转载:缓存穿透、并发使用的解法有哪些?(极课时间-每日一课视频内容)
常见做法
通常情况下,我们是如何在在业务中使用缓存的?当系统接收到一个获取数据的请求时,会存在如下两种情况。
- 如果缓存中有数据的话,直接从缓存中读取数据,然后返回给请求方。
- 如果缓存中没有数据的话,那就从数据库中读取数据,然后再更新到缓存中,然后返回给请求方。这样下次再获取这条数据的时候,我们就可以直接从缓存中读取,而不用来读取数据库了,这样可以在一定程度上减少数据库的 IO。
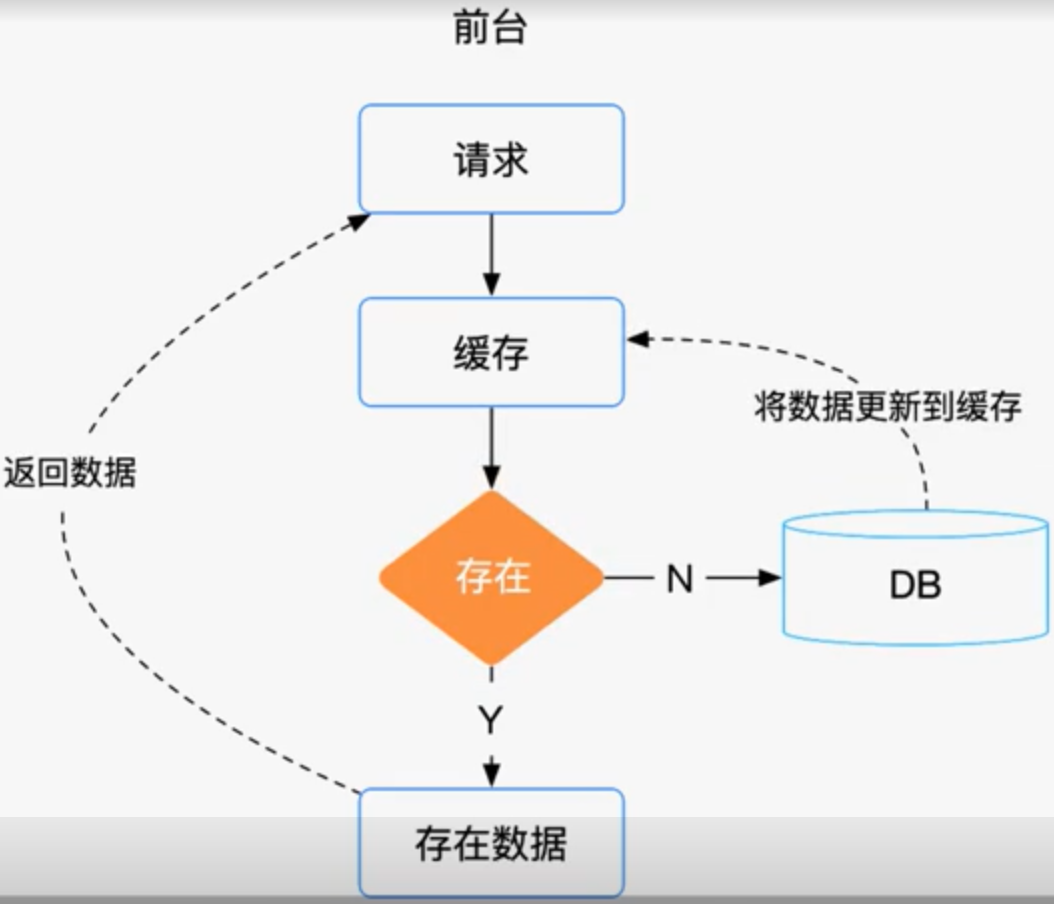
这种方案在并发量不高的时候,使用起来是没有问题的,但当并发较高的时候,是不建议使用缓存过期这个策略的,我们更希望缓存一直存在,通过后台系统来更新缓存系统中的数据,达到数据的一致性目的。
但是缓存不过期又存在问题,后台怎么维护缓存中的数据?缓存容量是有限的,如何释放一些不活跃的数据?
而且这种方案在并发很高的场景下,还会存在漏洞,这个漏洞就是缓存穿透的情况。
缓存穿透
缓存穿透指的是查询一个一定不存在的数据,由于缓存不命中时,需要从数据库中查询,而数据库也没有这条数据,这时候就无法更新缓存了,这将会导致这个不存在的数据每次请求时,都要到数据库去查询。
如果有人利用这个漏洞,进行恶意攻击的话,将会对数据库产生非常大的压力,严重的话会导致数据库宕机。
那么针对这种缓存穿透,我们有没有什么好的解决方案呢?
