Vu, T.H.; Jain, H.; Bucher, M.; Cord, M.; Pérez, P. Advent: Adversarial entropy minimization for domain adaptation in semantic segmentation. Proc. of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 2517–2526.
论文:https://arxiv.org/pdf/1811.12833.pdf
代码:https://github.com/valeoai/ADVENT
关键词: “**entropy of the pixel-wise**” : 1. entropy loss 2.adversarial loss
为了解决domain gap,更好的实现domain之间的分割域迁移,论文中提出了一种the entropy of the pixel-wise predictions,主要有两部分1. entropy loss 2.adversarial loss可以帮助分割网络进行更好的域迁移
Introduction
背景:在真实场景的运用中trianing数据集和testing数据集的分布往往是不一样的,具有很大的domain gap,导致了模型表现的很差。
作者认为模型在训练集上往往会over confidence而在不同分布的测试集上表现往往不够好,这种叫着low-entropy。如果在target domain上面也能表现的很好,叫做high-entropy。
解决办法:因此论文中提出了entropy of the pixel-wise predictions,主要有两部分1. entropy loss 2.adversarial loss可以帮助分割网络进行更好的域迁移
主要分为以下两个部分:
- Direct entropy minimization using an entropy loss
- Indirect entropy minimization using an adversarial loss.
Methodology
主要分为以下两个部分:
(i) an unsupervised entropy loss
(ii) adversarial training
对于在source domain上面训练,常规的交叉熵loss如下: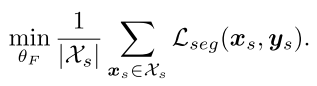
这里 代表着source domain上的分割loss。
代表着source domain上的分割loss。
Direct entropy minimization
对于target domian的数据,论文中采用了Shannon Entropy[1]: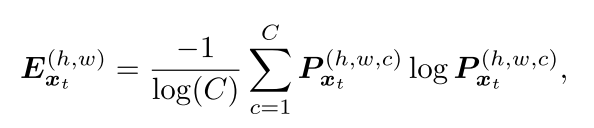
因此最终对于Indirect entropy minimization总的loss如下所示: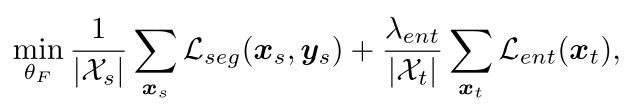
Minimizing entropy with adversarial learning
整个网络框架如下,包含了(i) an unsupervised entropy loss (ii) adversarial training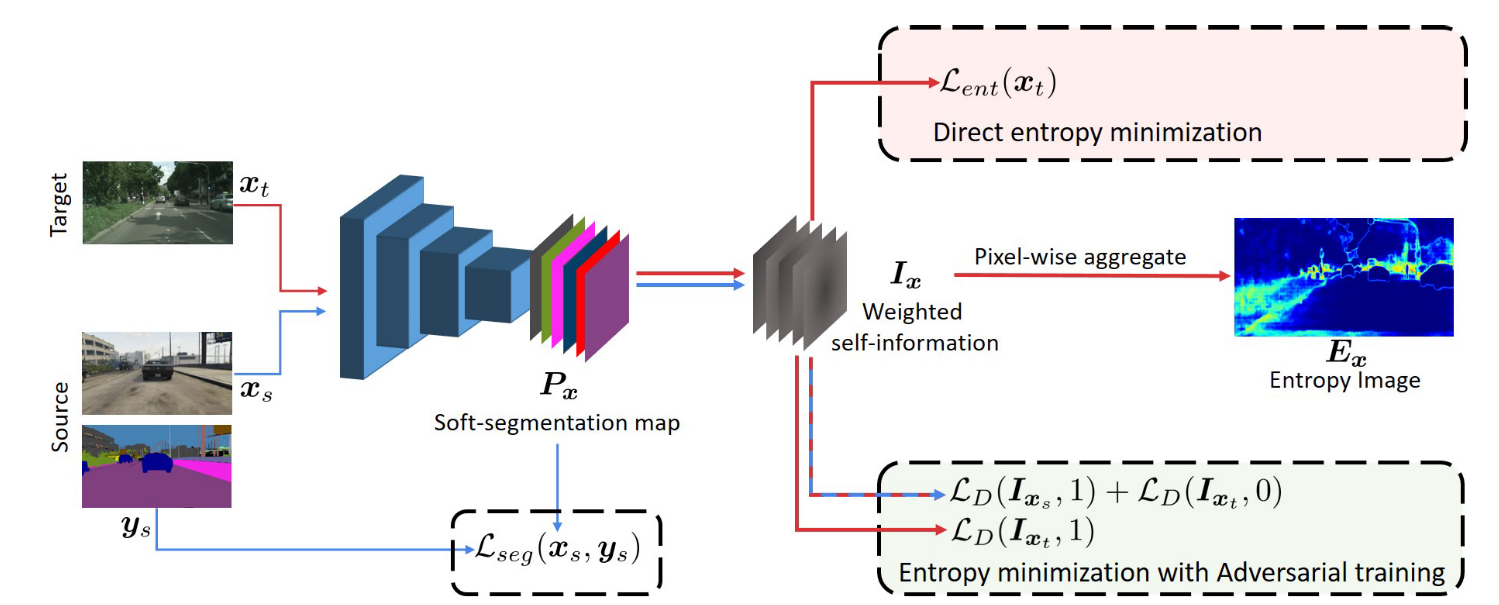
作者认为Direct entropy minimization忽略了局部语义中的结构依赖,依据[2]可知,在结构依赖空间的域自适应是有利的,source domain和target domain在语义结构方面具有相似性。因此作者引入了一个unified adversarial training framework间接的优化entropy。具体的就是在 空间minimizing两个domain的分布。
空间minimizing两个domain的分布。
相似于正常的对抗学习过程,论文中也有一个domain classifier和feature extractor,他们的loss形式分别如下:
对于domain classifier,loss如下:
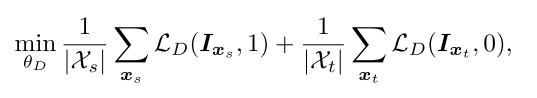
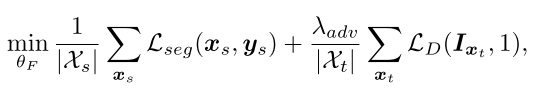
Incorporating class-ratio priors
为了解决easy-head sample问题,提出了一个class-ratio penalization。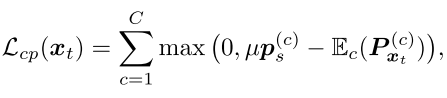
Reference
[1] C. E. Shannon. A mathematical theory of communication. Bell system technical journal, 1948.
[2] Y.-H. Tsai, W.-C. Hung, S. Schulter, K. Sohn, M.-H. Yang, and M. Chandraker. Learning to adapt structured output space for semantic segmentation. In CVPR, 2018. 2, 4, 5, 6, 7

若有收获,就点个赞吧
0 人点赞
