强缓存和协商缓存
在介绍缓存的时候,我们习惯将缓存分为强缓存和协商缓存两种。两者的主要区别是使用本地缓存的时候,是否需要向服务器验证本地缓存是否依旧有效。顾名思义,协商缓存,就是需要和服务器进行协商,最终确定是否使用本地缓存
缓存方案的问题点
01.强缓存
我们知道,强缓存主要是通过http请求头中的 Cache-Control 和 Expire 两个字段控制。Expire是HTTP1.0标准下的字段,在这里我们可以忽略。我们重点来讨论的Cache-Control这个字段。
一般,我们会设置Cache-Control的值为“public, max-age=xxx”,表示在xxx秒内再次访问该资源,均使用本地的缓存,不再向服务器发起请求。
显而易见,如果在xxx秒内,服务器上面的资源更新了,客户端在没有强制刷新的情况下,看到的内容还是旧的。如果说你不着急,可以接受这样的,那是不是完美?
然而,很多时候不是你想的那么简单的,如果发布新版本的时候,后台接口也同步更新了,那就gg了。有缓存的用户还在使用旧接口,而那个接口已经被后台干掉了。怎么办?
02.协商缓存
协商缓存最大的问题就是每次都要向服务器验证一下缓存的有效性,似乎看起来很省事,不管那么多,你都要问一下我是否有效。但是,对于一个有追求的码农,这是不能接受的。每次都去请求服务器,那要缓存还有什么意义。
缓存的意义就在于减少请求,更多地使用本地的资源,给用户更好的体验的同时,也减轻服务器压力。所以,最佳实践,就应该是尽可能命中强缓存,同时,能在更新版本的时候让客户端的缓存失效。
在更新版本之后,如何让用户第一时间使用最新的资源文件呢?机智的前端们想出了一个方法,在更新版本的时候,顺便把静态资源的路径改了,这样,就相当于第一次访问这些资源,就不会存在缓存的问题了。
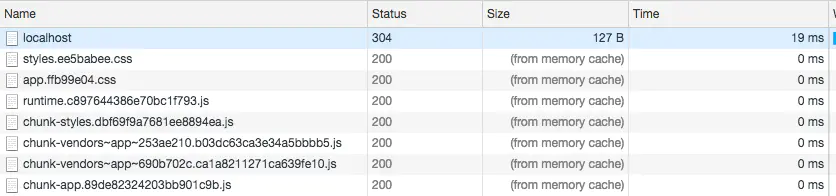
伟大的webpack可以让我们在打包的时候,在文件的命名上带上hash值。
entry:{main: path.join(__dirname,'./main.js'),vendor: ['react', 'antd']},output:{path:path.join(__dirname,'./dist'),publicPath: '/dist/',filname: 'bundle.[chunkhash].js'}
综上所述,我们可以得出一个较为合理的缓存方案:
- HTML:使用协商缓存。
- CSS&JS&图片:使用强缓存,文件命名带上hash值。
哈希也有讲究
webpack给我们提供了三种哈希值计算方式,分别是 hash、chunkhash 和 contenthash 。那么这三者有什么区别呢?
- hash:跟整个项目的构建相关,构建生成的文件hash值都是一样的,只要项目里有文件更改,整个项目构建的hash值都会更改。
- chunkhash:根据不同的入口文件(Entry)进行依赖文件解析、构建对应的chunk,生成对应的hash值。
- contenthash:由文件内容产生的hash值,内容不同产生的contenthash值也不一样。
显然,我们是不会使用第一种的。改了一个文件,打包之后,其他文件的hash都变了,缓存自然都失效了。这不是我们想要的。
那chunkhash和contenthash的主要应用场景是什么呢?在实际在项目中,我们一般会把项目中的css都抽离出对应的css文件来加以引用。如果我们使用chunkhash,当我们改了css代码之后,会发现css文件hash值改变的同时,js文件的hash值也会改变。这时候,contenthash就派上用场了。
03. preload 内容预加载
元素的 > rel属性的属性值 > preload 能够让你在你的HTML页面中 元素内部书写一些声明式的资源获取请求,可以指明哪些资源是在页面加载完成后即刻需要的。对于这种即刻需要的资源,你可能希望在页面加载的生命周期的早期阶段就开始获取,在浏览器的主渲染机制介入前就进行预加载。这一机制使得资源可以更早的得到加载并可用,且更不易阻塞页面的初步渲染,进而提升性能。
preload 可以让浏览器提前加载指定资源(但是加载后不会执行),这样做可以不阻塞渲染和
**`
document.onload 事件,同时也可以提前加载指定资源,例如字体文件等。当加载完成后可以通过 js 将 rel 属性的值换成对应的类型来执行,比如对于 css 文件,可以将 rel 换成 stylesheet,这样就会执行这个 css 文件。
注意如果预加载跨域请求,需要加上 crossorigin 属性。
<link rel="preload" href="style.css" as="style"><link rel="preload" href="https://example.com/fonts/font.woff" as="font" crossorigin>
ETag计算
Nginx
Nginx官方默认的ETag计算方式是为”文件最后修改时间16进制-文件长度16进制“。例:ETag: “59e72c84-2404”
方式一:使用文件大小和修改时间
function stattag (stat) {var mtime = stat.mtime.getTime().toString(16)var size = stat.size.toString(16)return '"' + size + '-' + mtime + '"'}
方式二:使用文件内容的hash值和内容长度 ```javascript function entitytag (entity) { if (entity.length === 0) { // fast-path empty return ‘“0-2jmj7l5rSw0yVb/vlWAYkK/YBwk”‘ }
