Li, Junnan, Richard Socher, and Steven CH Hoi. “Dividemix: Learning with noisy labels as semi-supervised learning.” arXiv preprint arXiv:2002.07394 (2020).
论文:链接
代码:https://github.com/LiJunnan1992/DivideMix
关键词: “**dynamically divide**” ,“labeled clean samples” , “unlabeled set with noisy samples”
“**label co-refinemen“ , “label co-guessing**”
对每一个batch进行训练过程中,对每个样本的loss进行建模,将训练数据动态的划分为labed clean sample和unlabeled noise samples,并以半监督的方式对这两种数据进行训练。
Introduction
背景:
解决办法:
Contributions主要分为以下两个部分:
- 提出了一个co-divide,可以同时训练两个网络。对于每个网络,我们动态拟合Gaussian Mixture Model (GMM)在其的per-sample,划分samples为labeled set和unlabled set。划分的数据被另一个network使用。Co-divide保存两个网络离散,因此可以filter different types error 和avoid confirmation bias。
- 在SSL阶段,使用label co-refinement和co-guessing解决噪声问题。对于labled sample,使用另一个网络的预测提炼ground truth。对于unlabled samples,使用两个网络的ensemble进行reliable guesses label操作。
Methodology
整体的网络训练框架如下图所示,DivideMix同时训练A,B两个网络。在每一个epoch,network使用GMM去对每个sample loss进行建模划分数据为labeled set (mostly clean) 和an unlabeled set (mostly noisy),这些数据被交换训练,即A使用B产生的数据训练,B使用A产生的数据训练。
在每个mini batch,MixMatch使用semi-supervised training提升效果,我们进行label co-refinement on the labeled samples and label co-guessing on the unlabeled samples。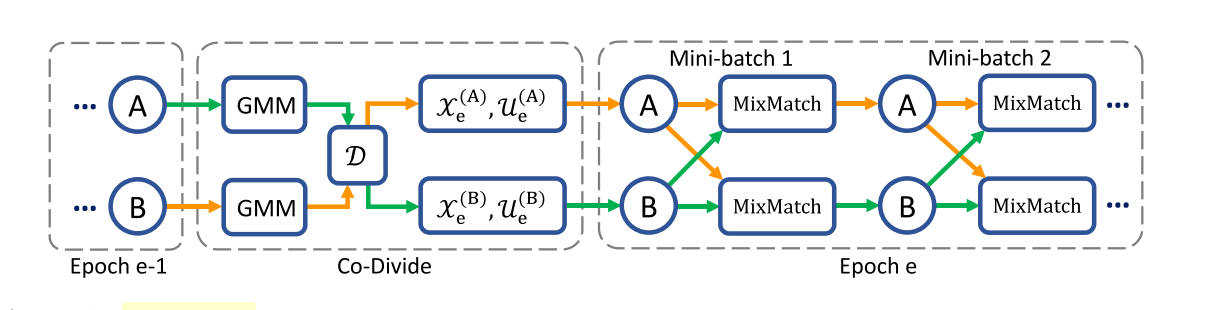
CO-DIVIDE BY LOSS MODELING
首先对于trainin set,我们用 进行表示。cross-entropy loss
进行表示。cross-entropy loss 表示一个model对trainin samples的拟合程度:
表示一个model对trainin samples的拟合程度: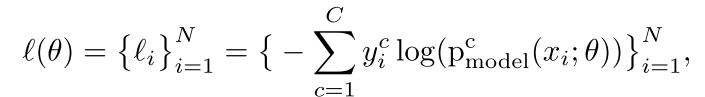
 表示的模型的输出softmax的概率对于class c。
表示的模型的输出softmax的概率对于class c。
论文中使用Gaussian Mixture Model (GMM) 去区分noisy samples由于其对distribution的sharpness的敏感性。对于each sample,他的clean probability  is the posterior probability
is the posterior probability  .