方案一
其实有一个比较巧妙的做法,我们可以为这个不存在的 key 预先设定一个值,比如 key 是 test,设定它的值为空字符串 null,在返回这个空字符串 null 的时候,我们应用就可以认为这是一个不存在的 key,就可以决定是否需要继续等待,还是继续访问,或者干脆放弃掉这次操作。
如果继续等待访问,过一个时间轮询点后, 再次请求这个 key,如果取到的值不再是 null,就可以认为这时候 key 是有值了,这就避免了穿透到数据库的情况出现,从而可以把大量的类似请求挡在了缓存之中。
方案二
解决缓存穿透的问题,还有一种办法,就是使用布隆过滤器,实际上它是一个很长的二进制向量,和一系列随机映射函数,布隆过滤器可以用于检索一个元素是否在一个集合中,优点是空间效率和查询时间都远远超过一般的算法,缺点就是存在一定的误识别率,并且删除困难。
Google 的 Guava 工具为我们提供了现成的类库,供我们使用。Redis 中也是提供了布隆过滤器,我们可以调 API 来使用。
通过判断前端传递过来的值是否在布隆过滤器中,来解决缓存穿透的问题,如果不存在,我们就可以直接返回错误响应,而不用透传到数据库中查询了。
缓存并发
缓存并发指的是同时有多个获取同一条数据的请求到来,从缓存中都没有查到数据,都去数据库中查询,然后所有的请求再反复更新缓存数据。
注意这里更新的是同一条数据,这样不仅会增加数据库的压力,还会因为反复更新的问题,占用 Redis 的请求资源,这个问题就叫缓存并发问题。
那么我们改如何解决缓存并发问题呢?
这里我们给出一个解决方案,注意这个解决方案不包括缓存穿透的场景,我们只是假定能从数据库中查询到数据。
一个查询数据的请求,从客户端发起,请求会先从缓存中读取数据,然后判断是否能从缓存中读取到,如果读取到了数据,就直接返回给客户端,流程结束。如果没有读取到,那么就在 Redis 中,使用 setNX 方法设置一个状态位,表示这是一种锁定状态,要是设置成功了,表示已经锁定成功,这时候请求从数据库中读取数据,然后更新缓存,最后再将数据返回给客户端,要是没有设置成功,表示这个状态位已经被其他请求锁定,这个请求等待一段时间,会从新发起数据查询,这样就能保证在同一时间,只能有一个请求来查询数据库更新缓存,其他请求只能等待重新发起查询,再次查询后发现缓存中已经有数据了,那么直接返回数据就可以。
缓存过期
缓存过期如果使用不当,不仅会造成缓存穿透,而且还会造成缓存的雪崩效应的出现。
我们在请求的过程中,会不断往缓存中写入数据,这样缓存中的数据就会越来越多,但真正被经常访问到的数据,可能只是其中的一小部分,所以我们没有必要将全部数据都放到缓存中,于是就会设置缓存过期时间,这样不经常访问的数据就会自动过期,而不会占用缓存空间。那我们该如何设置缓存过期时间呢?
一般情况下,会将缓存的过期时间设置为固定的时间,并发很高的时候,可能会出现在某一个时间点,用户同时设置了很多的缓存,并且过期时间都一样,当缓存到期时,缓存同时失效,请求全部转发到数据库,这时数据库的压力会瞬间增大,就会造成缓存雪崩现象。
对于缓存雪崩的现象,我想了两种解决方案,一个是将缓存失效时间分散开,比如我们可以在原有的失效时间基础上,增加一个随机值,这样每一个缓存的过期时间的重复率就会降低,也就很难引起集体失效的事件了。第二个解决方案就是缓存不过期,我们可以通过后台来更新缓存数据,来避免因为缓存失效造成缓存雪崩,也可以在一定程度上避免缓存并发问题。
缓存热点
我的项目并不是所有数据都需要存放到缓存中的,而只是其中一小部分数据会被用户频繁访问,如果把所有数据都缓存起来,过于浪费资源,而且缓存容量本身也受限,那么针对这个问题,我该怎么处理和解决呢?
接下来我们来聊聊缓存热点问题,我们以一个用户中心的案例入手,每个用户都会首先获取自己的用户信息,然后再进行其他相关的操作,有可能会有这样的场景,大量相同用户重复访问同一个项目,或者同一个用户频繁访问同一个模块,也就是说数据库存在的用户数据,可能某一些用户的请求量非常大,有些用户的请求量很小,因为用户的数据量非常大,且受限于缓存空间的大小,又不能把全部用户数据都存放在缓存中,只能存放热点用户数据,那我们该如何来判断哪些用户数据是热点数据呢?
