一、sql
1、数据库基础
1.1、什么是数据库?
保存有组织的数据的容器(通常是一个文件或一组文件)。
注意:数据库和数据库软件是两个概念,数据库软件是操作数据库的一个工具。
称为DBMS(数据库管理系统)
1.2、表
某种特定类型数据的结构化清单。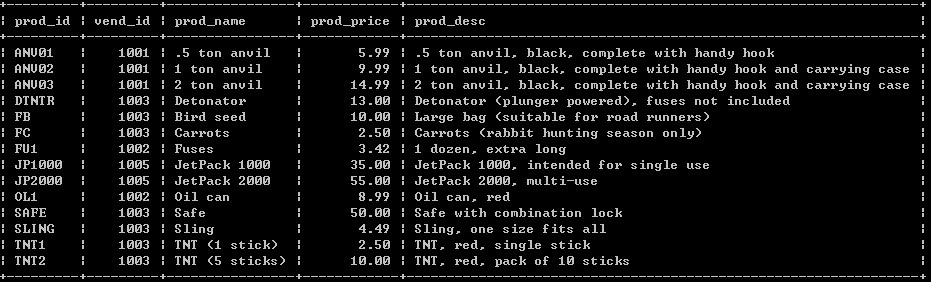
1.3、列和数据类型
表由列组成。列中存储着表中的信息。
列:表中的一个字段。所有表都是由一个或者多个列组成的。
数据类型:每个列都有相同的数据类型。
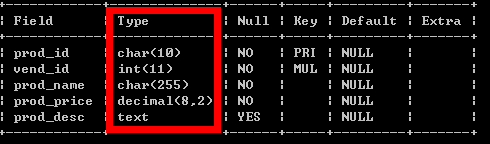
主键:Java中一般都是Long类型,对应MySQL就是BIGINT
日期:Java中一般都是Date类型,对应MySQL就是timestamp
mysql java 类型映射
| MySQL数据类型 | JAVA数据类型 | JDBC TYPE | 普通变量类型 | 主键类型 |
|---|---|---|---|---|
| BIGINT | Long | BIGINT | 支持 | 支持 |
| TINYINT | Byte | TINYINT | 支持 | 不支持 |
| SMALLINT | Short | SMALLINT | 支持 | 不支持 |
| MEDIUMINT | Integer | INTEGER | 支持 | 支持 |
| INTEGER | Integer | INTEGER | 支持 | 支持 |
| INT | Integer | INTEGER | 支持 | 支持 |
| FLOAT | Float | REAL | 支持 | 不支持 |
| DOUBLE | Double | DOUBLE | 支持 | 不支持 |
| DECIMAL | BigDecimal | DECIMAL | 支持 | 不支持 |
| NUMERIC | BigDecimal | DECIMAL | 支持 | 不支持 |
| CHAR | String | CHAR | 支持 | 不支持 |
| VARCHAR | String | VARCHAR | 支持 | 不支持 |
| TINYBLOB | DataTypeWithBLOBs.byte[] | BINARY | 不支持 | 不支持 |
| TINYTEXT | String | VARCHAR | 支持 | 不支持 |
| BLOB | DataTypeWithBLOBs.byte[] | BINARY | 不支持 | 不支持 |
| TEXT | DataTypeWithBLOBs.String | LONGVARCHAR | 不支持 | 不支持 |
| MEDIUMBLOB | DataTypeWithBLOBs.byte[] | LONGVARBINARY | 不支持 | 不支持 |
| MEDIUMTEXT | DataTypeWithBLOBs.String | LONGVARCHAR | 不支持 | 不支持 |
| LONGBLOB | DataTypeWithBLOBs.byte[] | LONGVARBINARY | 不支持 | 不支持 |
| LONGTEXT | DataTypeWithBLOBs.String | LONGVARCHAR | 不支持 | 不支持 |
| DATE | Date | DATE | 支持 | 不支持 |
| TIME | Date | TIME | 支持 | 不支持 |
| YEAR | Date | DATE | 不支持 | 不支持 |
| DATETIME | Date | TIMESTAMP | 支持 | 不支持 |
| TIMESTAMP | Date | TIMESTAMP | 支持 | 不支持 |
数值类型
MySQL 支持所有标准 SQL 数值数据类型。
这些类型包括严格数值数据类型(INTEGER、SMALLINT、DECIMAL 和 NUMERIC),以及近似数值数据类型(FLOAT、REAL 和 DOUBLE PRECISION)。
关键字INT是INTEGER的同义词,关键字DEC是DECIMAL的同义词。
BIT数据类型保存位字段值,并且支持 MyISAM、MEMORY、InnoDB 和 BDB表。
作为 SQL 标准的扩展,MySQL 也支持整数类型 TINYINT、MEDIUMINT 和 BIGINT。下面的表显示了需要的每个整数类型的存储和范围。
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 Bytes | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 Bytes | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 Bytes | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 Bytes | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 Bytes | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 Bytes | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 Bytes | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
日期和时间类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
每个时间类型有一个有效值范围和一个”零”值,当指定不合法的MySQL不能表示的值时使用”零”值。
TIMESTAMP类型有专有的自动更新特性,将在后面描述。
| 类型 | 大小 ( bytes) |
范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | ‘-838:59:59’/‘838:59:59’ | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038 结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 |
YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。该节描述了这些类型如何工作以及如何在查询中使用这些类型。
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
1.4、行
1.5、主键
主键:一列(或一组列),其值能够唯一区分表中每个行。
主键:一般名字都是id,类型是BIGINT 对应Java类型是Long,MySQL主键一般都是自增(类似++),从1开始
2、什么是SQL?
