比如用户库,根据 uid 水平切分为两个库
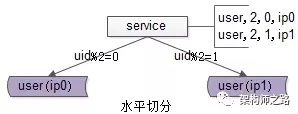
如何满足“跨越多个水平切分数据库,且分库依据与排序依据为不同属性,并需要进行分页”的查询需求,实现:
select * from T order by time offset X limit Y;
这类跨库分页 SQL,是后文将要讨论的技术问题。
全局视野法

如上图所述,服务层通过 uid 取模将数据分布到两个库上去之后,每个数据库都失去了全局视野,数据按照 time 局部排序之后,不管哪个分库的第3页数据,都不一定是全局排序的第3页数据。
那到底哪些数据才是全局排序的第3页数据呢?
需要分三种情况讨论。
- 极端情况,两个库的数据完全一样
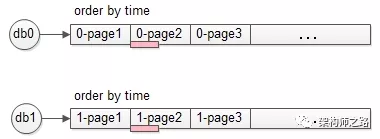
如果两个库的数据完全相同,只需要每个库 offset 一半,再取半页,就是最终想要的数据(如上图中粉色部分数据)。
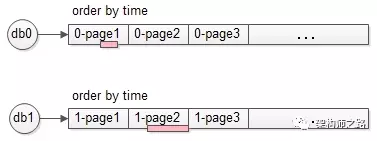
- 极端情况,结果数据来自一个库

也可能两个库的数据分布及其不均衡,例如 db0 的所有数据的 time 都大于 db1 的所有数据的 time,则可能出现:一个库的第3页数据,就是全局排序后的第3页数据(如上图中粉色部分数据)。
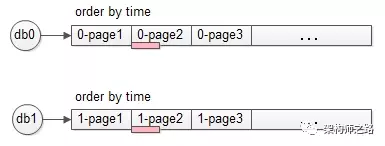
- 一般情况,每个库数据各包含一部分
正常情况下,全局排序的第3页数据,每个库都会包含一部分(如上图中粉色部分数据)。
由于不清楚到底是哪种情况,所以必须:
- 每个库都返回3页数据;
- 所得到的6页数据在服务层进行内存排序,得到数据全局视野;
- 再取第3页数据,便能够得到想要的全局分页数据。
再总结一下这个方案的步骤:
- 将SQL语句改写,即 order by time offset X limit Y; 改写成 order by time offset 0 limit X+Y;
- 服务层将改写后的 SQL 语句发往各个分库;
- 假设共分为 N 个库,服务层将得到 N*(X+Y) 条数据;
- 服务层对得到的 N*(X+Y) 条数据进行内存排序;
- 内存排序后再取偏移量 X 后的 Y 条记录,就是全局视野所需的一页数据;
全局视野法有什么优点?
通过服务层修改SQL语句,扩大数据召回量,能够得到全局视野,业务无损,精准返回所需数据。
全局视野法的缺点呢?
- 每个分库需要返回更多的数据,增大了网络传输量(耗网络);
- 除了数据库按照 time 进行排序,服务层还需要进行二次排序,增大了服务层的计算量(耗 CPU);
- 最致命的,这个算法随着页码的增大,性能会急剧下降,这是因为 SQL 改写后每个分库要返回 X+Y 行数据:返回第3页,offset 中的 X=200;假如要返回第100页,offset 中的 X=9900,即每个分库要返回100页数据,数据量和排序量都将大增,性能平方级下降。
“全局视野法”虽然性能较差,但其业务无损,数据精准,不失为一种方案,有没有性能更优的方案呢?
“任何脱离业务的架构设计都是耍流氓”,技术方案需要折衷,在技术难度较大的情况下,业务需求的折衷能够极大的简化技术方案。
禁止跳页查询法
**
在数据量很大,翻页数很多的时候,很多产品并不提供“直接跳到指定页面”的功能,而只提供“下一页”的功能,这一个小小的业务折衷,就能极大的降低技术方案的复杂度。

如上图,不能跳页,那么第一次只能够查第一页:
- 将查询 order by time offset 0 limit 100; 改写成 order by time where time>0 limit 100;
- 上述改写和 offset 0 limit 100 的效果相同,都是每个分库返回了一页数据(上图中粉色部分);

服务层得到2页数据,内存排序,取出前100条数据,作为最终的第一页数据,这个全局的第一页数据,一般来说每个分库都包含一部分数据(如上图粉色部分);
这个方案也需要服务器内存排序,岂不是和“全局视野法”一样么?第一页数据的拉取确实一样,但每一次“下一页”拉取的方案就不一样了。
点击“下一页”时,需要拉取第二页数据,在第一页数据的基础之上,能够找到第一页数据 time 的最大值:

