map和multimap都需要#include
1、基本操作函数
begin() 返回指向map头部的迭代器clear() 删除所有元素count() 返回指定元素出现的次数empty() 如果map为空则返回trueend() 返回指向map末尾的迭代器equal_range() 返回特殊条目的迭代器对erase() 删除一个元素find() 查找一个元素get_allocator() 返回map的配置器insert() 插入元素key_comp() 返回比较元素key的函数lower_bound() 返回键值>=给定元素的第一个位置max_size() 返回可以容纳的最大元素个数rbegin() 返回一个指向map尾部的逆向迭代器rend() 返回一个指向map头部的逆向迭代器size() 返回map中元素的个数swap() 交换两个mapupper_bound() 返回键值>给定元素的第一个位置value_comp() 返回比较元素value的函数
2、声明
#include<map>//头文件map<int, string> ID_Name;// 使用{}赋值是从c++11开始的,因此编译器版本过低时会报错,如visual studio 2012map<int, string> ID_Name = {{ 2015, "Jim" },{ 2016, "Tom" },{ 2017, "Bob" } };
3、迭代器
共有八个获取迭代器的函数: begin, end, rbegin,rend 以及对应的 cbegin, cend, crbegin,crend。
二者的区别在于,后者一定返回 const_iterator,而前者则根据map的类型返回iterator 或者 const_iterator。const情况下,不允许对值进行修改。如下面代码所示:
map<int,int>::iterator it;map<int,int> mmap;const map<int,int> const_mmap;it = mmap.begin(); //iteratormmap.cbegin(); //const_iteratorconst_mmap.begin(); //const_iteratorconst_mmap.cbegin(); //const_iterator
返回的迭代器可以进行加减操作,此外,如果map为空,则 begin = end。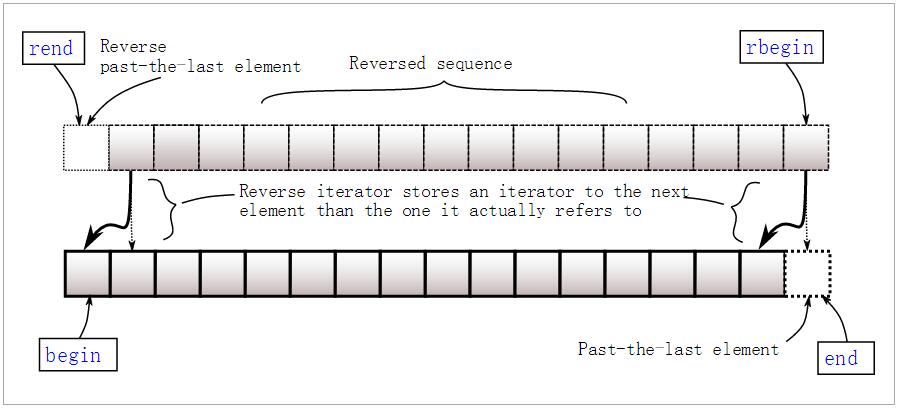
4、插入操作(insert)
4.1、用insert插入pair数据
//数据的插入--第一种:用insert函数插入pair数据#include <map>#include <string>#include <iostream>using namespace std;int main(){map<int, string> mapStudent;mapStudent.insert(pair<int, string>(1, "student_one"));mapStudent.insert(pair<int, string>(2, "student_two"));mapStudent.insert(pair<int, string>(3, "student_three"));map<int, string>::iterator iter;for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)cout<<iter->first<<' '<<iter->second<<endl;}
4.2、用insert函数插入value_type数据
//第二种:用insert函数插入value_type数据,下面举例说明#include <map>#include <string>#include <iostream>using namespace std;int main(){map<int, string> mapStudent;mapStudent.insert(map<int, string>::value_type (1, "student_one"));mapStudent.insert(map<int, string>::value_type (2, "student_two"));mapStudent.insert(map<int, string>::value_type (3, "student_three"));map<int, string>::iterator iter;for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)cout<<iter->first<<' '<<iter->second<<endl;}
4.3、用insert函数进行多个插入
// 插入单个键值对,并返回插入位置和成功标志,插入位置已经存在值时,插入失败pair<iterator,bool> insert (const value_type& val);//在指定位置插入,在不同位置插入效率是不一样的,因为涉及到重排iterator insert (const_iterator position, const value_type& val);// 插入多个void insert (InputIterator first, InputIterator last);//c++11开始支持,使用列表插入多个void insert (initializer_list<value_type> il);
#include <iostream>#include <map>int main(){std::map<char, int> mymap;// 插入单个值mymap.insert(std::pair<char, int>('a', 100));mymap.insert(std::pair<char, int>('z', 200));//返回插入位置以及是否插入成功std::pair<std::map<char, int>::iterator, bool> ret;ret = mymap.insert(std::pair<char, int>('z', 500));if (ret.second == false) {std::cout << "element 'z' already existed";std::cout << " with a value of " << ret.first->second << '\n';}//指定位置插入std::map<char, int>::iterator it = mymap.begin();mymap.insert(it, std::pair<char, int>('b', 300)); //效率更高mymap.insert(it, std::pair<char, int>('c', 400)); //效率非最高//范围多值插入std::map<char, int> anothermap;anothermap.insert(mymap.begin(), mymap.find('c'));// 列表形式插入anothermap.insert({ { 'd', 100 }, {'e', 200} });return 0;}