SQL (Structured Query Language) :结构化查询语言。是一种专门用来与数据库通信的语言。
一般说法:SQL语句。
优点:
1、不是某个特定数据库供应商专有的语言。几乎所有的DBMS都支持SQL,所以,学习此语言使你几乎能与所有数据库打交道
2、简单易学
3、是一种强有力的语言
1.3、动手实践
DDL( Data Definition Language数据定义语言)——用来建立数据库、数据库对象和定义其列——CREATE TABLE 、DROP TABLE、ALTER TABLE 等
DML( Data Manipulation Language数据操作语言)——查询、插入、删除和修改数据库中的数据;——SELECT、INSERT、 UPDATE 、DELETE等;
DCL( Data Control Language数据控制语言)——用来控制存取许可、存取权限等;——GRANT、REVOKE 等;
功能函数——日期函数、数学函数、字符函数、系统函数等
银行、证券、互联网金融。。国企用Oracle比较多。Oracle数据库是收费的
MySQL是免费开源的:被Oracle收购 10亿美金
开源:就是源代码发布在网上,任何都可以看,都可以下载下来自己修改使用等待。
Java也是开源的,但是JDK不是开源的。
OpenJDK这个是开源的
游标、存储过程这些MySQL中比较弱,Oracle比较强。
二、MySql简介
1、什么是MySql
MySql是一种DBMS,一个数据库管理软件。
2、为什么需要mysql?
1、 低成本:开源,开源免费使用、修饰。
2、 性能好,非常快速。
3、 简单:容易安装和使用。
3、连接mysql
在命令行输入:mysql -u root –p
exit:退出
u:user 用户名
p:password 密码
C:\Program Files\MySQL\MySQL Server 8.0\bin
4、mysql客户端工具
1、navicat for mysql
2、SQLyog
3、Workbench
三、使用mysql
1、连接
2、选择数据库
3、了解数据库和表
显示数据库列表:show databases;
显示数据库中的表:show tables;
显示表中的列:desc customers;
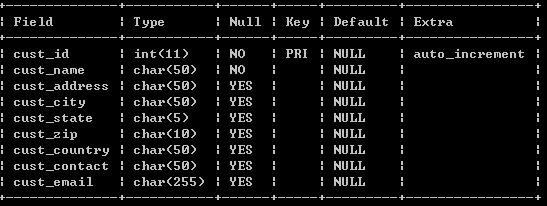
Auto_increment:一个自动增长的列, 数据库管理的,不需要用户去管理,并且可以作为主键。
四、DDL数据定义语言
-- IF NOT EXISTS:如果不存在的情况下创建 如果存在则不创建-- CREATE DATABASE IF NOT EXISTS db_namecreate database if not exits ruizhi ;-- 带上编码create database if not exists ruizhi2default character set = 'utf8'collate = 'utf8_general_ci';CREATE DATABASE IF NOT EXISTS mall2DEFAULT CHARACTER SET 'utf8'DEFAULT COLLATE 'utf8_general_ci';
DROP DATABASE IF EXISTS db_name
USE db_name
CREATE TABLE IF NOT EXISTS tbl_name (column_name column_type);create table if not exists customers(id bigint not null auto_increment,name varchar(50) not null,address varchar(50) null,city varchar(50),primary key(id))engine=innodb;
DROP TABLE IF EXISTS table_name ;drop table if exists customers;
五、创建和操纵表
1、创建表
一般有两种方式创建表:
1、使用客户端工具
2、直接操作mysql
1.1、创建表基础
CREATE TABLE customers(cust_id int NOT NULL AUTO_INCREMENT,cust_name char(50) NOT NULL ,cust_address char(50) NULL ,cust_city char(50) NULL ,cust_state char(5) NULL ,cust_zip char(10) NULL ,cust_country char(50) NULL ,cust_contact char(50) NULL ,cust_email char(255) NULL ,PRIMARY KEY (cust_id)) ENGINE=InnoDB;
1.2、使用null值
CREATE TABLE orders(order_num int NOT NULL AUTO_INCREMENT,order_date datetime NOT NULL ,cust_id int NOT NULL ,PRIMARY KEY (order_num)) ENGINE=InnoDB;
CREATE TABLE vendors(vend_id int NOT NULL AUTO_INCREMENT,vend_name char(50) NOT NULL ,vend_address char(50) NULL ,vend_city char(50) NULL ,vend_state char(5) NULL ,vend_zip char(10) NULL ,vend_country char(50) NULL ,PRIMARY KEY (vend_id)) ENGINE=InnoDB;
1.3、主键、外键再介绍
使用PRIMARY KEY (order_num, order_item)
CREATE TABLE orderitems(order_num int NOT NULL ,order_item int NOT NULL ,prod_id char(10) NOT NULL ,quantity int NOT NULL ,item_price decimal(8,2) NOT NULL ,PRIMARY KEY (order_num, order_item)) ENGINE=InnoDB;
