Harutyunyan, Hrayr, et al. “Improving Generalization by Controlling Label-Noise Information in Neural Network Weights.” arXiv preprint arXiv:2002.07933 (2020).
论文:链接
代码:https://github.com/hrayrhar/limit-label-memorization
关键词: “predicts gradients” ,“without labels” , “underlying knowledge”
提出了一个辅助network去预测,在不适用label的情况下去预测classifier的最后一层梯度。
Introduction
背景:对于noise label,一些方法例如dropout, weight decay or data augmentation虽然可以有效的去缓解noise的负面影响,但是不能从本质上解决这种问题。网络具有很强的memorized information,在label给定的信息下进行监督会学习到 Shannon mutual information ,即label和预测,输入的关系,在这种前提下,是无法从根本上解决noise label的干扰。
,即label和预测,输入的关系,在这种前提下,是无法从根本上解决noise label的干扰。
解决办法:提出了一个辅助network去预测,在不使用label的情况下去预测classifier的最后一层梯度。
Contributions主要分为以下两个部分:
- 构建一个低质量的,去降低memorization 性能,包括对label noise,进而增强网络的泛化能力。
- 提出了一种training methods,通过控制正则化weights中的label noise information去控制memorization。为了去控制梯度中的noise information,一个可行的方法是使用一个辅助网络去预测梯度。
在实现过程中包含两个步骤:
1、一个是使用一个auxiliary network去惩罚classifier
2、使用predicted gradients 去训练这个网络。
最后auxiliary network can be used to detect incorrect or misleading labels.
Methodology
Label-Noise Information in Weights
首先提出了一种measure对于 label noise information in weights。论文中使用几种常见的information-theoretic quantities:
Entropy:

- Mutual information:

- KullbackLeibler divergence:

对于输入数据 ,有对应的categorical label:
,有对应的categorical label: ,对于任何的训练算法,训练performance可以表示为下面expected cross entropy:
,对于任何的训练算法,训练performance可以表示为下面expected cross entropy: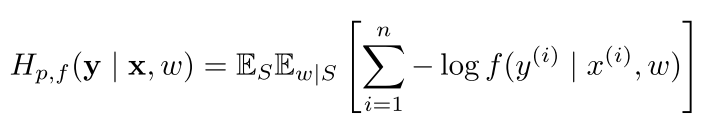
根据论文Emergence of Invariance and Disentanglement in Deep Representations[1]得定义可以分解为下面: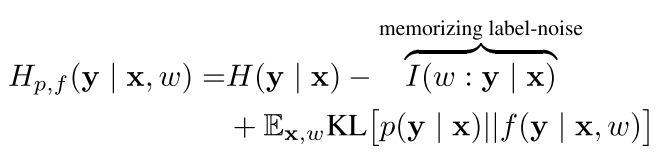
具体推导可以看论文Emergence of Invariance and Disentanglement in Deep Representations[1],如上面公式所示:如果label包含大量的信息超过了网络处理输入能提取到的信息 ,监督label进行学习确实能获得好的效果。
,监督label进行学习确实能获得好的效果。
为了更方便理解,这里简单介绍一下[1]中的Learning minimal weights:
我们将一个未知数据集的分布表示为 ,
, 是网络参数在network拟合数据集分布的过程中优化得到的。因此可以把神经网络学习看成一个map过程:
是网络参数在network拟合数据集分布的过程中优化得到的。因此可以把神经网络学习看成一个map过程: ,从输入input到一个class 分类
,从输入input到一个class 分类
事实上最小化empirical cross-entropy loss也能取得很好的效果 ,
,
Decreasing I(w : y | x) Reduces Memorization
对于一个数据集 , 使用随机梯度去学习一个分类模型
, 使用随机梯度去学习一个分类模型 .
.
[1] Achille, Alessandro, and Stefano Soatto. “Emergence of invariance and disentanglement in deep representations.” The Journal of Machine Learning Research 19.1 (2018): 1947-1980.

若有收获,就点个赞吧
0 人点赞