. 是具有更小的mean,smaller loss的 Gaussian component。
是具有更小的mean,smaller loss的 Gaussian component。
然后使用一个 threshold  去划分clean sample和noise sample,从[1]可知使用data divide会导致一个 confirmation bias。因为noise label也可能会被划分为clean label。因此使用co-divide去避免 error accumulation
去划分clean sample和noise sample,从[1]可知使用data divide会导致一个 confirmation bias。因为noise label也可能会被划分为clean label。因此使用co-divide去避免 error accumulation
具体就是交叉训练,因为两个网络是不同的设置和初始化,所以认为可以filter different types of error, making the model more robust to noise.
Gaussian Mixture Model (GMM)
高斯混合模型(Gaussian Mixture Model)
多个高斯分布的线性叠加能拟合非常复杂的密度函数;通过足够多的高斯分布叠加,并调节它们的均值,协方差矩阵,以及线性组合的系数,可以精确地逼近任意连续密度。
我们考虑  个高斯分布的线性叠加,这个高斯混合分布(Gaussian mixture distiburion)的概率密度函数为:
个高斯分布的线性叠加,这个高斯混合分布(Gaussian mixture distiburion)的概率密度函数为:
下图所示为包含两个一维分模型的高斯混合: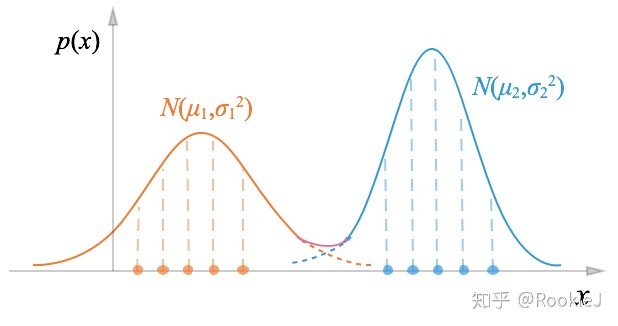
Confidence Penalty for Asymmetric Noise
在训练数据前期有个warm up的过程,目的是使得model对正确的label有一定的感知,使得从loss进行GMM建模可行。warm up是高效的对于symmetric label noise,然而对于asymmetric label noise,模型会过拟合的产生一些over-confident (low entropy) predictions。如下图a: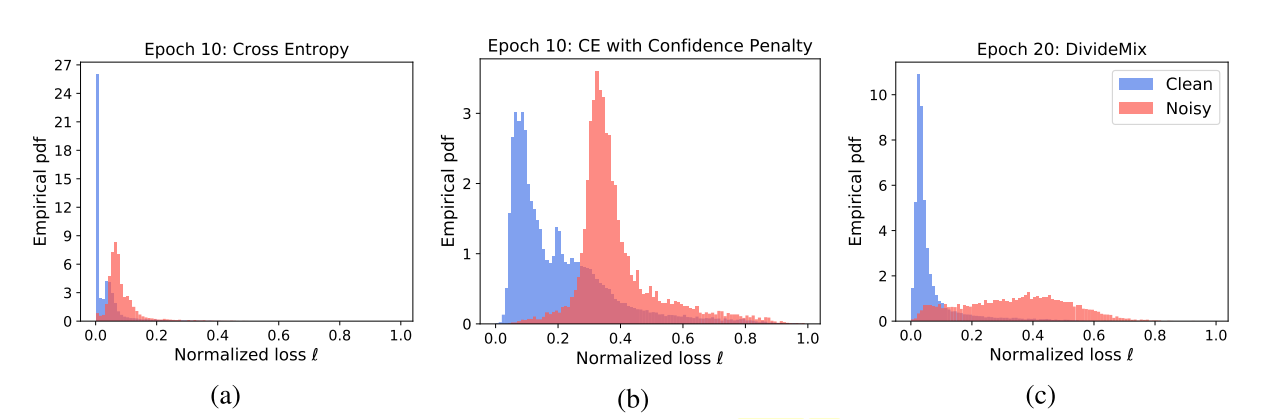
在这种情况下GMM不能高效的区分clean和noisy samples,基于loss distribution。为了使得loss ditribution分布的更均匀更好,给loss加一项惩罚(negative entropy term),这个惩罚来自[2]:
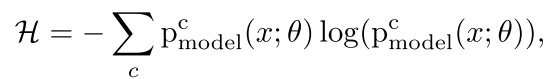
maximizing上面这个惩罚loss,加了惩罚后loss分布更均匀了,如图b所示。图c是再经过DivideMix for 10 more epochs after warm up之后,可以看出来clean的loss更小了,noise的loss更大了。
MIXMATCH WITH LABEL CO-REFINEMENT AND CO-GUESSING
[3] merging merging consistency regularization (i.e. encourage the model to output same predictions on perturbed unlabeled data)去进行标注unlabeled data。
label co-refinement