外键表示一个表中的一个字段被另一个表中的一个字段引用。外键对相关表中的数据造成了限制
CREATE TABLE categories(cat_id int not null auto_increment primary key,cat_name varchar(255) not null,cat_description text) ENGINE=InnoDB;CREATE TABLE products(prd_id int not null auto_increment primary key,prd_name varchar(355) not null,prd_price decimal,cat_id int not null,FOREIGN KEY fk_cat(cat_id)REFERENCES categories(cat_id)ON UPDATE CASCADEON DELETE RESTRICT)ENGINE=InnoDB;create table t_user(id BIGINT not null auto_increment primary key,userName varchar(50) not null);create table t_goods(id bigint not null auto_increment primary key,user_id bigint not null,foreign key fk_user(user_id)references t_user(id));
1.4、AUTO_INCREMENT
一般用来主键自增上,默认从1开始,每次增加1,插入数据可以不插入这条,会自动补上。
create table if not exists t_goods(id bigint(10) not null AUTO_INCREMENT COMMENT 'ID主键',goods_name varchar(100) null COMMENT '商品名称',goods_price NUMERIC(8) null COMMENT'商品名称',PRIMARY KEY (id));
1.5、指定默认值
CREATE TABLE orderitems(order_num int NOT NULL ,order_item int NOT NULL ,prod_id char(10) NOT NULL ,quantity int NOT NULL default 1,item_price decimal(8,2) NOT NULL ,PRIMARY KEY (order_num, order_item)) ENGINE=InnoDB;
1.6、引擎
InnoDB存储引擎
InnoDB是事务型数据库的首选引擎,支持事务安全表(ACID),支持行锁定和外键
MyISAM存储引擎
MyISAM基于ISAM存储引擎,并对其进行扩展。它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一。MyISAM拥有较高的插入、查询速度,但不支持事物
MEMORY存储引擎
MEMORY存储引擎将表中的数据存储到内存中,未查询和引用其他表数据提供快速访问。
1.7、更新表结构
常用的语法格式如下:ALTER TABLE <表名> [修改选项]修改选项的语法格式如下:{ ADD COLUMN <列名> <类型>| CHANGE COLUMN <旧列名> <新列名> <新列类型>| ALTER COLUMN <列名> { SET DEFAULT <默认值> | DROP DEFAULT }| MODIFY COLUMN <列名> <类型>| DROP COLUMN <列名>| RENAME TO <新表名> }
ALTER TABLE <表名> ADD <新字段名> <数据类型>;ALTER TABLE t_user ADD COLUMN `password` varchar(50) null;
ALTER TABLE <表名> MODIFY <字段名> <数据类型>alter table t_user modify `password` varchar(100) null;
ALTER TABLE <表名> DROP <字段名>;alter table t_user drop `password`;
ALTER TABLE <表名> CHANGE <旧字段名> <新字段名> <新数据类型>;alter table t_user change `password` `pwd` varchar(100);
ALTER TABLE <旧表名> RENAME [TO] <新表名>;ALTER TABLE t_user RENAME t_emp;
ALTER TABLE table 表名 add constraint FK_ID foreign key(外键字段名) REFERENCES 外表表名(对应的表的主键字段名);Alter tableALTER TABLE orderitems ADD CONSTRAINTfk_orderitems_orders FOREIGN KEY (order_num) REFERENCES orders (order_num);
ALTER [IGNORE] TABLE tbl_name DROP FOREIGN KEY fk_symbolalter table t_class drop FOREIGN KEY fk_student_id;alter table t_class drop foreign key t_class_ibfk_1;
1.8、删除表
DROP table t_user;
六、导入、导出数据库数据
-- 导出数据mysqldump -u [数据库用户名] -p [要备份的数据库名称]>[备份文件的保存路径]mysqldump -u root -p ruizhi > d:/data/a.sql;-- 导入数据mysql -u用户名 -p 数据库名 < 数据库名.sqlmysql -uroot -p ruizhi < d:/data/a.sql注意事项:导入和导出都不是在mysql中的,并且最后没有";"-- 导出所有数据库mysqldump -uroot -p --all-databases > d:\sql\sqlfile.sql