这个上一页记录的 time_max,会作为第二页数据拉取的查询条件:
- 将查询 order by time offset 100 limit 100; 改写成 order by time where time>$time_max limit 100;

- 这下不是返回2页数据了(“全局视野法,会改写成offset 0 limit 200”),每个分库还是返回一页数据(如上图中粉色部分);

服务层得到2页数据,内存排序,取出前100条数据,作为最终的第2页数据,这个全局的第2页数据,一般来说也是每个分库都包含一部分数据(如上图粉色部分);
如此往复,查询全局视野第100页数据时,不是将查询条件改写为 offset 0 limit 9900+100;(返回100页数据),而是改写为 time>$time_max99 limit 100;(仍返回一页数据),以保证数据的传输量和排序的数据量不会随着不断翻页而导致性能下降。
允许数据精度损失法
“全局视野法”能够返回业务无损的精确数据,在查询页数较大,例如第100页时,会有性能问题,此时业务上是否能够接受,返回的100页不是精准的数据,而允许有一些数据偏差呢?
先来了解一下,数据库分库-数据均衡原理。
什么是,数据库分库-数据均衡原理?
使用 patition key 进行分库,在数据量较大,数据分布足够随机的情况下,各分库所有非 patition key 属性,在各个分库上,数据分布的统计概率情况是一致的。
例如,在 uid 随机的情况下,使用 uid 取模分两库,db0 和 db1:
- 性别属性,如果 db0 库上的男性用户占比 70%,则 db1 上男性用户占比也应为 70%;
- 年龄属性,如果 db0 库上 18-28 岁少女用户比例占比 15%,则 db1 上少女用户比例也应为 15%;
- 时间属性,如果 db0 库上每天10:00之前登录的用户占比为 20%,则 db1 上应该是相同的统计规律;
…
利用这一原理,要查询全局100页数据,只要将 offset 9900 limit 100; 改写为 offset 4950 limit 50;
即每个分库偏移一半(4950),获取半页数据(50条),得到的数据集的并集,基本能够认为,是全局数据的 offset 9900 limit 100 的数据,当然,这一页数据并不是精准的。
根据实际业务经验,用户都要查询第100页网页、帖子、邮件的数据了,这一页数据的精准性损失,业务上往往是可以接受的,但此时技术方案的复杂度大大降低了,既不需要返回更多的数据,也不需要进行服务内存排序了。如果业务能够接受,这种方案的性能最好,强烈推荐。
二次查询法
有没有一种技术方案,即能够满足业务的精确需要,无需业务折衷,又高性能的方法呢?这就是接下来要介绍的终极武器,“二次查询法”。
注意:二次查询仍然符合“数据库分库-数据均衡定理”,所以它也只能满足相对精确需求。
为了方便举例,假设一页只有5条数据,查询第200页的 SQL 语句为:
select * from T order by time offset 1000 limit 5;
步骤一:查询改写
select from T order by time offset 1000 limit 5;
改写为
select from T order by time offset 500 limit 5;
并投递给所有的分库,注意,这个 offset 的500,来自于全局 offset 的总偏移量1000,除以水平切分数据库个数2。
如果是3个分库,则可以改写为
select * from T order by time offset 333 limit 5;
假设这三个分库返回的数据 (time, uid) 如下:
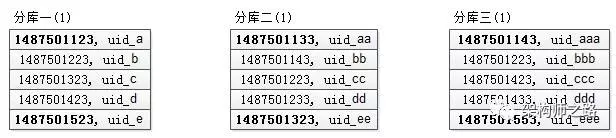
可以看到,每个分库都是返回的按照 time 排序的一页数据。
步骤二:找到所返回3页全部数据的最小值
- 第一个库,5条数据的time最小值是1487501123;
- 第二个库,5条数据的time最小值是1487501133;
- 第三个库,5条数据的time最小值是1487501143;
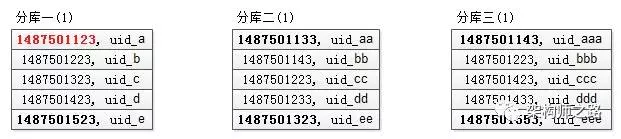
故,三页数据中,time 最小值来自第一个库,time_min=1487501123,这个过程只需要比较各个分库第一条数据,时间复杂度很低。
步骤三:查询二次改写
第一次改写的SQL语句是:
select * from T order by time offset 333 limit 5;
第二次要改写成一个 between 语句:
- between 的起点是 time_min
- between 的终点是原来每个分库各自返回数据的最大值
第一个分库,第一次返回数据的最大值是 1487501523 所以查询改写为:
