DeepMind提出对比预测编码,通过预测未来学习高级表征
CPC解读
通用的无监督学习方法——对比预测编码,从高维数据中提取有用的表征
DeepMind在2017 年(https://arxiv.org/abs/1807.03748)提出一种基于Mutual Information修改 AutoRegrssive 的 Loss Function,称为 InfoNCE 。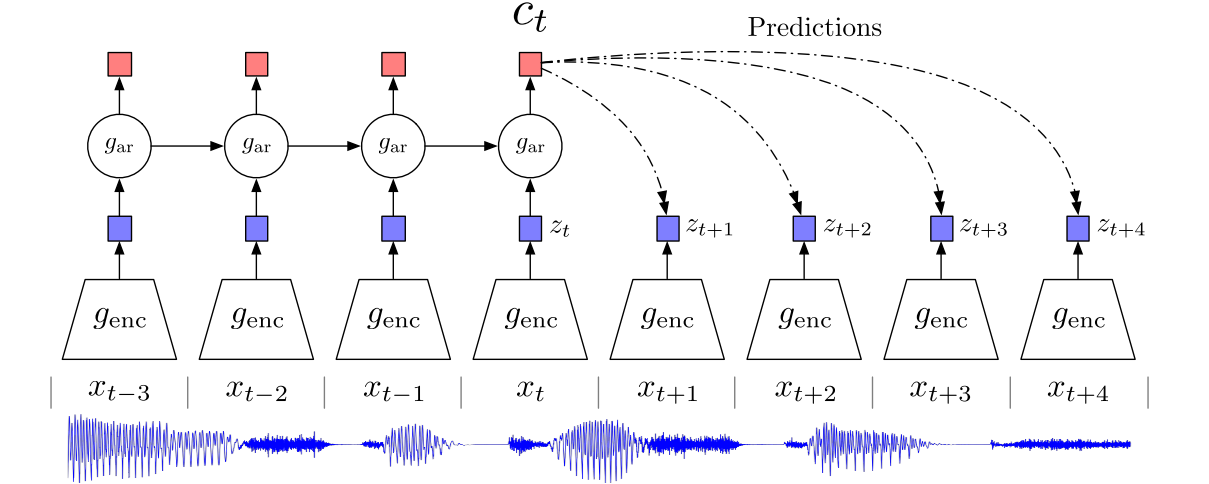
从图上说明是相当直观的,模型基于看过的Data 提取 Context (也就是 Feature) 并且对未来做预测。并且Loss Function的目标是让 Data 和 Context 的 Mutual Information 越大越好。
在这个图里,raw data是最下面的语音信号 { },我们想要找到一个好的representation vector {
},我们想要找到一个好的representation vector {  },这个{
},这个{  }不仅能尽可能地保留原信号 {
}不仅能尽可能地保留原信号 { }的重要信息,也有很好的预测能力。
}的重要信息,也有很好的预测能力。
首先我们在原信号上选取一些时间窗口frames,对每一个frame,我们用一个有编码能力的函数(比如autoencoder或者cnn)  。然后得到representation vector
。然后得到representation vector

接下来为了做预测,我们把{  }放到一个可以做预测的model里,论文里不是一般性地用
}放到一个可以做预测的model里,论文里不是一般性地用  来表示这个可以做预测的有回归性质的model,通常大家会用RNN(LSTM),我们用t时刻及其之前的若干时刻输入这个回归模型,得到t时刻的涵盖了对过去信息的memory的输出
来表示这个可以做预测的有回归性质的model,通常大家会用RNN(LSTM),我们用t时刻及其之前的若干时刻输入这个回归模型,得到t时刻的涵盖了对过去信息的memory的输出 。
。
接下来,我们希望 是足够好的,是具有预测性质的。怎么评价它好不好呢?
是足够好的,是具有预测性质的。怎么评价它好不好呢?
Motivation
该论文得目的是学习
作者认为使用整个image的feature训练计算量很大,而且忽略了上下文关系C,并且在一些高纬任务中,如分类任务,学习这么多low feature的细节是没有必要的。因此 建模可能不是最佳的,因此论文中提出了一种新的建模方式:
建模可能不是最佳的,因此论文中提出了一种新的建模方式: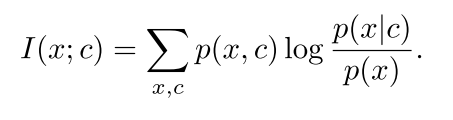
Contrastive Predictive Coding
首先使用a non-linear encoder  maps the input sequence of observations
maps the input sequence of observations  to a sequence of latent representations
to a sequence of latent representations  .
.
an autoregressive model 
Mutual Information是广义上的 Correlation Function。(当我们完全不了解系统的Dynamics 或更深入的行为时,Mutual Information 依旧能作为估算) 它量化了我们能从 Context 中得到多少 Data 的信息,称为 Data 与 Context 之间的 Mutual Information。
InfoNCE Loss and Mutual Information Estimation
首先,为了最大化Mutual Information 让 Network Model Distribution Ratio (而不像 generative model 是单纯 model distribution);并且用简单的 Linear Map 作为从 Context 到Future Data 的预测函数。
InfoNCE写法如下。其实他与常用的 Cross Entropy Loss 并没有太大区别,差异只在于这个 Loss 并不是用于分类,而是注重在对数据的本身做预测。如果用先前 Time Series 的例子就是预测未来。

若有收获,就点个赞吧
0 人点赞