七、插入数据
1、数据插入
插入可以用几种方式:
1、 插入完整的行
2、 插入行的一部分
3、 插入多行
4、 插入某些查询的结果。
2、插入完整的行
-- 列可以不添加 但是后面的值需要一一对应 最好是增加列INSERT INTO table_name ( field1, field2,...fieldN )VALUES( value1, value2,...valueN );-- 列一一对应insert into customers(name,address,city) values('张三','北京市区XXX号','北京市');-- 没有列 id需要设置为null 可以自增insert into customers values(null,'张三','北京市区XXX号','北京市');
3、插入多行数据
INSERT INTO table_name ( field1, field2,...fieldN )VALUES( value1, value2,...valueN ),( value1, value2,...valueN ),( value1, value2,...valueN );insert into customers(name,address,city) values('张三','北京市区XXX号','北京市'),('李四','南京市区XXX号','南京市'),('王五','上海市区XXX号','上海市');
INSERT INTO table_name(column_list)SELECTselect_listFROManother_table;insert into customers(name,address,city) select name,address,city from customers;
八、更新和删除数据
1、更新数据
UPDATE table_name SET field1=new-value1, field2=new-value2[WHERE Clause]update customers set city = '深圳';update customers set name='老王' where id = 2;update customers set name='老王',address='福州市' where id = 3;
2、删除数据
DELETE FROM table_name [WHERE Clause]delete from customers where id = 1;delete from customers where name='老王' or id = 4;
九、检索数据
SELECT 列1,列2,列3 FROM table_name [WHERE Clause];select id from customers;select id,name from customers;-- 查询所有列 * 性能较低 不建议使用select * from customers;-- 去除重复查询 distinct只能用在查询第一个列select distinct name,id from customers;
1、限制结果
SELECTcolumn1,column2,...FROMtableLIMIT offset , count;-- offset:起始位置 从0开始-- count:查询多少条数据select * from customers limit 0,5;
-- 带有一个参数的 LIMIT 子句时,此参数将用于确定从结果集的开头返回的最大行数。SELECTselect_listFROMtableLIMIT count;
十、检索排序数据
1、排序数据
SELECT column1, column2,...FROM tblORDER BY column1 [ASC|DESC], column2 [ASC|DESC],...-- 默认asc 正序select * from customers order by id;select * from customers order by id asc;-- 倒序select * from customers order by id desc;
2、排序多个列
select * from customers order by id desc, name asc;SELECT prod_id,prod_price,prod_name FROM products ORDER BY prod_price,prod_name;首先按照价格排序,然后在按照名称排序
3、指定排序方向
降序使用:DESCSELECT prod_id,prod_price,prod_name FROM products ORDER BY prod_price DESC;SELECT prod_id,prod_price,prod_name FROM products ORDER BY prod_price DESC,prod_name;首先对prod_price降序,然后对prod_name升序。注意:如果现在多个列上进行降序排序,必须对每个列指定DESC关键字。升序:ASC,默认就是升序例子:找出最贵的物品SELECT prod_price FROM products ORDER BY prod_price DESC LIMIT 1;
4、排序和limit查询最大值、最小值
-- 查询ID最大值select * from customers order by id desc limit 1;--查询ID最小值select * from customers order by id asc limit 1;
十一、数据过滤
1、使用WHERE子句
SELECTselect_listFROMtable_nameWHEREsearch_condition;例如:SELECT prod_name ,prod_price FROM products WHERE prod_price=2.50;注意:同时使用ORDER BY 和WHERE子句时,应该让ORDER BY位于WHERE之后,否则会出错。
2、WHERE子句操作符
| WHERE子句操作符 | |
|---|---|
| 操作符 | 说明 |
| = | 等于 |
