Chen, Yuhua, Wen Li, Christos Sakaridis, Dengxin Dai, and Luc Van Gool. “Domain adaptive faster r-cnn for object detection in the wild.” In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3339-3348. 2018.
论文:https://arxiv.org/abs/1803.03243
代码:https://github.com/krumo/Domain-Adaptive-Faster-RCNN-PyTorch
(有开源代码,好好读一读。。。)
关键词: H-divergence , domain classifier , consistency regularization
这CVPR2018的一篇工作,为了解决domain shift这一个问题,论文中认为domain shift主要发生在 image level和instance level层面上,因此提出了两个在image level和instance level的components的机制去最小化在两个domain之间的H- divergence。具体在每个component之中,主要训练一个domain classifier去学习一个domain-invariant features。
Introduction
背景:在目标检测实际运用中,训练集和测试集的分布往往不是一模一样的(如下图),这种distribution mismatch将会导致严重的performance drop,为了解决domain shift带来的performance drop,**论文提出了一种domain adaptation方式去解决domain discrepancy。**

作者认为domain shift主要表现在两个方面:
1. Image-level shift, such as image style, illumination, etc
2.Instance-level shift, such as object appear- ance, size, etc
为了解决这两种domain-shift引起的performance drop,作者提出了两种domain adapation components,这两种components是基于H-divergence,作者通过在对抗方式下面学习一个domain classifier去减少两个域之间的H-divergence,进而学习到domain-invariant features.
具体贡献:
1) We provide a theoretical analysis of the domain shift problem for cross-domain object detection from a probabilistic perspective.
2) We design two domain adaptation components to alleviate the domain discrepancy at the image and instance levels, resp.
3) We further propose a consistency regularization to encourage the RPN to be domain-invariant.
Distribution Alignment with H-divergence
 -divergence是用来衡量两个不同分布域的差异的指标,具体可以参考[1]和统计学习。
-divergence是用来衡量两个不同分布域的差异的指标,具体可以参考[1]和统计学习。
对于一个特征向量 , source domain的标记为
, source domain的标记为 ,target domain的
,target domain的 标记为
标记为 ,在这两个domain之间的-divergence可以表示为:
,在这两个domain之间的-divergence可以表示为: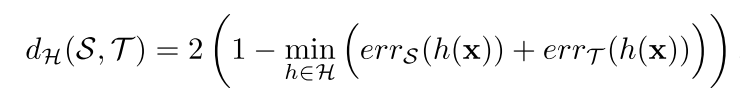
 和
和 是domain classifier的
是domain classifier的 ,当然分别对应source domian和target domain。在这里-divergence是和domain classifier的相反的,越大domain classifier效果越差,更难分开这两个domain,-divergence越小。
,当然分别对应source domian和target domain。在这里-divergence是和domain classifier的相反的,越大domain classifier效果越差,更难分开这两个domain,-divergence越小。
因此我们要去最小化这个-divergence从而能学到domain-invariant feature,具体实现公式如下: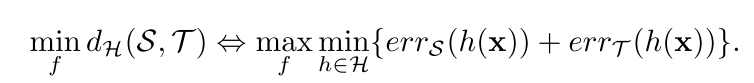
这个公式可以是使用gradient reverse layer (GRL)进行实现的,这个GRL可以参考我的另一篇笔记——-GRL(ICML). 大概就是在对抗学习的方式下去学习domain-invariant feature。
Methods
A Probabilistic Perspective
论文中认为目标检测问题可以看成是一个学习后验概率 的问题,这里
的问题,这里 代表image 的feature,
代表image 的feature, 是预测到的bounding-box,
是预测到的bounding-box,  是目标的类别。
是目标的类别。
论文中把source domain和target domain的分布标记为 和
和 ,在域迁移的问题中,我们用去分析domain shift问题,当
,在域迁移的问题中,我们用去分析domain shift问题,当 .
.
Image-Level Adaptation
使用贝叶斯公式,联合分布可以分解为
对于source domain和target domain而言,条件概率是相同的,domain distribution shift主要是由于特征提取 的不同导致的。因此为了解决domain shift问题,我们应该使得两个domain的image representation相同,即是
的不同导致的。因此为了解决domain shift问题,我们应该使得两个domain的image representation相同,即是 相同,这里指的是
相同,这里指的是 .
.
Instance-Level Adaptation
对于instance level来说,贝叶斯公式在这又能写成:
与image-level一样,对于instance-level来说,在两个domain上的条件概率 应该是相同的,domain shift应该是来自于
应该是相同的,domain shift应该是来自于 .更直观来说,对于一个ground true box框出来的同一类object,不管他来自于哪个domain,他的class预测都应该是相同的,即
.更直观来说,对于一个ground true box框出来的同一类object,不管他来自于哪个domain,他的class预测都应该是相同的,即 .
.
