思路很简单:就是给本地的图片上传到图床上,然后再复制过来,就没问题了。
代码:
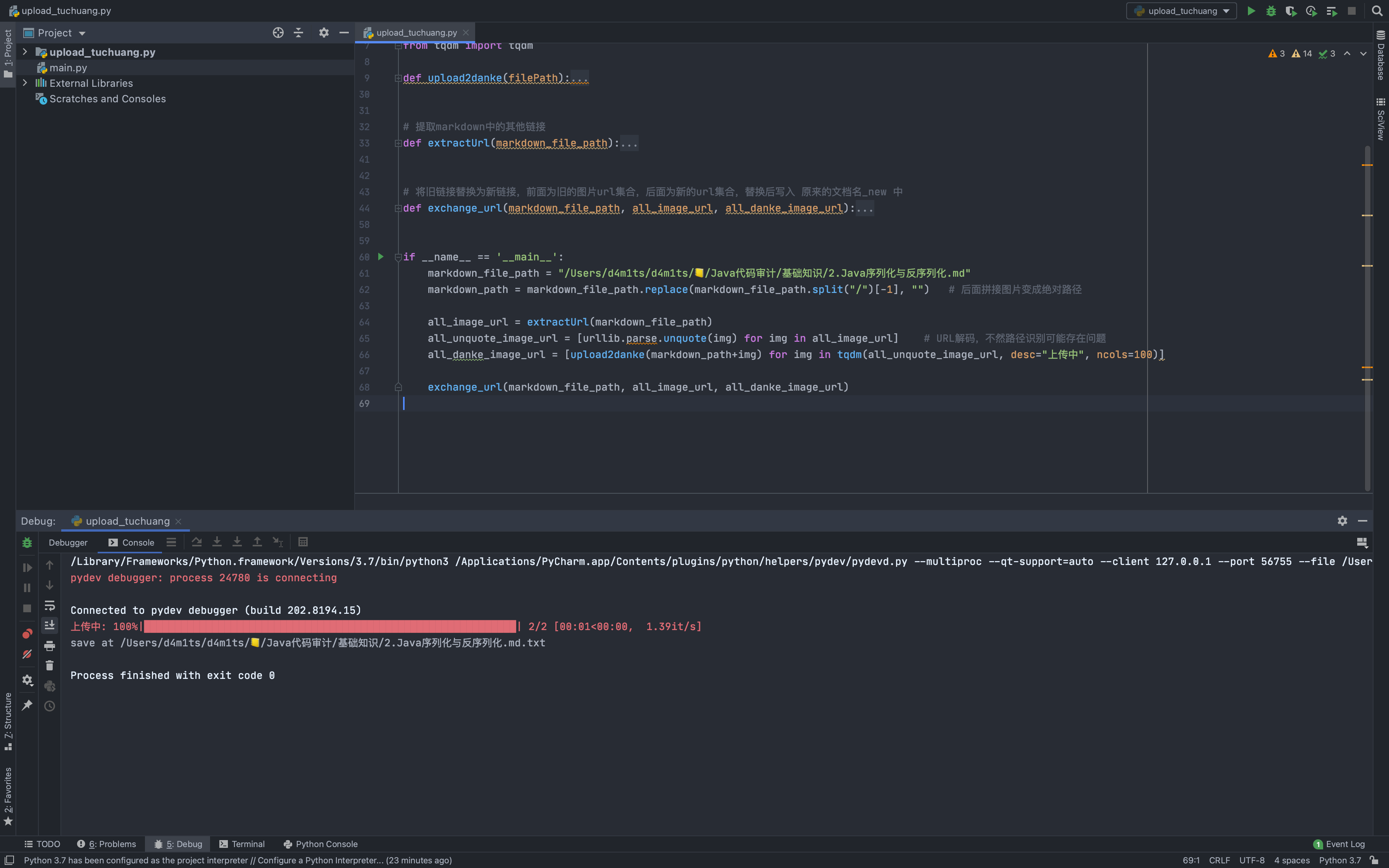
import requestsfrom requests_toolbelt.multipart.encoder import MultipartEncoderimport randomimport reimport urllibimport timefrom tqdm import tqdmdef upload2danke(filePath): # https://imgkr.com/filename = filePath.split("/")[-1]ck_time = str(time.time())[:10]url = "https://imgkr.com/api/files/upload"cookies = {"_ga": "GA1.2.1950159671.{}".format(ck_time), "_gid": "GA1.2.1236723023.{}".format(ck_time)}headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0","Accept": "*/*", "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2","X-Requested-With": "XMLHttpRequest", "Origin": "https://imgkr.com", "Connection": "close","Referer": "https://imgkr.com/"}data = MultipartEncoder(fields={"file": (filename, open(filePath, 'rb'), 'application/octet-stream')},boundary="-----------------------------{}".format(random.randint(1e13, 1e14 - 1)))headers['Content-Type'] = data.content_typereq = requests.post(url, headers=headers, cookies=cookies, data=data)res = req.json()if res['code'] == 200:return res['data']else:return None# 提取markdown中的其他链接def extractUrl(markdown_file_path):f = open(markdown_file_path, 'rb')markdown_content = f.read()f.close()url_regex = b"!\[.*?\]\((.*?)\)"all_image_url = re.findall(url_regex, markdown_content)all_image_url = [image.decode('utf-8', 'ignore') for image in all_image_url]return all_image_url# 将旧链接替换为新链接,前面为旧的图片url集合,后面为新的url集合,替换后写入 原来的文档名_new 中def exchange_url(markdown_file_path, all_image_url, all_danke_image_url):f = open(markdown_file_path, 'rb')markdown_content = f.read()f.close()# 替换for old_img, new_img in zip(all_image_url, all_danke_image_url):markdown_content = markdown_content.replace(old_img.encode(), new_img.encode())# 写入f = open(f"{markdown_file_path}.txt", 'wb')f.write(markdown_content)f.close()print(f"save at {markdown_file_path}.txt")if __name__ == '__main__':markdown_file_path = input("markdown file path: ")markdown_path = markdown_file_path.replace(markdown_file_path.split("/")[-1], "") # 后面拼接图片变成绝对路径all_image_url = extractUrl(markdown_file_path)all_unquote_image_url = [urllib.parse.unquote(img) for img in all_image_url] # URL解码,不然路径识别可能存在问题all_danke_image_url = [upload2danke(markdown_path+img) for img in tqdm(all_unquote_image_url, desc="上传中", ncols=100)]exchange_url(markdown_file_path, all_image_url, all_danke_image_url)
 s
s

若有收获,就点个赞吧
0 人点赞