| <> | 不等于 |
| != | 不等于 |
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
| BETWEEN …AND … | 在指定的两个值之间 |
| () | 括号:将表达式放在里面,优先级比较高 |
2.1、检查单个值
SELECT prod_name, prod_price FROM products WHERE prod_name='fuses';SELECT prod_name , prod_price FROM products WHERE prod_price < 10;SELECT prod_name , prod_price FROM products WHERE prod_price <= 10;
2.2、不匹配检查
SELECT vend_id,prod_name FROM products WHERE vend_id <> 1003;注意:数值类型比较不需要引号,字符类型需要。SELECT vend_id,prod_name FROM products WHERE vend_id != 1003;
2.3、范围值检查
注意:包括开始值和结束值
SELECT prod_name,prod_price FROM products WHERE prod_price BETWEEN 5 AND 10;
2.4、空值检查
SELECT prod_name,prod_price FROM products WHERE prod_price IS(IS NOT) NULL;SELECT cust_id FROM customers WHERE cust_emal IS NULL;
十二、数据过滤
1、组合WHERE子句
1.1、AND操作符
SELECT prod_id,vend_id,prod_price,prod_nameFROMproducts WHERE vend_id=1003 AND prod_price <=10;
1.2、OR操作符
SELECT vend_id,prod_name,prod_priceFROM productsWHERE vend_id = 1002 OR vend_id = 1003;
1.3、计算次序
SELECT vend_id,prod_name , prod_priceFROM productsWHERE vend_id = 1002 OR vend_id = 1003AND prod_price >= 10;
这里会优先计算AND
SELECT vend_id, prod_name , prod_price FROM products WHERE (vend_id = 1002 OR vend_id = 1003)AND prod_price >= 10;
可以添加括号来控制执行顺序
员工号7698、7782、7839,并且薪资小于3000
拿到薪资大于3000,或者薪资小于2000
2、IN操作符
SELECT prod_name,prod_price FROM products WHERE vend_id IN (1002,1003)ORDER BY prod_name;同上SELECT prod_name,prod_price FROM products WHERE vend_id =1002 OR vend_id =1003ORDER BY prod_name;
使用IN的优势:
1、 清楚直观
2、 容易管理
3、 比OR操作符执行快
4、 包含其他SELECT语句
3、NOT操作符
是in取反 不在里面
SELECT prod_name,prod_priceFROM productsWHERE vend_id NOT IN(1002,1003)ORDER BY prod_name;
注意:mysql中可以使用NOT对IN、BETWEEN、EXISTS子句取反。
十三、通配符进行过滤
1、LIKE操作符
1.1、百分号(%)通配符
%:表示任意出现的次数
SELECT prod_id,prod_name FROM products WHERE prod_name LIKE 'jet%';
SELECT prod_id,prod_nameFROM productsWHERE prod_name LIKE ‘%anvil%’;
SELECT prod_nameFROM productsWHERE prod_name LIKE ‘s%e’;
1.2、下划线(_)通配符
和%一样,但是只是匹配一个字符
SELECT prod_id,prod_nameFROM prodcutsWHERE prod_name LIKE ‘_on anvil’;
LIKE:主要是用户模糊搜索的。通常配合%、_一起使用。如果不加占位符,就是等于判断。
十四、创建计算字段
1、计算字段
2、拼接字段
SELECT concat(vend_name,’(’,vend_country,’)’)FROM vendorsORDER BY vend_name;
SELECT concat(RTrim(vend_name),’(’,RTrim(vend_country),’)’)FROM vendorsORDER BY vend_name;
RTrim(),LTrim(),Trim():去掉右边、左边、两边空格
别名:
SELECT concat(RTrim(vend_name),’(’,RTrim(vend_country),’)’) AS vend_titleFROM vendorsORDER BY vend_name;select RTim('111 ') from dual;
3、执行算术计算
SELECT prod_id,quantity,item_price FROM orderitems WHERE order_num =20005;
计算后:
SELECT prod_id,quantity,quantity*item_price AS expanded_priceFROM orderitems WHERE order_num=20005;
十五、使用数据处理函数
1、函数
2、使用函数
2.1、文本(varchar)处理函数
SELECT vend_name,Upper(vend_name) AS vend_name_upcaseFROM vendors ORDER BY vend_name;