4.4、用数组方式插入数据
//第三种:用数组方式插入数据,下面举例说明#include <map>#include <string>#include <iostream>using namespace std;int main(){map<int, string> mapStudent;mapStudent[1] = "student_one";mapStudent[2] = "student_two";mapStudent[3] = "student_three";map<int, string>::iterator iter;for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)cout<<iter->first<<' '<<iter->second<<endl;}
以上三种用法,虽然都可以实现数据的插入,但是它们是有区别的,当然了第一种和第二种在效果上是完成一样的,用insert函数插入数据,在数据的 插入上涉及到集合的唯一性这个概念,即当map中有这个关键字时,insert操作是插入数据不了的,但是用数组方式就不同了,它可以覆盖以前该关键字对 应的值,用程序说明
mapStudent.insert(map
mapStudent.insert(map
上面这两条语句执行后,map中1这个关键字对应的值是“student_one”,第二条语句并没有生效,那么这就涉及到我们怎么知道insert语句是否插入成功的问题了,可以用pair来获得是否插入成功,程序如下:
pair
Insert_Pair = mapStudent.insert(map
我们通过pair的第二个变量来知道是否插入成功,它的第一个变量返回的是一个map的迭代器,如果插入成功的话Insert_Pair.second应该是true的,否则为false。
验证插入函数的作用效果#include <map>#include <string>#include <iostream>using namespace std;int main(){map<int, string> mapStudent;pair<map<int, string>::iterator, bool> Insert_Pair;Insert_Pair = mapStudent.insert(pair<int, string>(1, "student_one"));if(Insert_Pair.second == true)cout<<"Insert Successfully"<<endl;elsecout<<"Insert Failure"<<endl;Insert_Pair = mapStudent.insert(pair<int, string>(1, "student_two"));if(Insert_Pair.second == true)cout<<"Insert Successfully"<<endl;elsecout<<"Insert Failure"<<endl;map<int, string>::iterator iter;for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)cout<<iter->first<<' '<<iter->second<<endl;}验证数组形式插入数据的效果#include <map>#include <string>#include <iostream>using namespace std;int main(){map<int, string> mapStudent;mapStudent[1] = "student_one";mapStudent[1] = "student_two";mapStudent[2] = "student_three";map<int, string>::iterator iter;for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)cout<<iter->first<<' '<<iter->second<<endl;}
5、查找、删除、交换
查找:// 关键字查询,找到则返回指向该关键字的迭代器,否则返回指向end的迭代器// 根据map的类型,返回的迭代器为 iterator 或者 const_iteratoriterator find (const key_type& k);const_iterator find (const key_type& k) const;删除:// 删除迭代器指向位置的键值对,并返回一个指向下一元素的迭代器iterator erase( iterator pos )// 删除一定范围内的元素,并返回一个指向下一元素的迭代器iterator erase( const_iterator first, const_iterator last );// 根据Key来进行删除, 返回删除的元素数量,在map里结果非0即1size_t erase( const key_type& key );// 清空map,清空后的size为0void clear();交换:// 就是两个map的内容互换void swap( map& other );
6、容量
// 查询map是否为空bool empty();// 查询map中键值对的数量size_t size();// 查询map所能包含的最大键值对数量,和系统和应用库有关。// 此外,这并不意味着用户一定可以存这么多,很可能还没达到就已经开辟内存失败了size_t max_size();// 查询关键字为key的元素的个数,在map里结果非0即1size_t count( const Key& key ) const; //
7、排序
map中的元素是自动按Key升序排序,所以不能对map用sort函数;
这里要讲的是一点比较高深的用法了,排序问题,STL中默认是采用小于号来排序的,以上代码在排序上是不存在任何问题的,因为上面的关键字是int 型,它本身支持小于号运算,在一些特殊情况,比如关键字是一个结构体或者自定义类,涉及到排序就会出现问题,因为它没有小于号操作,insert等函数在编译的时候过 不去,下面给出两个方法解决这个问题。
7.1 小于号 < 重载
