MySQL B+Tree 索引的体现形式
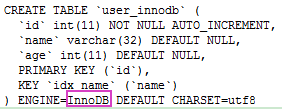
索引的实现是由存储引擎来实现的,那么在 MySQL 中比较主流的两大引擎是:Myisam 和 InnoDB,存储引擎是建立在表上面的,在创建表的时候可以指定所需要的存储引擎。下面的建表语句中就指定了存储引擎为 InnoDB,不指定就使用默认的 InnoDB。
获取硬盘中数据存储的地址:
SHOW VARIABLES LIKE 'datadir';

进入该地址,找到刚才创建的库 engine,该库创建了两张表,分别使用了两种存储引擎,Myisam 存储引擎:user_myisam,InnoDB 存储引擎:user_innodb,可以看到如下所示的文件内容: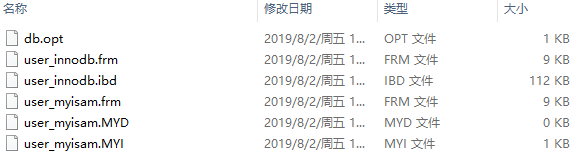
MyISAM 引擎
MyISAM 的数据和索引是分别存储的,在创建好表结构并且指定存储引擎为 MyISAM 之后,会在数据目录生成3个文件,分别是 table_name.frm(表结构文件),table_name.MYD(数据保存文件),table_name.MYI(索引保存文件)。
ID 列索引