| 文本处理函数 | |
|---|---|
| Length() | 返回串的长度 |
| Lower() | 将串转换为小写 |
| LTrim() | 去掉串左边的空格 |
| RTrim() | 去掉串右边的空格 |
| SUBSTRING(s, start, length) | 从字符串 s 的 start 位置截取长度为 length 的子字符串,等同于 SUBSTR(s, start, length) |
| Upper() | 将串转换为大写 |
2.2、日期和时间处理函数
| 常用日期和时间处理函数 | |
|---|---|
| Date() | 返回日期时间的日期部分 |
| Date_Format(d,格式) | 返回一个格式化的日期或时间串 |
| now() | 函数返回当前的日期和时间 |
select date(order_date) from orders;SELECT cust_id,order_num FROM orders WHERE order_date = ‘2005-09-01’;SELECT cust_id,order_num FROM orders WHERE DATE(order_date) = ‘2005-09-01’;SELECT cust_id,order_num FROM orders WHERE Date(order_date) BETWEEN ‘2005-09-01’ AND ‘2005-09-30’;select * from orders where order_date between '2005-01-01' and '2010-01-01';SELECT DATE_FORMAT(NOW(),'%Y-%m-%d %H:%i:%s') from orders;
可以使用的格式有:
| 格式 | 描述 |
|---|---|
| %c | 月,数值 |
| %d | 月的天,数值(00-31) |
| %H | 小时 (00-23) |
| %i | 分钟,数值(00-59) |
| %k | 小时 (0-23) |
| %l | 小时 (1-12) |
| %M | 月名 |
| %m | 月,数值(00-12) |
| %S | 秒(00-59) |
| %s | 秒(00-59) |
| %Y | 年,4 位 |
| %y | 年,2 位 |
-- dual:虚拟表 可以用来计算select 60 * 60 from dual;select 10 * 5 from dual;select now() from dual;
2.3、数值处理函数
| 常用数值处理函数 | |
|---|---|
| Abs() | 返回一个数的绝对值 |
| Rand() | 返回一个随机数 |
select rand() from orders;select rand() from dual;select abs(-1) from dual;select abs(-10) from dual;select id,rand() from t_goods;
2.4、日期函数now()
-- NOW() 函数返回当前的日期和时间。CREATE TABLE t_orders(id int NOT NULL,productName varchar(50) NOT NULL,orderDate datetime NOT NULL DEFAULT NOW(),PRIMARY KEY (id));-- 默认添加日期INSERT INTO t_orders (id,productName) VALUES (1,'Computer');mysql> select * from t_orders;+----+-------------+---------------------+| id | productName | orderDate |+----+-------------+---------------------+| 1 | Computer | 2022-04-09 00:37:05 |+----+-------------+---------------------+-- 插入当前时间insert into t_orders(id,productName,orderDate) values(2,'iphone',now());mysql> select * from t_orders;+----+-------------+---------------------+| id | productName | orderDate |+----+-------------+---------------------+| 1 | Computer | 2022-04-09 00:37:05 || 2 | iphone | 2022-04-09 00:38:30 |+----+-------------+---------------------+
十六、汇总数据
1、聚集函数
运行在行组上,计算和返回单个值的函数。
| SQL聚集函数 | |
|---|---|
| 函数 | 说明 |
| AVG() | 返回某列的平均值 |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
| SUM() | 返回某列的值之和 |
1.1、AVG()函数
SELECT avg(prod_price) as avg_price FROM products;SELECT avg(prod_price) as avg_price FROM products WHERE vend_id=1003;
1.2、COUNT()函数
count():不忽略null 不推荐使用
count(1):和count()用法一致
count(某列):忽略null
SELECT COUNT(*) AS num_cust FROM customers;SELECT COUNT(cust_email) AS num_cust FROM customers;
1.3、MAX()函数
SELECT MAX(prod_price) AS max_price FROM products;
1.4、MIN()函数
SELECT MIN(prod_price) AS min_price FROM products;
