分布式架构的难点
- 三态(成功、失败、超时或未知)
- 分布式事务(多个存储节点下的数据一致性问题)
- 负载均衡(领域服务层的负载、服务发现)
- 一致性(CAP)
- 故障独立性(隔离)
领域驱动设计
分布式架构的基本理论 CAP、BASE
分布式一致性问题
对于不同的业务,一致性要求是不一样的。比如对于 12306 这样的票务网站,对一致性要求是很高的,用户A在买完从上海到南京的票之后,用户B是不能买到同样的票的。
还比如对于银行转账业务,对一致性要求是不高的,用户A转一笔钱到用户B的账户下,银行会提示钱会在24小时内到账,这块业务对数据的一致性要求就不高,只需要在24小时内保证数据一致性就可以了。
CAP
分布式系统的三个指标
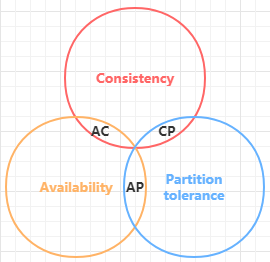
1998年,加州大学的计算机科学家 Eric Brewer 提出,分布式系统有三个指标。
- C(Consistency):一致性,意思是,写操作之后的读操作,必须返回该值。
- A(Availability):可用性,意思是只要收到用户的请求,服务器就必须给出回应。
- P(Partition tolerance):分区容错性,大多数分布式系统都分布在多个子网络。每个子网络就叫做一个区(partition)。分区容错的意思是,区间通信可能失败。比如,一台服务器放在中国,另一台服务器放在美国,这就是两个区,它们之间可能无法通信。
Eric Brewer 说,这三个指标不可能同时做到。这个结论就叫做 CAP 定理。
理解 CAP 理论
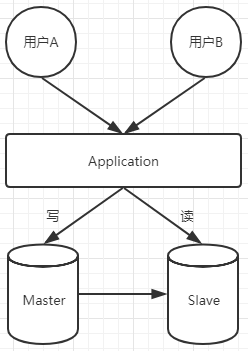
我们通过一个简单的例子来理解 CAP 理论。比如数据库的主从设计,用户A请求应用更新数据,Master 会把更新的数据同步到 Slave 库,假如在同步数据的过程中,用户B刚好来读数据,读到的是旧数据,这个时候就存在副本一致性的问题。
因为数据库节点存在两个(Master 和 Slave),Master 在同步数据到 Slave 的过程中,数据是远程传输的,肯定会存在网络延迟的情况,所以分区容错是一定存在的。
在分区容错一定存在的情况下,要保证高一致性,则 Master 在同步数据到 Slave 的时候,Slave 库是不能访问的,用户B的请求会阻塞在应用中,直到数据同步完成,用户B才能访问到更新后的数据,这个时候如果用户B的请求比较多,很多请求阻塞在应用中,会导致应用节点宕机。
在分区容错一定存在的情况下,一致性和可用性存在了冲突,所以只能满足两个点,CP or AP。
BASE
什么是 Base 理论
BASE 全称 Basically Available(基本可用),Soft State(软状态)和 Eventually Consistent(最终一致性)三个短语的缩写,来自 ebay 的架构师提出。
BASE 理论是对 CAP 中一致性和可用性权衡的结果,其来源于对大型互联网分布式实践的总结,是基于 CAP 定理逐步演化而来的。
其核心思想是:既是无法做到强一致性(Strong Consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual Consistency)。
Basically Available(基本可用)
基本可用是指分布式系统在出现故障的时候,允许损失部分可用性(例如响应时间、功能上的可用性),允许损失部分可用性。需要注意的是,基本可用绝不等价于系统不可用。
响应时间上的损失:正常情况下搜索引擎需要在0.5秒之内返回给用户相应的查询结果,但由于出现故障(比如系统部分机房发生断电或断网故障),查询结果的响应时间增加到了1~2秒。
功能上的损失:购物网站在购物高峰(如双十一)时,为了保护系统的稳定性,部分消费者可能会被引导到一个降级页面。
Soft State(软状态)
软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据会有多个副本,允许不同副本同步的延时就是软状态的体现。MySQL Replication 的异步复制也是一种体现。
Eventually Consistent(最终一致性)
最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
分布式架构下的高可用设计
设计指导
避免单点故障(负载均衡)
- 负载均衡技术(failover/选址/硬件负载/软件负载/去中心化的软件负载 gossip,Redis Cluster)
- 热备(Linux HA)
- 多机房(同城灾备、异地灾备)
应用的高可用性
- 故障监控(系统监控/链路监控/日志监控)
- 应用的容错设计、自我保护能力(服务降级/限流)
- 数据量(数据分片/读写分离)
可用性指标
所谓网站可用性(availability)也即网站正常运行时间的百分比,业界用 N 个9来量化可用性,最常说的就是类似“4个9(也就是99.99%)”的可用性。
| 描述 | 通俗叫法 | 可用性级别 | 年度停机时间 |
|---|---|---|---|
| 基本可用性 | 2个9 | 99% | 87.6小时 |
| 较高可用性 | 3个9 | 99.9% | 8.8小时 |
| 具有故障自动恢复能力的可用性 | 4个9 | 99.99% | 53分钟 |
| 极高可用性 | 5个9 | 99.999% | 5分钟 |
分布式架构下的可伸缩设计
- 垂直伸缩:提升硬件能力
- 水平伸缩:增加服务器
CDN(Content Delivery Network,即内容分发网络)
在没有 CDN 之前,用户访问静态资源的结构如下所示:
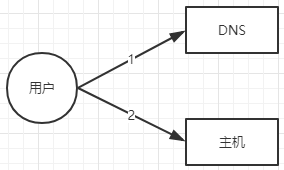
用户通过域名访问 DNS 服务器,获得主机 IP,再访问主机。这种传统的访问模式有什么缺点呢?
比如我们的主机在北京,而用户在海南,从用户到主机会经历多次路由节点跳跃,网络延迟比较大,所以我们需要引入 CDN 静态内容分发网络。
在引入 CDN 技术之后,用户访问静态资源(JS/CSS/HTML/Image)的结构如下所示:
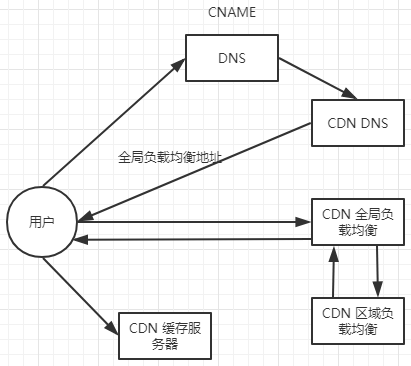
用户通过域名访问 DNS 服务器,DNS 通过配置的 CNAME 转发到 CDN DNS,返回全局负载均衡地址,通过这个地址访问到 CDN 全局负载均衡,在该负载均衡里面会根据用户的 IP 地址选在一个离用户最近的 CDN 区域负载均衡,返回给用户,然后用户根据返回的地址访问 CDN 缓存服务器。
作者:殷建卫 链接:https://www.yuque.com/yinjianwei/vyrvkf/kx05fs 来源:殷建卫 - 架构笔记 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

若有收获,就点个赞吧
0 人点赞