例如上图的 teacher 表,两个文件分别保存了数据及索引,由于 B+Tree 中只有叶子节点保存数据区,在 MyISAM 中,数据区中保存的是数据的引用地址,比如说 id 为101的数据信息所保存到物理磁盘地址为 0x123456,当扫描到这个指针位置,就可以通过这个磁盘指针将数据加载出来。
ID 列索引、name 列索引
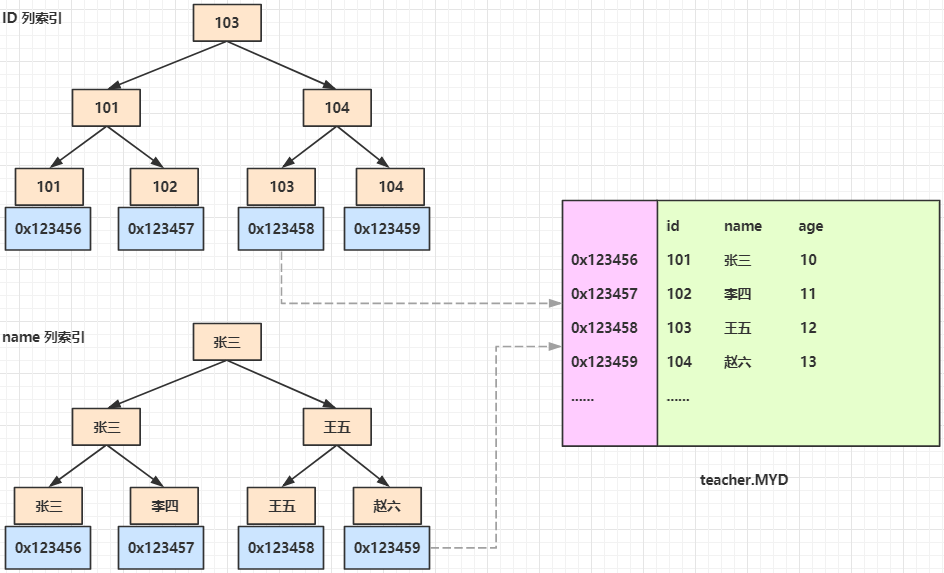
在 MyISAM 中,name 索引和 ID 索引是一样的,叶子节点也是保存它指向的磁盘位置指针,他们是平级的。
InnoDB 引擎
InnoDB 的数据和索引是存储在一起的,在创建好表结构并且指定存储引擎为 InnoDB 之后,会在数据目录生成2个文件,分别是 table_name.frm(表结构文件),table_name.idb(数据与索引保存文件)。
InnoDB B+Tree 的体现是以主键为索引来组织数据的存储,当我们没有显示的建立主键索引的时候,存储引擎会隐式的生成一个6位的 int 型的索引来作为它的主键索引以组织数据的存储。
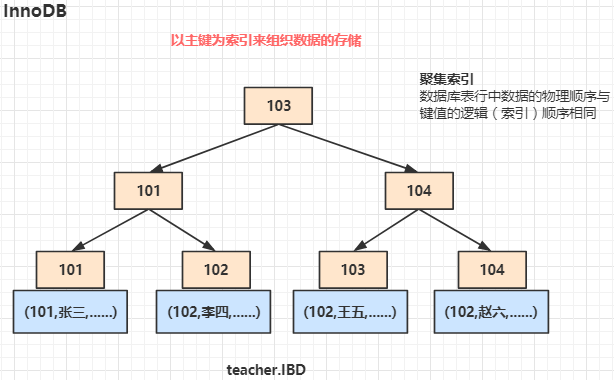
数据库表行中数据的物理顺序与键值的逻辑(索引)顺序相同,InnoDB 就是以聚集索引来组织数据的存储的,在叶子节点上,保存了数据的所有信息。如果这个时候建立了 name 字段的索引,它是如何组织数据的,如下图所示:
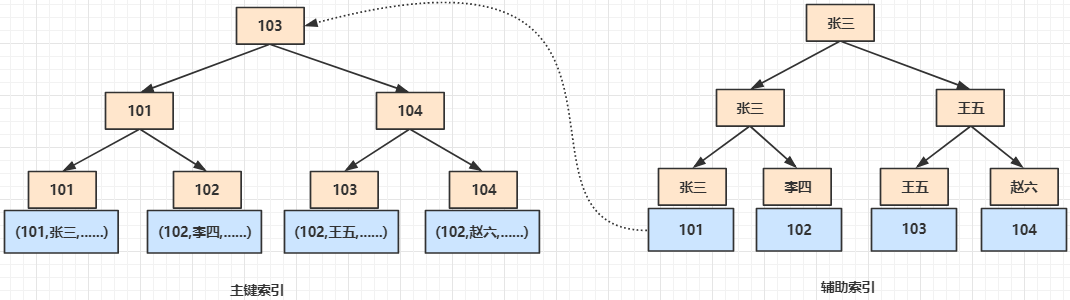
会产生一个辅助索引,即 name 字段的索引,而此刻叶子节点上所保存的数据为聚集索引(ID索引)的关键字的值,基于辅助索引找到 ID 索引的值,再通过 ID 索引区获取最终的数据。
这个做法的好处是在于产生数据迁移的时候只要 ID 没发生变法,那么辅助索引不需要重新生成,不这么做的话,如果存储的是磁盘地址的话,在数据迁移后所有辅助索引都需要重新生成。
索引知识点
列的离散性 count(distinct col) : count(col)
比如下面的数据,找出离散性最好的列?可以发现 name 的离散性是最好的。
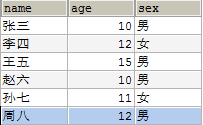
列的离散性的计算公式是:count(distinct col) : count(col),比例越大,离散性就越好
结论:列的离散性越好,列的选择性就越好。
如何理解列的选择性呢?比如对性别字段做索引,假设男为1,女为0,就会生成如下索引树:
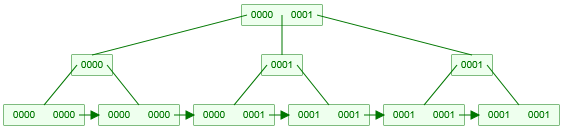
这个时候要搜索女的数据,从根节点出发,发现可以选择的线路太多了,优化器觉得既然要搜索这么多数据,还不如全表扫描,不利于 MySQL 数据检索的性能。
最左匹配原则
对索引中关键字进行计算(比对),一定是从左往右依次进行,且不可跳过。
这里需要说明一点,字符串也可以进行大小比对,在我们创建库、表的时候需要选择字符集及排序规则,都是有用的,它会影响字符串的排序。
比如一棵 B+tree 中的根节点为一个字符串 abc ,那么我现在要搜索一个为 adc 的索引关键字的数据,根节点 abc 的 ASCII 码为 97 98 99,而 adc 的为 97 100 99,那么和3个数字会逐一比对,且100>98,接下去一定会走右子树。
联合索引
- 单列索引:节点中关键字[name]
- 联合索引:节点中关键字[name,phoneNum]
单列索引是特殊的联合索引
联合索引列选择原则:
- 经常用的列优先【最左匹配原则】
- 选择性(离散度)高的列优先【离散度高原则】
- 宽度小的列优先【最少空间原则】
案例一
比如公司经排查发现最常用的 SQL 语句,如何在 users 表上建立索引?
select * from users where name = ? ;select * from users where name = ? and phoneNum = ?;
机灵的李二狗的解决方案:
create index idx_name on users(name);-- 上面一个是冗余索引,不需要建立,根据最左原则,下面这个联合索引适用于以上2个sql语句create index idx_name_phoneNum on users(name, phoneNum);
案例二
登录业务需要执行如下 SQL,如何在 users 表上建立索引?
select uid, login_time from t_user where login_name=? and passwd=?
可以建立 (login_name, passwd) 的联合索引。为什么呢?
联合索引能够满足最左侧查询需求,例如 (a, b, c) 三列的联合索引,能够加速 a | (a, b) | (a, b, c) 三组查询需求。这也就是为何不建立 (passwd, login_name) 这样联合索引的原因,业务上几乎没有 passwd 的单条件查询需求,而有很多 login_name 的单条件查询需求。
如下查询能否命中 (login_name, passwd) 这个联合索引?
select uid, login_time from t_user where passwd=? and login_name=?
答案是可以,最左侧查询需求,并不是指 SQL 语句的写法必须满足索引的顺序(这是很多朋友的误解),应该是 MySQL 对传入的 SQL 执行了优化。
覆盖索引
如果查询列可通过索引节点中的关键字直接返回,则该索引称之为覆盖索引。
覆盖索引可减少数据库 IO,将随机 IO 变为顺序 IO,可提高查询性能。
总结及验证
- 索引列不允许为空
- 索引列的数据长度能少则少
- 索引一定不是越多越好,越全越好,一定是建合适的
- 匹配列前缀可用到索引 like 9999%,like %9999%、like %9999 用不到索引
- where 条件中 not in 和 <> 操作无法使用索引
- 匹配范围值,order by 也可用到索引
- 多用指定列查询,只返回自己想到的数据列,少用 select *
- 联合索引中如果不是按照索引最左列开始查找,无法使用索引
- 联合索引中精确匹配最左前列并范围匹配另外一列可以用到索引
- 联合索引中如果查询中有某个列的范围查询,则其右边的所有列都无法使用索引
作者:殷建卫 链接:https://www.yuque.com/yinjianwei/vyrvkf/uy1aeo 来源:殷建卫 - 架构笔记 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

若有收获,就点个赞吧
0 人点赞
