前面讲到过索引组织表和堆表的区别,接下来在分析 InnoDB 二级索引的时候还会在讲到。
二级索引也可以称为非聚集索引,叶子节点存储的内容不再是一整条记录,而是“行标识符”(row identifier),“行标识符”可以有多种实现方式,索引组织表(IOT 表)和堆表的“行标识符”的实现方式是不一样的。
因为 InnoDB 使用的是 IOT 表,所以会详细分析 IOT 表的二级索引,以及它带来的问题和 InnoDB 的解决方案。
文章主要内容分为如下几个部分:
- 介绍 IOT 表的二级索引,以及分析它的“回表”问题。
- 分析 MRR 特性是如何解决 IOT 表二级索引带来的“回表”问题。
- 介绍堆表的二级索引,以及对比 IOT 表和堆表的二级索引的差异。
IOT 表的二级索引
数据结构
IOT 表的二级索引叶子节点存储的是索引和主键信息。比如创建一张 Users 表:
CREATE TABLE users(id INT NOT NULL,name VARCHAR(20) NOT NULL,age INT NOT NULL,PRIMARY KEY(id));# 新建一个以 age 字段的二级索引ALTER TABLE users ADD INDEX index_age(age);
InnoDB 会分别创建主键 id 的聚簇索引和 age 的二级索引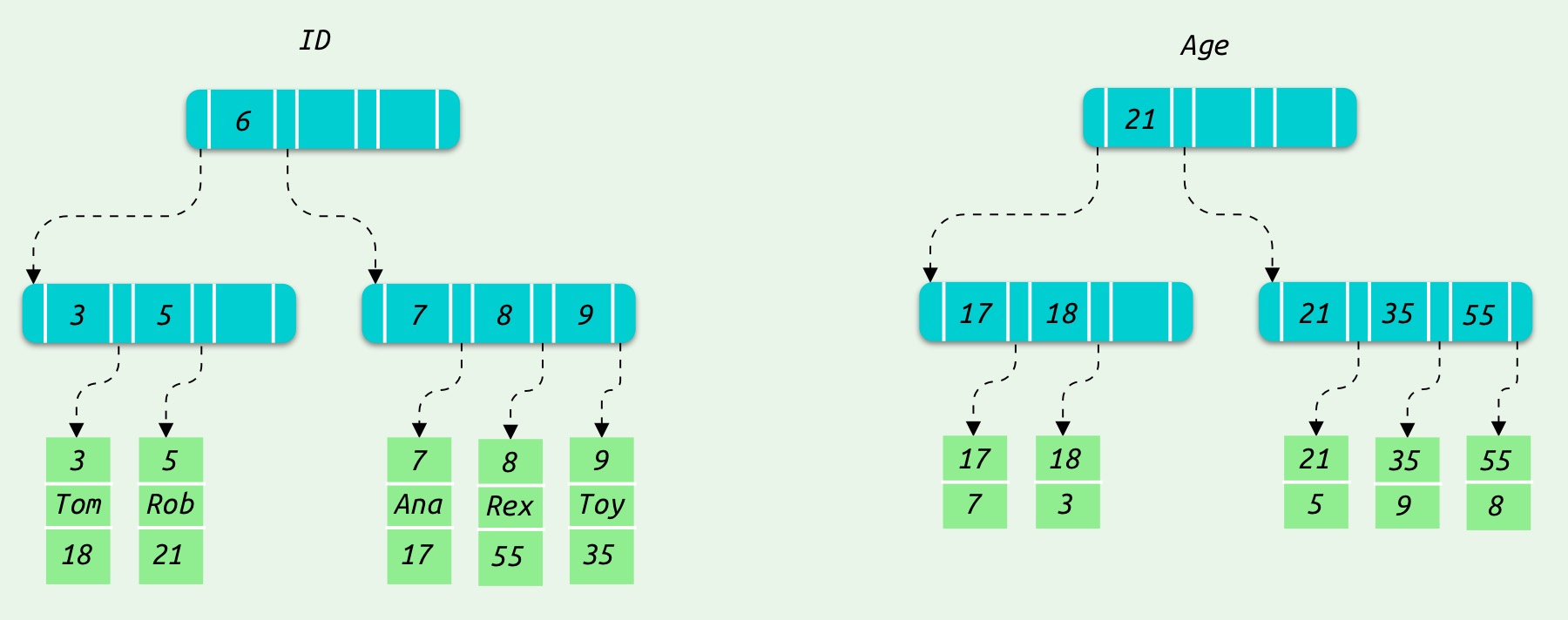
在 InnoDB 中主键索引的叶子节点存的是整行数据,而二级索引叶子节点内容是索引和主键信息。
检索过程
在查询条件命中二级索引的时候,如果二级索引已经能够满足查询需求了,则直接返回查询结果,即为覆盖索引,否则需要根据二级索引得到的主键值,再到聚集索引中查询,才能得到最终的结果。
例如执行 SELECT age FROM users WHERE age = 35; 不需要回表,因为二级索引已经能够满足查询需求了。
例如执行 SELECT * FROM users WHERE age = 35; 则需要进行回表: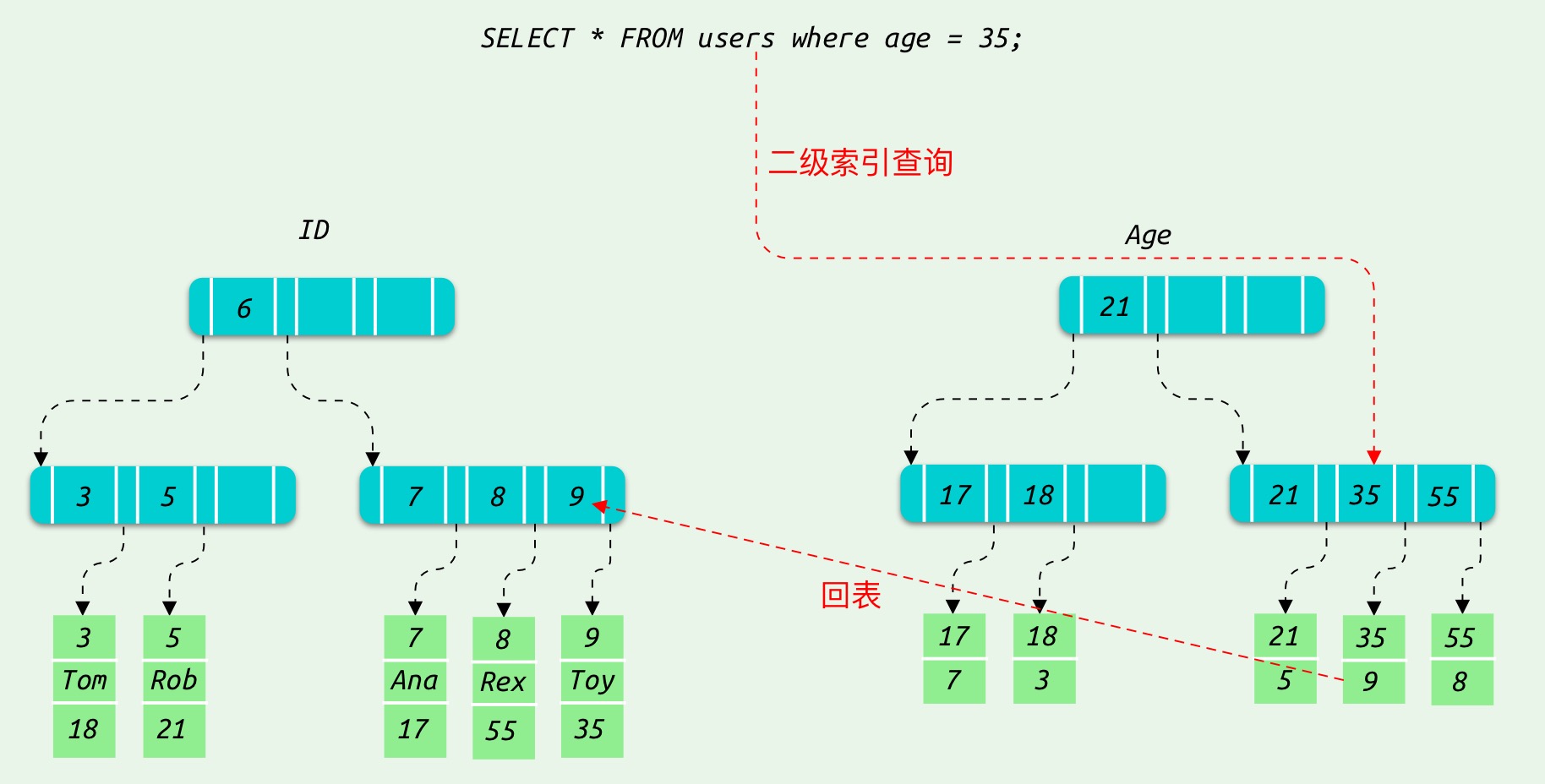
回表的代价
上面的二级索引的查询结果只有一条数据,不能直观的反映出回表的代价。
假如我要查询年龄大于 35 的所有用户数据:SELECT * FROM users WHERE age > 35; 假设二级索引返回了 1w 条数据,二级索引和聚集索引的索引高度都是 3,这样需要查询的 IO 数为 (3+N) + 3W。
- 3 为第一次找到 age > 35 所在的页(二级索引)的 IO 次数。
- N 为从第一次找到的页往后读页的 IO 次数(注意:二级索引也是连续的,不需要从根再重新查找)。
- 所以 3 + N 就是在二级索引 index_age 中读取 IO 的次数。
- 3W 是在聚集索引中回表的次数,在二级索引 index_age 中找到的每一条数据都需要从聚集索引的根重新查找。
我们发现二级索引回表的代价很大,优化器可能会选择直接进行扫表,而不会进行如此多的回表操作。
避免回表
通过上面的描述我们知道 IOT 表的回表代价很大,那么如何有效的避免回表呢?
在 InnoDB 中我们一般采用两种方式:复合索引和拆表。
