn.CrossEntropyLoss()train_social(net,g,epochs=50,lr=0.1)
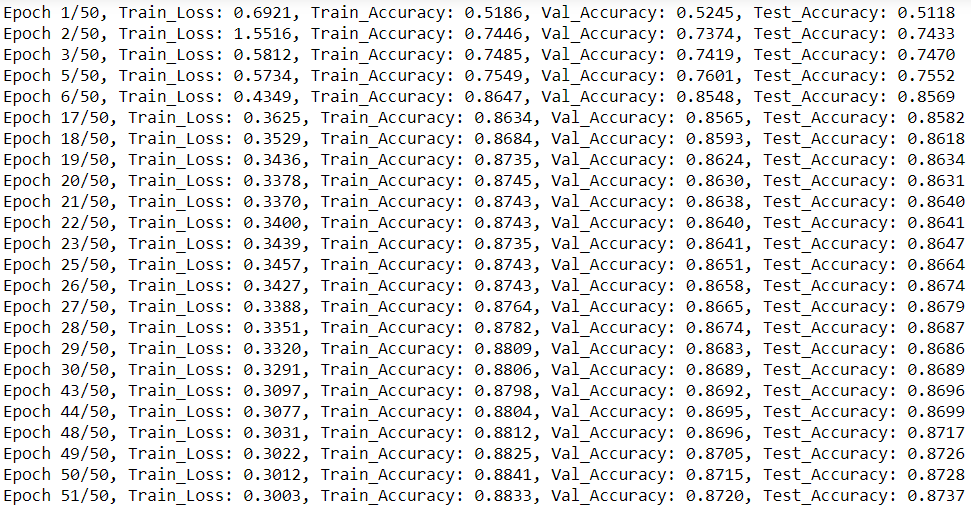
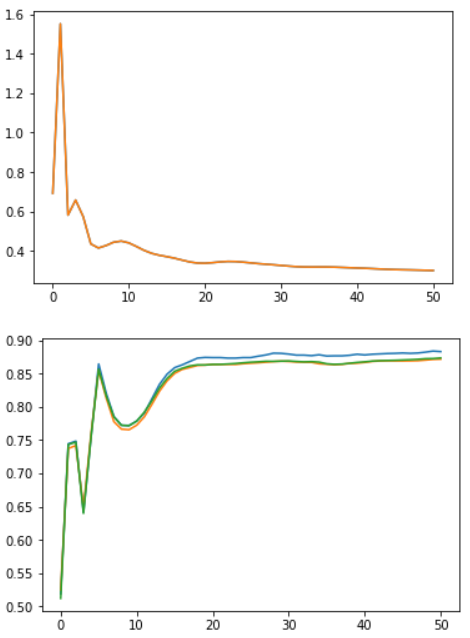
整个训练时期的学习曲线(顶部)和准确性(底部

若有收获,就点个赞吧
0 人点赞