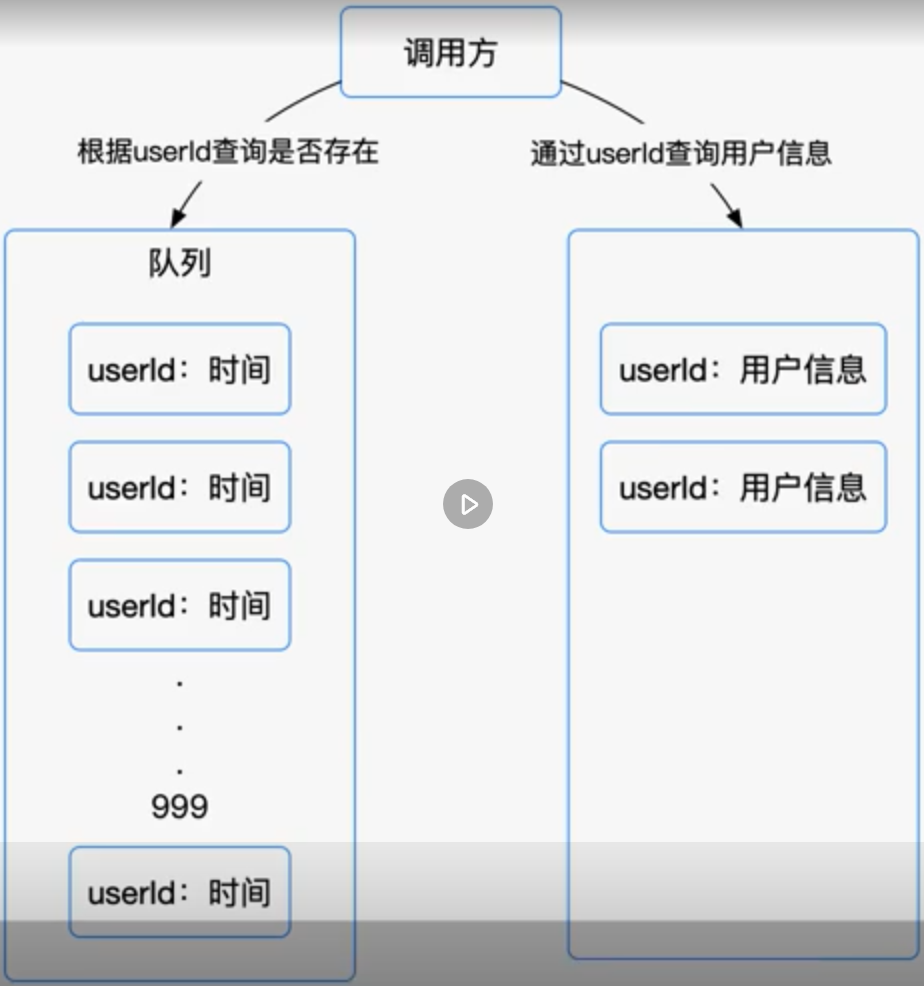
我们可以以一个访问用户中心数据的案例作为切入点,来说明热点缓存的用法,总体思路就是通过判断数据最新访问时间来做排名,过滤掉不常访问的数据,留下经常访问的数据。可以
可以先通过缓存系统做一个排序队列,比如存放1000个用户,系统会根据用户的访问时间,更新用户信息的时间,越是最近访问的用户排名越靠前,同时系统会定期过滤掉排名最后的200个用户,然后再从数据库中,随机读出200个用户,加入到队列,这样请求每次到达的时候,会先从队列中获取用户信息,如果命中就根据 userId 再从另一个缓存数据结构中读取用户信息返回,在 Redis 中,可以使用 zadd 方法和 zrange 方法,来完成排序队列和取200个用户的操作。
解耦
前面的内容中,我们都是将缓存操作与业务代码糅合在一起来分享的,这样做虽然容易实现,但是未来缓存操作的复用性就变得很差,基本上每做一个新业务,都要重新写一次相应的缓存操作,而且维护起来也不容易,我们想要修改项目中某一块业务的缓存操作,就需要先通读一遍这块业务的代码,了解了业务的逻辑后,才能够进行修改,那如何来解决这个问题呢?