这里只是提供一个思路,至于在实际使用中到底采用哪种方式更好,或者没必要避免回表,都是需要你自己根据具体业务分析的,一切从实际业务出发,脱离业务谈技术都是耍流氓。
第一种:复合索引
创建一张用户表 userinfo:
create table userinfo (userid int not null auto_increment,username varchar(30),registdate datetime,email varchar(50),primary key(userid),unique key idx_username(username),key idx_registdate(registdate));
执行 SQL select email from userinfo where username='Tom';,因为二级索引 idx_username 不包含 email 字段,需要回表,到主键索引中再次检索数据,最终才能返回 email 数据。
所以一般遇到这种请求,为了避免回表,我们会建一个复合索引 idx_username_email(username, email),这样上面的查询语句就不需要回表了,可以直接通过二级索引获得 email 数据。
但是这个又带来了一个问题,复合索引中 username 和 email 都需要排序,且 email 字段有点长,这样整个索引的键值就比较长了。
顺便提一嘴,SQL Server 提供了一个特性 Indexes With Included Columns(含列索引),它的意思是以 username 作为键值,email 只是带到索引中,不作为键值,方便查找。这个特性比较有意思,它既避免了回表问题,又避免了二级索引过长的问题。不过截止到目前,MySQL 8.0 也没有提供该特性,如果有小伙伴发现 MySQL 也支持该特性了,麻烦告诉我,我可以整理一下。
第二种:拆表
不过 MySQL 可以通过拆表的方式来实现既避免回表,又避免索引过长,但拆表也会带来其他的问题,比如数据一致性,需要使用事务等等。
可以将用户表 userinfo 拆成如下两张表:
# 两个表的数据一致性可以通过事物进行保证create table userinfo (userid int not null auto_increment,username varchar(30),registdate datetime,email varchar(50),primary key(userid),key idx_registdate(registdate));create table idx_username_include_email (userid int not null,username varchar(30),email varchar(50),primary key(username, userid),unique key(username));
通过拆表的方式,如果需要通过 useranme 得到 email,可以直接查 idx_username_include_email 表。
对于含有多个索引的 IOT 表,可以将索引拆成不同的表,进而提高查询速度,但是我还是要强调一下,在实际使用中,还是要慎重,因为有时候数据一致性问题可能会更加麻烦,比如就这个例子而言,使用复合索引的代价也不会太大。
Multi-Range Read Optimization(MRR)
