第一个成功在Image Classification实践出 InfoNCE 的是 CPC 这篇文章 (基本上是 DeepMind 同一个 team 的作品)。很直观的利用在图片上裁切 Patch的方式,做出 Positive & Negative samples,实现 Contrastive Loss。
Motivation
人类可以快速学习从少量的sample,但是目前机器学习的算法却不能,依赖大量的标注数据,这篇论文就是在CPC基础上improve data-efficiency.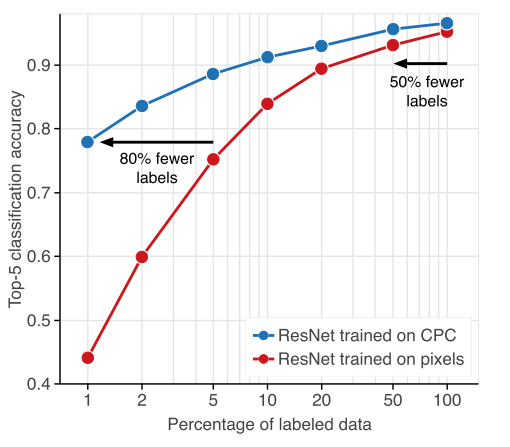
如上图所示,红线是supervised network的表现,可以看出来随着labeled data的减少,performance下降很明显。在使用CPC学习到unsupervised representations之后,network可以保存一个相对更高的accuracy在一个low-data情况下。
Contribution:
- 使用low-data去训一个表现相对较好的model,+20% Top-5 accuracy over the previous state-of-the-art
- Finally, we assess the generality of CPC representations by transferring them to a new task and dataset: object detection on PASCAL-VOC 2007. Consistent with the results from the previous sections, we find CPC to give state-of-the-art performance in this setting (76.6% mAP), surpassing the performance of supervised transfer learning (+2% absolute improvement).
这边用到了三个Network,分别是 feature extractor, context prediction 跟 downstream task network。这是因问 SSL 的 evaluation 方式不同的关系,这边简单说明一下。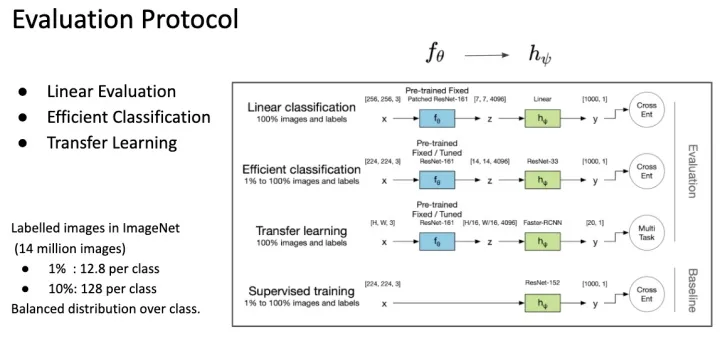
SSL训练出来的模型基本上不能直接使用,通常只能作为很强的 Pretrained Model。因此要评估Pretrained Model 好坏通常做 Linear Evaluation ,Fine-tune 一个 Linear Classifier 看能达到多少的准确度(为了公平,通常这个 classifier 会用 grid search 得到)。
研究后来发现, SSL Pretrained Model 不仅得到 Linear Separable 的 Feature Space; 并且这些 Feature是很丰富的,因为只需要少量的 Data 就可以达到很好的效果,这称为 Efficient Classification Evaluation。像常常会测试,拿ImageNet (有 1000类一千四百万张图片) 1% 的资料量(也就是每个类别 Randomly choose 12 张图片) 来训练。这种Evaluation 凸显出 Feature 是能广泛描述各种类别的,因此只要取少少的 Samples 就可以达到效果。
第三种Evaluation 就是将 Pretrained Model 运用在各种Vision Task 上,例如拿到 Object Detection 或 Segmentation 任务上依旧能表现不错。