select from T order by time where time between time_min and 1487501523;
*第二个分库,第一次返回数据的最大值是 1487501323,所以查询改写为
select from T order by time where time between time_min and 1487501323;
*第三个分库,第一次返回数据的最大值是 1487501553,所以查询改写为
select * from T order by time where time between time_min and 1487501553;
相对第一次查询,第二次查询条件放宽了,故第二次查询会返回比第一次查询结果集更多的数据,假设这三个分库返回的数据 (time, uid) 如下: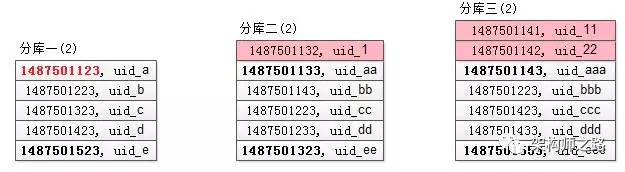
可以看到:
分库一的结果集,由于 time_min 来自原来的分库一,所以分库一的返回结果集和第一次查询相同(所以其实这次访问是可以省略的);
分库二的结果集,比第一次多返回了1条数据,头部的1条记录(time 最小的记录)是新的(上图中粉色记录);
分库三的结果集,比第一次多返回了2条数据,头部的2条记录(time 最小的2条记录)是新的(上图中粉色记录);
步骤四:在每个结果集中虚拟一个 time_min 记录,找到 time_min 在全局的 offset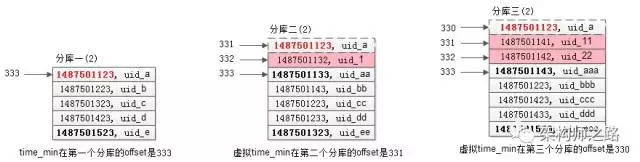
在第一个库中,time_min 在第一个库的 offset 是333;
在第二个库中,(1487501133, uid_aa )的 offset 是333(根据第一次查询条件得出的),故虚拟 time_min 在第二个库的offset是331;
在第三个库中,(1487501143, uid_aaa) 的 offset 是333(根据第一次查询条件得出的),故虚拟 time_min 在第三个库的 offset 是330;
综上,time_min 在全局的 offset 是 333+331+330=994。
步骤五:既然得到了 time_min 在全局的offset,就相当于有了全局视野,根据第二次的结果集,就能够得到全局offset 1000 limit 5 的记录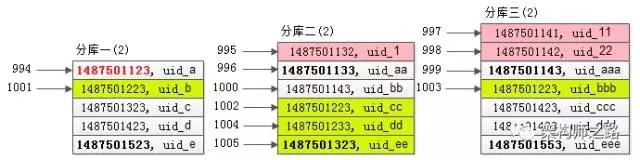
第二次查询在各个分库返回的结果集是有序的,又知道了 time_min 在全局的 offset 是994,一路排下来,容易知道全局 offset 1000 limit 5 的一页记录(上图中黄色记录)。
这种方法的优点是:可以精确的返回业务所需数据,每次返回的数据量都非常小,不会随着翻页增加数据的返回量。
总结
今天介绍了解决“跨N库分页”这一难题的四种方法:
方法一:全局视野法
- SQL 改写,将 order by time offset X limit Y; 改写成 order by time offset 0 limit X+Y;
- 服务层对得到的 N*(X+Y) 条数据进行内存排序,内存排序后再取偏移量 X 后的 Y 条记录;
这种方法随着翻页的进行,性能越来越低。
方法二:禁止跳页查询法
- 用正常的方法取得第一页数据,并得到第一页记录的 time_max;
- 每次翻页,将 order by time offset X limit Y; 改写成 order by time where time>$time_max limit Y;
以保证每次只返回一页数据,性能为常量。
方法三:允许模糊数据法
- SQL 查询改写,将 order by time offset X limit Y; 改写成 order by time offset X/N limit Y/N;
性能很高,但拼接的结果集不精准。
方法四:二次查询法
- SQL 改写,将 order by time offset X limit Y; 改写成 order by time offset X/N limit Y;
- 多页返回,找到最小值 time_min;
- between 二次查询 order by time between $time_min and $time_i_max;
- 设置虚拟 time_min,找到 time_min 在各个分库的 offset,从而得到 time_min 在全局的 offset;
- 得到了 time_min 在全局的 offset,自然得到了全局的 offset X limit Y;
作者:殷建卫 链接:https://www.yuque.com/yinjianwei/vyrvkf/hc6gbh 来源:殷建卫 - 架构笔记 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

若有收获,就点个赞吧
0 人点赞