除了我们自己在设计表的时候,使用一些方式避免 IOT 表的回表,InnoDB 也提供了 MRR 特性来降低回表的开销,接下来我们分析一下 InnoDB 的 MRR 特性。
MRR 的全称是 Multi-Range Read Optimization,是优化器将随机 IO 转化为顺序 IO 以降低查询过程中 IO 开销的一种手段,咱们对比一下 mrr=on & mrr=off 时的执行计划:
# 其中 MRR 默认是打开的 mrr=on,不建议关闭mysql> show variables like 'optimizer_switch'\G*************************** 1. row ***************************Variable_name: optimizer_switchValue: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on1 row in set (0.00 sec)# 虽然 mrr=on 打开了,但是没有使用 MRRmysql> explain select * from users where age > 1;+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+| 1 | SIMPLE | users | NULL | range | index_age | index_age | 4 | NULL | 2 | 100.00 | Using index condition |+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+1 row in set, 1 warning (0.00 sec)# 设置 mrr_cost_based=off,不让 MySQL 对 MRR 进行成本计算,强制使用 MRR# SET [GLOBAL|SESSION] optimizer_switch='command[,command]...'; optimizer_switch 属性可以设置全局也可以设置会话级别的# 设置的全局级别,需要重新打开会话才能生效mysql> set optimizer_switch='mrr_cost_based=off';Query OK, 0 rows affected (0.00 sec)# 再次执行上面的语句,可以看到 extra 的输出中多了 Using MRR 信息,即使用 MRR 进行了优化,减少 IO 方面的开销mysql> explain select * from users where age > 1;+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+----------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+----------------------------------+| 1 | SIMPLE | users | NULL | range | index_age | index_age | 4 | NULL | 2 | 100.00 | Using index condition; Using MRR |+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+----------------------------------+1 row in set, 1 warning (0.00 sec)# 除了通过关闭成本计算的方式,强制使用 MRR,还可以使用优化器提示的方式来让当前执行的 SQL 使用 MRR,只对当前 SQL 有效mysql> EXPLAIN SELECT /*+ MRR(users)*/ * FROM users WHERE age > 1;+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+----------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+----------------------------------+| 1 | SIMPLE | users | NULL | range | index_age | index_age | 4 | NULL | 2 | 100.00 | Using index condition; Using MRR |+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+----------------------------------+1 row in set, 1 warning (0.00 sec)
在 MySQL 5.7 版本中,基于成本的算法过于保守,导致大部分情况下优化器都不会选择 MRR 特性。但是我们仍然不能关闭 MySQL 的 mrr_cost_based 属性,强制开启 MRR,在某些 SQL 语句下,性能可能会变差,因为 MRR 需要排序 ,假如排序的时间超过直接执行的时间,那性能就会降低。相信随着 MySQL 优化器的不断完善,这些问题都会被解决。
MRR 原理
在不使用 MRR 时,优化器需要根据二级索引返回的记录来进行“回表”,这个过程一般会有较多的随机 IO, 使用 MRR 时,SQL 语句的执行过程是这样的:
- 优化器将二级索引查询到的记录放到一块缓冲区中。
- 如果二级索引扫描到文件的末尾或者缓冲区已满,则使用快速排序对缓冲区中的内容按照主键进行排序(随机转顺序)。
- 用户线程调用 MRR 接口取聚集索引,然后根据聚集索引取行数据。
- 当根据缓冲区中的聚集索引被取完,则继续执行上面的步骤,直至扫描结束。
通过上述过程,优化器将二级索引随机的 IO 进行排序,转化为主键的有序排列,从而实现了随机 IO 到顺序 IO 的转化,提升性能。
在 IO Bound 的 SQL 场景下,使用 MRR 比不使用 MRR,系统性能提高将近 10 倍,磁盘性能越低效果越明显。
如果数据都在内存中了,MRR 的帮助就不大了, 因为数据已经在内存中了,不存在随机读的概念了,随机读主要针对物理访问。
SSD 仍然需要开启该特性,多线程下的随机读确实很快,但是我们这里的操作是一条 SQL 语句,是单线程的,所以顺序的访问还是比随机访问要更快。
MRR 涉及的参数
