常规操作
(1)正则化
机器学习中的正则化(Regularization)
使用正则化,降低模型的复杂度,增强模型的泛化能力。在目标函数后面添加一个系数的“惩罚项”是正则化的常用方式,为了防止系数过大从而让模型变得复杂。
L1正则化时,对应惩罚项为 L1 范数 :
L2正则化时,对应惩罚项为 L2 范数:
L1正则化更容易造成特征的系数为0,引起特征稀疏,适用于特征选择,而L2正则化会使,系数按照一个比例缩放趋向于变小,而不会变成0,因此使模型更简单,更适用于防止模型过拟合。ps:具体看链接证明。
(2)Early stopping
具体做法是,在每一个Epoch结束时(一个Epoch集为对所有的训练数据的一轮遍历)计算validation data的accuracy,当accuracy不再提高时,就停止训练。
(3)数据增强
从数据源采集更多数, 复制原有数据并加上随机噪声,重采样,根据当前数据集估计数据分布参数,使用该分布产生更多数据等
(4) Dropout
随机得删除一些(可以设定为一半,也可以为1/3,1/4等)隐藏层神经元.
一些常规操作就不具体展开了,我看了一些其他的一些骚操作,其实都可以理解为正则(个人认为)。
Consistency Regularization
半监督深度学习又小结之Consistency Regularization
具体很多可以直接参考上面的链接,我也是看到这个链接启发和笔记的。
Consistency Regularization(规则一致性) 的主要思想是:对于一个输入,即使受到微小干扰,其预测都应该是一致的。
比如:人脸检测来说,对于同一个人,戴眼镜或者不戴眼镜,长头发和短头发,网络的输出应该是不变的,即是都能识别。
Learning with Pseudo-Ensembles
论文:http://papers.nips.cc/paper/5487-learning-with-pseudo-ensembles.pdf
代码:https://github.com/Philip-Bachman/Pseudo-Ensembles
这是NIPS 2014年发表的工作,其提出了一个概念:pseudo-ensemble,一个 pseudo-ensemble 是一系列子模型(child model),这些子模型通过某种噪声过程(noise process)扰动父模型(parent model)得到。
What is a pseudo-ensemble?
对于一个在分布为 的数据集上面训好的模型,他的参数为
的数据集上面训好的模型,他的参数为 ,这个模型被一些noise process
,这个模型被一些noise process  扰动后,我们会得到一些child models
扰动后,我们会得到一些child models  ,该论文就是想要这些child models的效果和parent model一样。
,该论文就是想要这些child models的效果和parent model一样。
Pseudo-ensemble 与其他的有关扰动的方法的区别在于:其他的方法只考虑在输入空间的扰动,而 pseudo-ensemble 还考虑在模型空间(model space)上的扰动。一个典型的 pseudo-ensemble 就是 Dropout。
Pseudo-ensemble的目的是使得模型更加鲁邦,具体的loss计算公式可用下面公式表示: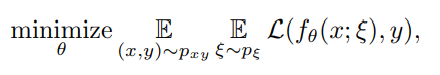
 代表某种noise 扰动,
代表某种noise 扰动, 是label,目的就是让扰动得到的student model和label一致(感觉就是正则化)。
是label,目的就是让扰动得到的student model和label一致(感觉就是正则化)。
论文中还提出其半监督形式:The Pseudo-Ensemble Agreement regularizer(PEA),其形式如下: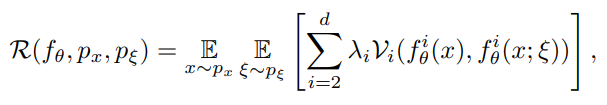
其中  是网络的层数,其含义应该是把父模型的每一层中间表示,与子模型的进行一致正则,
是网络的层数,其含义应该是把父模型的每一层中间表示,与子模型的进行一致正则,  是某种惩罚函数,如MSE代价。
是某种惩罚函数,如MSE代价。
本质就是对于一个输入,收到扰动后,其所有的中间模型表示都应该一致。
Regularization With Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning[1]
这是NIPS 2016年发表的工作。随机性在大部分的学习系统中起到重要的作用,深度学习系统也如此。一些随机技术,如随机数据增强、Dropout、随机最大池化等,可以使得使用SGD训练的分类器具有更好的泛化性和鲁棒性。
而且这种不确定性的存在,使得模型对同一个样本的多次预测结果可能不同。因此论文提出一个无监督代价(即我说的半监督正则),其通过最小化对同一个样本的多次预测,利用这种随机性来达到更好的泛化性能。
Temporal Ensembling for Semi-supervised Learning
论文:https://openreview.net/pdf?id=BJ6oOfqge
代码:https://github.com/smlaine2/tempens
ICLR 2017,该论文认为,同一个输入,在不同的正则和数据增强条件下,网络对其预测应该是一致的。其无监督代价部分如下:
其中  是网络的一个预测,而
是网络的一个预测,而  是网络对同一个样本在不同的正则和数据增强条件下的一个预测,然后让着两个预测一致。
是网络对同一个样本在不同的正则和数据增强条件下的一个预测,然后让着两个预测一致。
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results
论文:https://arxiv.org/abs/1703.01780
代码:https://github.com/CuriousAI/mean-teacher
NIPS 2017,Teacher-student consistency。
其想法就是,我从当前的模型(Student model),构造出一个比 Student model 更好一些的 Teather model,然后用这个 Teacher model 的预测来训练 Student model(即 consistency regularization)。
其无监督代价部分如下:
其中  是 Teacher model 的预测,
是 Teacher model 的预测,  是 Student model 的预测
是 Student model 的预测
如何去构建Teacher model?
论文提出的方法是,对 Student model 每次更新的模型做移动平均,移动平均后的模型就是 Teacher model,Teacher model 也不用反向传播更新,就参数的移动平均足以。其移动平均公式如下:

有没有一种好神奇的感觉,效果还非常地好。论文还用实验说明,其能形成一个良好的循环,得到一个 Student model,构造一个更好的 Teacher model,然后这个 Teacher model 又能用来升级 Student model,然后又….
当然,由于 Student model 刚开始只用有限的有标签数据训练,其性能并不好,因此该无监督代价同样需要乘一个权重(函数),这个权重函数和 Temporal Ensembling for Semi-supervised Learning 一样。
References
[1] Miyato, Takeru, Shin-ichi Maeda, Masanori Koyama, and Shin Ishii. “Virtual adversarial training: a regularization method for supervised and semi-supervised learning.” IEEE transactions on pattern analysis and machine intelligence 41, no. 8 (2018): 1979-1993.
[2]

若有收获,就点个赞吧
0 人点赞