1.5、SUM()函数
SELECT SUM(quantity) AS items_ordered FROM orderitems WHERE order_num = 20005;SELECT SUM(quantity * item_price) AS total_price FROM orderitems WHERE order_num = 20005;
1.2、聚集不同值(去重复)
DISTINCT必须放在第一列前面:去重后面列的重复值,如果是多列,就是多列一起去重
SELECT AVG(DISTINCT prod_price) AS avg_price FROM products WHERE vend_id=1003;
1.3、组合聚集函数
SELECT COUNT(*) AS num_items,MIN(prod_price) AS prie_min,MAX(prod_price) AS price_max,AVG(prod_price) AS price_avgFROM products;selectcount(*) as '总数',min(prod_price) as '最低价格',max(prod_price) as '最高价格',avg(prod_price) as '平均价格'from products;
十七、分组数据(非常重要)
在SELECT语句中使用HAVING子句来指定一组行或聚合的过滤条件。
HAVING子句通常与GROUP BY子句一起使用,以根据指定的条件过滤分组。如果省略GROUP BY子句,则HAVING子句的行为与WHERE子句类似。
请注意,HAVING子句将过滤条件应用于每组分行,而WHERE子句将过滤条件应用于每个单独的行。
having:和group by配合后,只能放group by后的列,或者聚合函数
1、数据分组
SELECT COUNT(*) AS num_prods FROM products WHERE vend_id = 1003;
分组:允许把数据分为多个逻辑组,以便能对每个组进行聚集计算。
2、创建分组
SELECT vend_id ,COUNT(*) AS num_prodsFROM productsGROUP BY vend_id;
3、过滤分组
HAVING过滤分组后的数据:后面只能跟前面查询列表,或者函数(对分组后的数据进行计算)
SELECT cust_id,COUNT(*) AS ordersFROM ordersGROUP BY cust_idHAVING COUNT(*) >= 2;
SELECT vend_id,COUNT(*) AS num_prodsFROM productsWHERE prod_price >= 10GROUP BY vend_idHAVING COUNT(*) >= 2;
4、分组和排序
SELECT order_num,SUM(quantity*item_price) AS ordertotalFROM orderitemsGROUP BY order_numHAVING SUM(quantity*item_price) = 50;
对分组后的组进行排序
SELECT order_num,SUM(quantity*item_price) AS ordertotalFROM orderitemsGROUP BY order_numHAVING SUM(quantity*item_price) >= 50ORDER BY ordertotal;select order_num,sum(quantity * item_price) as ordertotalfrom orderitemsgroup by order_numhaving sum(ordertotal) >= 50order by order_num;select order_num,sum(quantity * item_price) as ordertotalfrom orderitemsgroup by order_numhaving sum(ordertotal) >= 50order by prod_id;
对分组后的数据分行:
SELECT order_num,SUM(quantity*item_price) AS ordertotalFROM orderitemsGROUP BY order_numHAVING SUM(quantity*item_price) >= 50ORDER BY ordertotalLIMIT 1,3;
5、SELECT子句顺序
| SELECT子句及其顺序 | |
|---|---|
| SELECT | 要返回的列或表达式 |
| FROM | 从中检索数据的表 |
| WHERE | 行级过滤 |
| GOURP BY | 分组 |
| HAVING | 组级过滤 |
| ORDER BY | 输出排序顺序 |
| LIMIT | 要检索的行数 |
十八、使用子查询
1、子查询
2、利用子查询进行过滤
SELECT order_numFROM orderitemsWHERE prod_id =’TNT2’;
SELECT cust_idFROM ordersWHERE order_num IN(20005,20007);
同上:
SELECT cust_idFROM ordersWHERE order_num IN(SELECT order_num FROM orderitems WHERE prod_id='TNT2');select * from empwhere deptno = ( select deptno from dept where dname='ACCOUNTING' );
十九、连接表
1、联接
1.1、关系表
外键:外键为某个表中的一列,它包含另一个表的主键值,定义了两个表间的关系。
可伸缩性:能够适应不断增加的工作量而不失败。
2、创建联接
2.1、WHERE子句的重要性
select e.empno,e.ename,d.dname from emp as e , dept as d where e.deptno = d.deptno;
笛卡尔积:由没有联接条件的表关系返回的结果为笛卡尔积。检索出的行的书目将是第一个表中的行数乘以第二个表中行数。
例如:
select * from emp as e,dept as d;