#include <iostream>#include <string>#include <map>using namespace std;typedef struct tagStudentinfo{int niD;string strName;bool operator < (tagStudentinfo const& _A) const{ //这个函数指定排序策略,按niD排序,如果niD相等的话,按strName排序if (niD < _A.niD) return true;if (niD == _A.niD)return strName.compare(_A.strName) < 0;return false;}}Studentinfo, *PStudentinfo; //学生信息int main(){int nSize; //用学生信息映射分数map<Studentinfo, int>mapStudent;map<Studentinfo, int>::iterator iter;Studentinfo studentinfo;studentinfo.niD = 1;studentinfo.strName = "student_one";mapStudent.insert(pair<Studentinfo, int>(studentinfo, 90));studentinfo.niD = 2;studentinfo.strName = "student_two";mapStudent.insert(pair<Studentinfo, int>(studentinfo, 80));for (iter = mapStudent.begin(); iter != mapStudent.end(); iter++)cout << iter->first.niD << ' ' << iter->first.strName << ' ' << iter->second << endl;return 0;}
7.2 仿函数的应用
//第二种:仿函数的应用,这个时候结构体中没有直接的小于号重载,程序说明#include <iostream>#include <map>#include <string>using namespace std;typedef struct tagStudentinfo{int niD;string strName;}Studentinfo, *PStudentinfo; //学生信息class sort{public:bool operator() (Studentinfo const &_A, Studentinfo const &_B) const{if (_A.niD < _B.niD)return true;if (_A.niD == _B.niD)return _A.strName.compare(_B.strName) < 0;return false;}};int main(){//用学生信息映射分数map<Studentinfo, int, sort>mapStudent;map<Studentinfo, int>::iterator iter;Studentinfo studentinfo;studentinfo.niD = 1;studentinfo.strName = "student_one";mapStudent.insert(pair<Studentinfo, int>(studentinfo, 90));studentinfo.niD = 2;studentinfo.strName = "student_two";mapStudent.insert(pair<Studentinfo, int>(studentinfo, 80));for (iter = mapStudent.begin(); iter != mapStudent.end(); iter++)cout << iter->first.niD << ' ' << iter->first.strName << ' ' << iter->second << endl;system("pause");}
8、unordered_map
在c++11标准前,c++标准库中只有一种map,但是它的底层实现并不是适合所有的场景,如果我们需要其他适合的map实现就不得不使用比如boost库等三方的实现,在c++11中加了一种map unordered_map,unordered_set,他们的实现有什么不同呢?
map底层采用的是红黑树的实现查询的时间复杂度为O(logn),看起来并没有unordered_map快,但是也要看实际的数据量,虽然unordered_map的查询从算法上分析比map快,但是它有一些其它的消耗,比如哈希函数的构造和分析,还有如果出现哈希冲突解决哈希冲突等等都有一定的消耗,因此unordered_map的效率在很大的程度上由它的hash函数算法决定,而红黑树的效率是一个稳定值。
unordered_map的底层采用哈希表的实现,查询的时间复杂度为是O(1)。所以unordered_map内部就是无序的,数据是按散列函数插入到槽里面去的,数据之间无顺序可言,如果我们不需要内部有序,这种实现是没有问题的。unordered_map属于关联式容器,采用std::pair保存key-value形式的数据。用法与map一致。特别的是,STL中的map因为是有序的二叉树存储,所以对key值需要有大小的判断,当使用内置类型时,无需重载operator < ;但是用用户自定义类型的话,就需要重载operator < 。 unoredered_map全程使用不需要比较元素的key值的大小,但是,对于元素的==要有判断,又因为需要使用hash映射,所以,对于非内部类型,需要程序员为其定义这二者的内容,对于内部类型,就不需要了。unordered库使用“桶”来存储元素,散列值相同的被存储在一个桶里。当散列容器中有大量数据时,同一个桶里的数据也会增多,造成访问冲突,降低性能。为了提高散列容器的性能,unordered库会在插入元素是自动增加桶的数量,不需要用户指定。但是,用户也可以在构造函数或者rehash()函数中,指定最小的桶的数量。
还有另外一点从占用内存上来说因为unordered_map才用hash结构会有一定的内存损失,它的内存占用回高于map。
最后就是她们的场景了,首先如果你需要对map中的数据排序,就首选map,他会把你的数据按照key的自然排序排序(由于它的底层实现红黑树机制所以会排序),如果不需要排序,就看你对内存和cpu的选择了,不过一般都会选择unordered_map,它的查找效率会更高。
至于使用方法和函数,两者差不多,由于篇幅限制这里不再赘述,unordered_multimap用法亦可类推。

若有收获,就点个赞吧
0 人点赞
