背景
1、并发量大,流量大的互联网架构,一般来说,数据库上层都有一个服务层,服务层记录了“业务库名”与“数据库实例”的映射关系,通过数据库连接池向数据库路由 SQL 语句以执行:
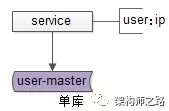
如上图:服务层配置用户库 user 对应的数据库实例物理位置为 ip(其实是一个内网域名)。
2、随着数据量的增大,数据要进行水平切分,分库后将数据分布到不同的数据库实例(甚至物理机器)上,以达到降低数据量,增强性能的扩容目的:
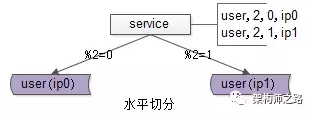
如上图:用户库 user 分布在两个实例上,ip0 和 ip1,服务层通过用户标识 uid 取模的方式进行寻库路由,模2余0的访问 ip0 上的 user 库,模2余1的访问 ip1 上的 user 库。
3、互联网架构需要保证数据库高可用,常见的一种方式,使用双主同步+keepalived+虚ip 的方式保证数据库的可用性:
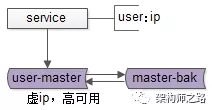
如上图:两个相互同步的主库使用相同的虚 ip。
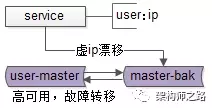
如上图:当主库挂掉的时候,虚ip 自动漂移到另一个主库,整个过程对调用方透明,通过这种方式保证数据库的高可用。
4、综合上文的2和3,线上实际的架构,既有水平切分,又有高可用保证,所以实际的数据库架构是这样的:
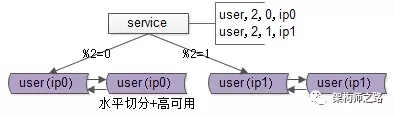
提问:如果数据量持续增大,分2个库性能扛不住了,该怎么办呢?
回答:继续水平拆分,拆成更多的库,降低单库数据量,增加库主库实例(机器)数量,提高性能。
最终问题抛出:分成x个库后,随着数据量的增加,要增加到y个库,数据库扩容的过程中,能否平滑,持续对外提供服务,保证服务的可用性,是本文要讨论的问题。
方案
1. 修改配置
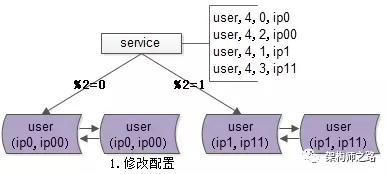
主要修改两处:
- 数据库实例所在的机器做双虚ip,原来%2=0的库是虚ip0,现在增加一个虚ip00,%2=1的另一个库同理
- 修改服务的配置(不管是在配置文件里,还是在配置中心),将2个库的数据库配置,改为4个库的数据库配置,修改的时候要注意旧库与新库的映射关系:
- %2=0的库,会变为%4=0与%4=2;
- %2=1的部分,会变为%4=1与%4=3;
这样修改是为了保证,拆分后依然能够路由到正确的数据。
2. reload 配置,实例扩容
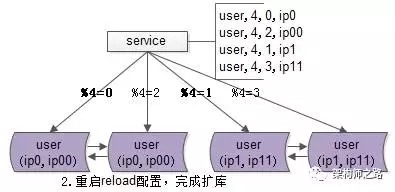
服务层 reload 配置,reload 可能是这么几种方式:
- 比较原始的,重启服务,读新的配置文件
- 高级一点的,配置中心给服务发信号,重读配置文件,重新初始化数据库连接池
不管哪种方式,reload 之后,数据库的实例扩容就完成了,原来是2个数据库实例提供服务,现在变为4个数据库实例提供服务,这个过程一般可以在秒级完成。
整个过程可以逐步重启,对服务的正确性和可用性完全没有影响:
- 即使%2寻库和%4寻库同时存在,也不影响数据的正确性,因为此时仍然是双主数据同步的
服务 reload 之前是不对外提供服务的,冗余的服务能够保证高可用
完成了实例的扩展,会发现每个数据库的数据量依然没有下降,所以第三个步骤还要做一些收尾工作。
3. 收尾工作,数据收缩
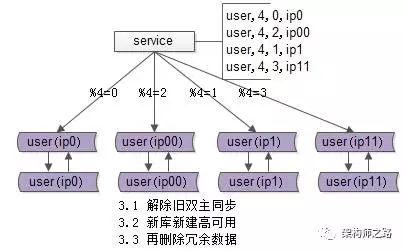
有这些一些收尾工作:
- 把双虚ip修改回单虚ip
- 解除旧的双主同步,让成对库的数据不再同步增加
- 增加新的双主同步,保证高可用
- 删除掉冗余数据,例如:ip0里%4=2的数据全部干掉,只为%4=0的数据提供服务啦
这样下来,每个库的数据量就降为原来的一半,数据收缩完成。
总结
该方案两个前提条件:
- 数据库当前的架构必须是双主同步;
- 只能实现双倍扩容;
作者:殷建卫 链接:https://www.yuque.com/yinjianwei/vyrvkf/yvcyue 来源:殷建卫 - 架构笔记 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

若有收获,就点个赞吧
0 人点赞