2.2、联接
联接也称为等值联接
select * from emp e join dept d on e.deptno = d.deptno;
同上:
select * from emp as e , dept as d where e.deptno = d.deptno;
2.3、联接多个表
SELECT prod_name,vend_name,prod_price,quantityFROM orderitems,products,vendorsWHERE products.vend_id = vendors.vend_idAND orderitems.prod_id = products.prod_idAND order_num = 20005;
SELECT cust_name,cust_contactFROM customers,orders,orderitemsWHERE customers.cust_id = orders.cust_idAND orderitems.order_num = orders.order_numAND prod_id = ‘TNT2’;
二十、创建高级联结
1、使用表别名
SELECT concat(RTrim(vend_name),’(’,RTrim(vend_country),’)’) AS vend_titleFROM vendorsORDER BY vend_name;
SELECT cust_name,cust_contactFROM customers AS c,orders AS o,orderitems AS oiWHERE c.cust_id = o.cust_idAND oi.order_num = o.order_numAND prod_id = ‘TNT2’;
2、使用不同类型的联结
2.1、自连接
子查询:
SELECT prod_id,prod_nameFROM productsWHERE vend_id =(SELECT vend_idFROM productsWHERE prod_id = ‘DTNTR’);
自连接:
SELECT p1.prod_id,p1.prod_nameFROM products AS p1.products AS p2WHERE p1.vend_id = p2.vend_idAND p2.prod_id = ‘DTNTR’;
2.2、左关联查询
SELECT customers.cust_id,orders.order_numFROM customers LEFT JOIN ordersON customers.cust_id = orders.cust_id;
注意:JOIN和RIGHT/LEFT一起使用,RIGHT会查找出所有JOIN右边的表的数据,相反LEFT会查找出左边的所有的行。另外一边是从属于另一边的。
3、使用带聚集函数的联结
SELECT customers.cust_name,customers.cust_id,COUNT(orders.order_num) AS num_ordFROM customers JOIN ordersON customers.cust_id = orders.cust_idGROUP BY customers.cust_id;
SELECT customers.cust_name,customers.cust_id,COUNT(orders.order_num) AS num_ordFROM customers LEFT JOIN ordersON customers.cust_id = orders.cust_idGROUP BY customers.cust_id;
二十一、组合查询
1、组合查询
两种情况需要使用组合查询:
在单个查询中从不同的表返回类似结构的数据;
对单个表执行多个查询,按单个查询返回数据。
2、创建组合查询
2.1、使用UNION
SELECT vend_id,prod_id,prod_priceFROM productsWHERE prod_price <= 5;
SELECT vend_id,prod_id,prod_priceFROM productsWHERE vend_id IN (1001,1002);
使用UNION:
SELECT vend_id,prod_id,prod_priceFROM productsWHERE prod_price <= 5UNIONSELECT vend_id,prod_id,prod_priceFROM productsWHERE vend_id IN(1001,1002);
同上:
SELECT vend_id,prod_id,prod_priceFROM productsWHERE prod_price <= 5 OR vend_id IN(1001,1002);
2.2、UNION规则
1、UNION必须由两条或两条以上的SELECT语句组成,语句之间用关键字UNION分隔(因此,如果组合4条SELECT语句,将要使用3个UNION关键字)
2、UNION中的每个查询必须包含相同的列、表达式或聚集函数(不过各个列不需要以相同的次序列出)。
3、列数据类型必须兼容:类型不必完全相同,但必须是DBMS可以隐含地转换的类型(例如:不同的数值类型或不同的日期类型)
2.3、包含或取消重复的行
UNION从查询结果集中自动去除了重复的行。想返回所有的行:UNION ALL
SELECT vend_id,prod_id,prod_priceFROM productsWHERE prod_price <= 5UNION ALLSELECT vend_id,prod_id,prod_priceFROM productsWHERE vend_id IN(1001,1002);
2.4、对组合查询结果排序
在UNION最后添加ORDER BY可以对整个SELECT进行排序
SELECT vend_id,prod_id,prod_priceFROM productsWHERE prod_price <= 5UNION ALLSELECT vend_id,prod_id,prod_priceFROM productsWHERE vend_id IN(1001,1002)ORDER BY vend_id,prod_price;

若有收获,就点个赞吧
0 人点赞