回到CPC 这篇文章,ResNet-50 Linear Protocol 能达到 Top-1 71.5% 的准确率;在 Efficient Classification Protocol上,能比原本 Supervised Learning 的方式省掉至少 50% ~ 80% 的资料(这边是参数更多的 ResNet)。意味着通过SSL Pretrained Model,我能够少一些人工标记一样能达到原本 Supervised Learning 的准确度。
Contrastive Predictive Coding
将CPC当应用于图像时,CPC的原始公式通过从位于其上方的那些位置预测某个位置以下的色块的表示进行操作。 这些预测是使用对比损失contrastive loss 进行评估的,在对比损失中,网络必须在一组不相关的negative samples中正确地将positive sample分类。
对于每一个输入的image,首先将其分割成a set of overlapping patches  , 对于每个patch,将其使用CNN编码为一个vector
, 对于每个patch,将其使用CNN编码为一个vector  . 然后, a masked convolutional network
. 然后, a masked convolutional network  被应用在 grid of feature vectors。这个masked 使得each resulting context vector
被应用在 grid of feature vectors。这个masked 使得each resulting context vector  只包括位于当前image前面的feature vectors。然后预测任务包含预测未来
只包括位于当前image前面的feature vectors。然后预测任务包含预测未来 从当前的一个vector 。预测是线性的如下:
从当前的一个vector 。预测是线性的如下:
 是一个a prediction matrix。整体的一个修改于 the CPC objective 如下:
是一个a prediction matrix。整体的一个修改于 the CPC objective 如下:
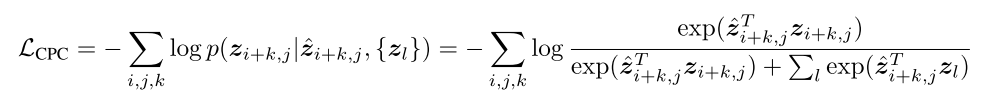
The negative samples  是采样来自于一个image的其他patch或者 other images的patch。这个loss的目的是to maximize the mutual information and .
是采样来自于一个image的其他patch或者 other images的patch。这个loss的目的是to maximize the mutual information and .
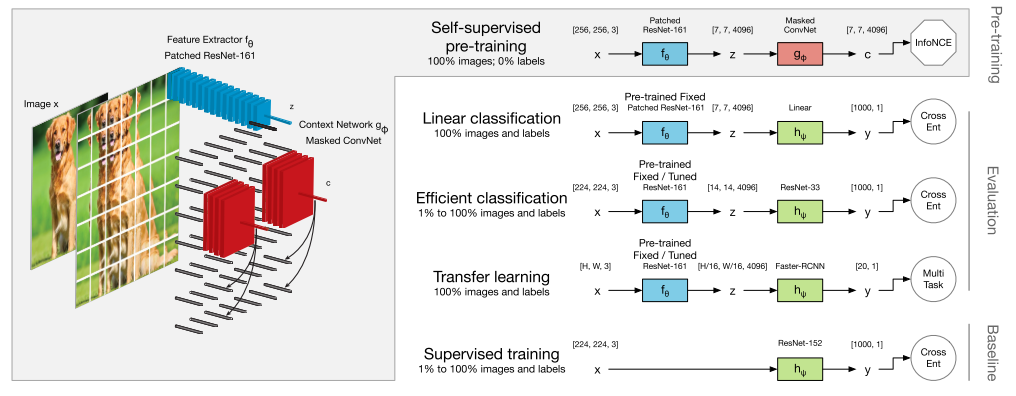
整体优化过程如上所示,首先一个image被分为很多patch,每个patch被一个feature extractor采样(blue),得到一个single feature vector。然后用一个 context network (red)去聚合一个vector之前的所有feature vector,也就是从左上到右下的顺序。生成a row of context vectors用于线性预测下面的向量。
右边部分就是具体的下游任务了,在这个部分the context network (red) 被丢弃,classifier network (green) 被使用在一个监督的方式。

若有收获,就点个赞吧
0 人点赞