# 优化器开关,包含 MRR 开关mysql> show variables like 'optimizer_switch'\G*************************** 1. row ***************************Variable_name: optimizer_switchValue: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on1 row in set (0.00 sec)# 打开 MRRset optimizer_switch='mrr=on';# 关闭 MRRset optimizer_switch='mrr=off';# 打开 MRR 成本计算set optimizer_switch='mrr_cost_based=on';# 关闭 MRR 成本计算set optimizer_switch='mrr_cost_based=off';# MRR 缓存大小,默认是 32M,注意是线程级别的,不建议设置的过大# 这块内存就是用来放需要回表的主键数据的mysql> show variables like "%read_rnd%";+----------------------+----------+| Variable_name | Value |+----------------------+----------+| read_rnd_buffer_size | 33554432 | -- 32M+----------------------+----------+1 row in set (0.00 sec)
堆表的二级索引
在堆表中是没有聚集索引的,所有的索引都是二级索引,且索引的叶子节点存放的是索引和指向堆中记录的指针地址。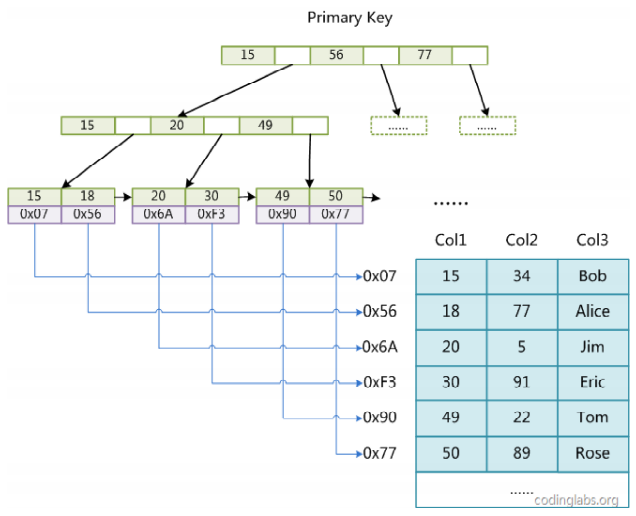
堆表和 IOT 表二级索引的对比
堆表中的二级索引查找不需要回表,且查找速度和主键索引一致,因为两者的叶子节点存放的都是指向数据的指针,而 IOT 表的二级索引查找需要回表。
堆表中某条记录(row data)发生更新且无法原地更新时,该记录(row data)的物理位置将发生改变,此时,所有索引中对该记录的指针都需要更新,代价较大,而 IOT 表中的记录更新,且主键没有更新时,二级索引都无需更新,通常来说主键是不更新的。
- 实际数据库设计中,当堆表的数据无法原地更新时,且在一个页内有剩余空间时,原来数据的空间位置不会释放,而是使用指针指向新的数据空间位置,此时该记录对应的所有索引就无需更改了。
- 如果页内没有剩余空间,所有的索引还是要更新一遍。
IOT 表页内的记录是有序的,且页与页之间也是逻辑有序的,所以做 range 查询很快。
总结
InnoDB 使用 IOT 表的形式,二级索引带来的回表代价很大,了解通过何种方式来避免回表。
- 了解 InnoDB 的 MRR 特性,且 MRR 是必须开启的(默认是开启的)。
- IOT 表和堆表二级索引的叶子节点存储的内容是不一样的。
参考
MySQL · 引擎特性 · 二级索引分析
MySQL · 特性分析 · 优化器 MRR & BKA
作者:殷建卫 链接:https://www.yuque.com/yinjianwei/vyrvkf/rdl8if 来源:殷建卫 - 架构笔记 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

若有收获,就点个赞吧
0 人点赞