Joint Adaptation
对于image-level和instance-level的域迁移来说,我们先思考 ,然后他的条件概率
,然后他的条件概率 应该是相同的,啥意思呢?就是说对于source domain和target domain来说,对于提出到相同的feature来说,预测到box的概率,即条件概率应该是相同的。因此我们能得到下面这个等式:
应该是相同的,啥意思呢?就是说对于source domain和target domain来说,对于提出到相同的feature来说,预测到box的概率,即条件概率应该是相同的。因此我们能得到下面这个等式:
所以可得出结果,image-level统一的话,instance-level也应该是统一的,然后对于两个domain来说往往是不同的,原因如下:
(1 、在实际操作中,他是很困难的去align the marginal distributions, 因此造成了是有偏差的。
(2 、 对于source domain和target domain而言,label只在source domain上有的因此只能学习source domain的数据,会造成偏差。
为了使得两个domain 在image-level和instance-level上面做到distribution alignment,论文中提出consistency regularization去使得匹配。具体是使用domain classifier结合H-divergence去学习domain-invariant feature。
我们把domain label叫做 ,那么image-level水平的domain classifier是
,那么image-level水平的domain classifier是 ,instance-level的domain classifier应该是
,instance-level的domain classifier应该是 ,使用贝叶斯推理,我们得到下面这个公式:
,使用贝叶斯推理,我们得到下面这个公式:
从这个公式中,我们知道是domain-invariant bounding box predictor, 是一个domain-dependent bounding box predictor,事实上对于只用source domain的label监督时,我们会学到一个依赖source domain的一个网络,为了使得我们的学到domain-invariant feature,我们应该使趋向于。
是一个domain-dependent bounding box predictor,事实上对于只用source domain的label监督时,我们会学到一个依赖source domain的一个网络,为了使得我们的学到domain-invariant feature,我们应该使趋向于。
Domain Adaptation Components
这个section主要提出两个components去对其image-level和instance-level的feature representation distribution。
Image-Level Adaptation
为了部分消除domain distribution mismatch,论文中使用一个patch-based的domain classifier。使用patch-based的方法有下面两个好吃:
1、对齐image-level的representations,学习domain-invariant features,然后也很高效,具体可以参考[2]
2、patch-based是更有利的去提升batchsize
这里loss类似分割交叉熵二分类:
 是每个pixel的prediction,
是每个pixel的prediction, 是domain label。然后就是使用GRL对网络进行对抗学习优化,居然的GRL实现参考我另一篇笔记——> GRL。
是domain label。然后就是使用GRL对网络进行对抗学习优化,居然的GRL实现参考我另一篇笔记——> GRL。
Instance-Level Adaptation
这里使用了ROI-based,就是拿出输入category classifier之前的特征向量,对齐两个domain的这些特征向量,对齐这些向量的目的是学习object的invariant-features, 消除一些影响如object appearance, size, viewpoint etc.具体的loss如下: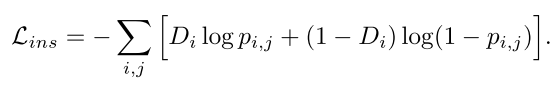
这里也用了GRL对抗学习,感觉就是对每个instance进行了domain的分类。说直白点就是image和instance都进行domain的二分类。
Consistency Regularization
这里impose a consistency regularizer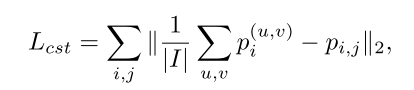
感觉就是直接对image-level和instance-level的特征向量做了一个 distance计算。
distance计算。
Network Overview
整体的网络框架如下: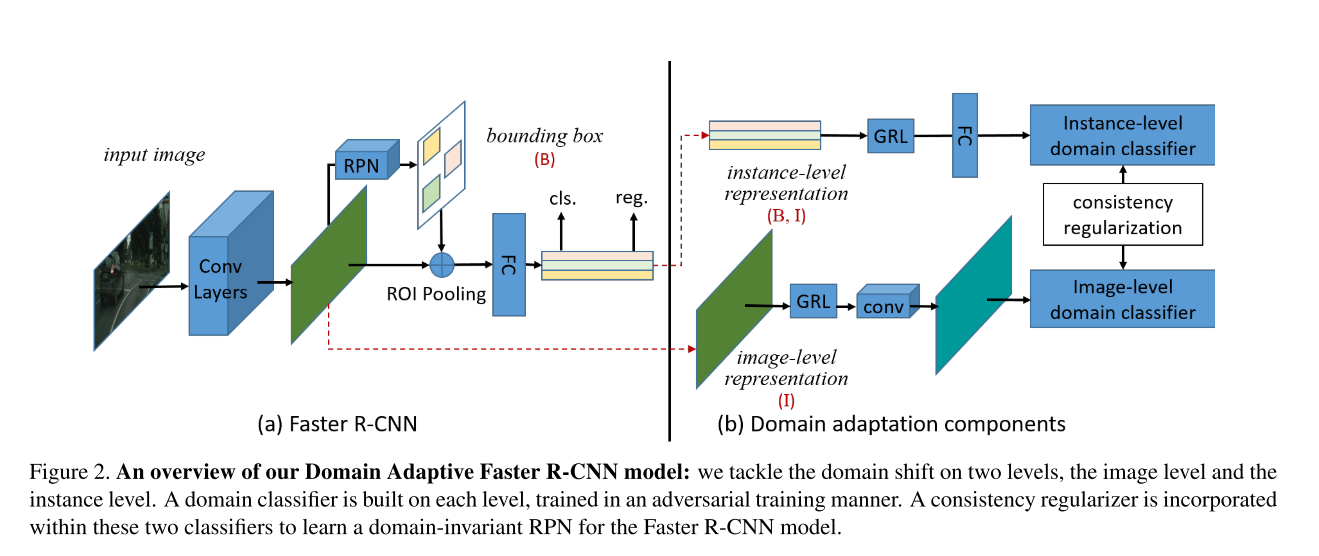
左边是原始的faster rcnn,bottom convolutional layers是共享的。image-level的domain classifier是加在最后一层cnn之后的,instance-level是加在ROI-wise feature之后的。两个loss被衔接使用consistency loss,最后全部loss如下计算: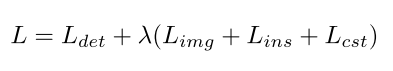
Coding
References
[1] S. Ben-David, J. Blitzer, K. Crammer, A. Kulesza, F. Pereira, and J. W. Vaughan. A theory of learning from different do- mains. Machine learning, 79(1):151–175, 2010
[2] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In ECCV, 2016.

若有收获,就点个赞吧
0 人点赞