有一种思路是建缓存操作与业务代码进行解耦,使用这个方案的前提是我们使用 MySQL 数据库存储数据,因为需要使用 binlog,同时也需要借助阿里的 Canal 数据同步组件。
我们举一个实际的场景,用户在应用后台添加配置数据,配置数据存储到了 MySQL 数据库中,同时数据库更新了 binlog 日志数据,接着再通过使用 Canal 组件,来获取最新的 binlog 日志数据,然后解析日志数据,并通过事先定义好的新的数据格式,重新生成新的数据,并发送到 MQ 中,对于 Canal 组件,我们又增加了限流功能,当日志数据量非常大的时候,我们会根据一定的频率,来做读取限制,以此来防止给 MQ 造成较大的请求和数据库压力的情况出现。
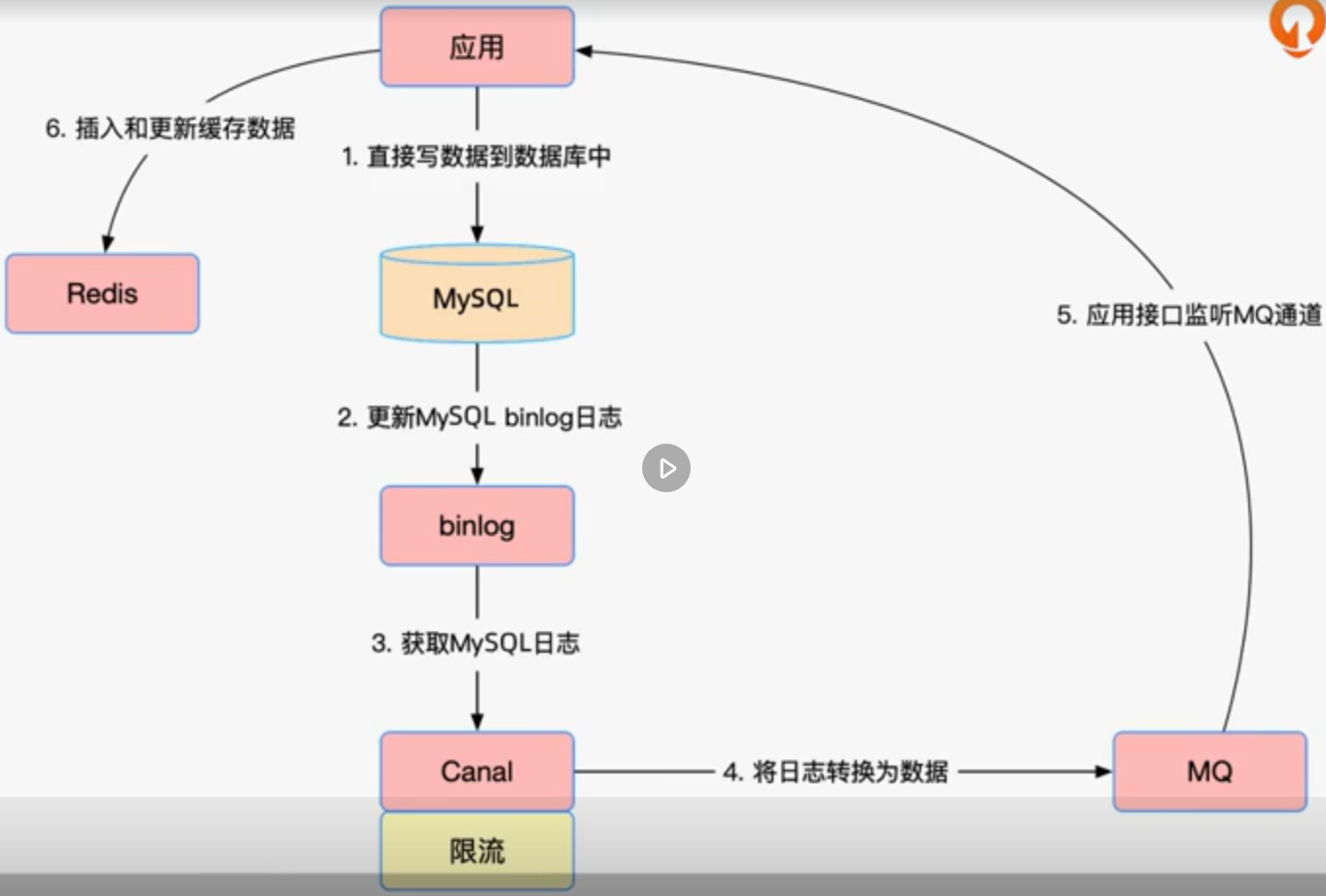
在应用方就需要监听 MQ 了,接收到数据后,判断这个数据的操作是添加、修改还是删除,然后根据不同的操作,来插入、修改和删除 Redis 缓存中相应的数据。
因为该方案存在一定的延时,所以只能应对一些一致性要求不高的数据,如果对 Redis 和 MySQL 数据库的一致性要求很高,则这种方案不能采用,防止因延时过大造成 Redis 中的数据在一定时间内不是最新的。
作者:殷建卫 链接:https://www.yuque.com/yinjianwei/vyrvkf/ip84zy 来源:殷建卫 - 架构笔记 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

若有收获,就点个赞吧
0 人点赞