// compute hash of entity var hash = crypto .createHash(‘sha1’) .update(entity, ‘utf8’) .digest(‘base64’) .substring(0, 27)
// compute length of entity var len = typeof entity === ‘string’ ? Buffer.byteLength(entity, ‘utf8’) : entity.length
return ‘“‘ + len.toString(16) + ‘-‘ + hash + ‘“‘ }
<a name="92APQ"></a>## ETag与Last-Modified谁优先**协商缓存**,有ETag和Last-Modified两个字段。那当这两个字段同时存在的时候,会优先以哪个为准呢?<br />在Express中,使用了[fresh](https://github.com/jshttp/fresh)这个包来判断是否是最新的资源。主要源码如下:我的总结就是一般情况下Last-Modified已经足够,ETag只在特定情况下才更有用,前端发布文件不可能一秒发布好多次,而且ETag可能会给服务器带来更大的开销,所以一般就用Last-Modified就行是一个响应首部,其中包含源头服务器认定的资源做出修改的日期及时间。 它通常被用作一个验证器来判断接收到的或者存储的资源是否彼此一致。由于精确度比 [`ETag`](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/ETag) 要低,所以这是一个备用机制。包含有 [`If-Modified-Since`](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/If-Modified-Since) 或 [`If-Unmodified-Since`](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/If-Unmodified-Since) 首部的条件请求会使用这个字段。```javascriptfunction fresh (reqHeaders, resHeaders) {// fieldsvar modifiedSince = reqHeaders['if-modified-since']var noneMatch = reqHeaders['if-none-match']// unconditional requestif (!modifiedSince && !noneMatch) {return false}// Always return stale when Cache-Control: no-cache// to support end-to-end reload requests// https://tools.ietf.org/html/rfc2616#section-14.9.4var cacheControl = reqHeaders['cache-control']if (cacheControl && CACHE_CONTROL_NO_CACHE_REGEXP.test(cacheControl)) {return false}// if-none-matchif (noneMatch && noneMatch !== '*') {var etag = resHeaders['etag']if (!etag) {return false}var etagStale = truevar matches = parseTokenList(noneMatch)for (var i = 0; i < matches.length; i++) {var match = matches[i]if (match === etag || match === 'W/' + etag || 'W/' + match === etag) {etagStale = falsebreak}}if (etagStale) {return false}}// if-modified-sinceif (modifiedSince) {var lastModified = resHeaders['last-modified']var modifiedStale = !lastModified || !(parseHttpDate(lastModified) <= parseHttpDate(modifiedSince))if (modifiedStale) {return false}}return true}
我们可以看到,如果不是强制刷新,而且请求头带上了if-modified-since和if-none-match两个字段,则先判断etag,再判断last-modified。当然,如果你不喜欢这种策略,也可以自己实现一个。
补充:后端需要怎么设置
上文主要说的是前端如何进行打包,那后端怎么做呢? 我们知道,浏览器是根据响应头的相关字段来决定缓存的方案的。所以,后端的关键就在于,根据不同的请求返回对应的缓存字段。 以nodejs为例,如果需要浏览器强缓存,我们可以这样设置:
res.setHeader('Cache-Control', 'public, max-age=xxx');
res.setHeader('Cache-Control', 'public, max-age=0');res.setHeader('Last-Modified', xxx);res.setHeader('ETag', xxx);

若有收获,就点个赞吧
0 人点赞