基于[3]论文中提出了两个改进,使得两个network可以相互教导:对于labeled data首先进行label co-refinement,其实本质是个linearly combining: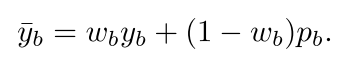
 是ground-truth label,
是ground-truth label, 是网络的预测,clean probability 是
是网络的预测,clean probability 是 ,然后apply a sharpening function on the refined label:
,然后apply a sharpening function on the refined label: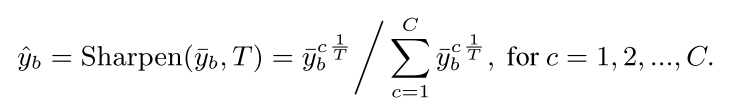
co-guess
然后使用结合both network的输出去co guess he labels for unlabeled samples,which produce more reliable guessed labels。这个pseudo label是直接用两个网络预测生成的简单粗暴。
MixMatch
得到labeled 部分数据和unlabeled部分数据之后将他们进行混合: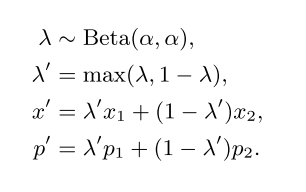
beta分布可以看作一个概率的概率分布,当你不知道一个东西的具体概率是多少时,它可以给出了所有概率出现的可能性大小。最后进行一个loss的计算 the cross-entropy loss 对于labeled 数据the mean squared error对于unlabeled数据: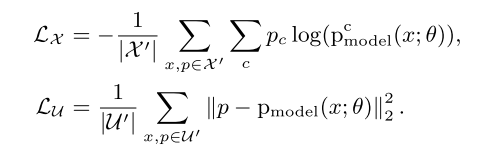
最后为了防止所有的sample预测成一类,加一个惩罚: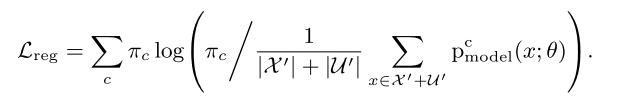
EXPERIMENTS
CIFAR-10
| Backbone | loss | sample number | noise rate(asym) | threshold | ACC(%) |
|---|---|---|---|---|---|
| MobileNet_v2 | CE+penalty | 50000 | 0.3 | 0 | 63.1% |
| MobileNet_v2 | CE+penalty | 40067 | 0.246 | 0.1 | 59.930 |
| MobileNet_v2 | CE+penalty | 37553 | 0.226 | 0.2 | |
| MobileNet_v2 | CE+penalty | 35371 | 0.2062 | 0.3 | |
| MobileNet_v2 | CE+penalty | 33231 | 0.1838 | 0.4 | |
| MobileNet_v2 | CE+penalty | 30888 | 0.15675 | 0.5 | |
| MobileNet_v2 | CE+penalty | 28579 | 0.12813 | 0.6 | |
| MobileNet_v2 | CE+penalty | 25817 | 0.0893 | 0.7 | |
| MobileNet_v2 | CE+penalty | 21334 | 0.01260 | 0.8 | |
| MobileNet_v2 | CE+penalty | 17731 | 0 | 0.9 |
效果不太行
删除前
[5000. 5000. 5000. 5000. 5000. 5000. 5000. 5000. 5000. 1452.]
阈值0.1删除后
[6566. 7501. 874. 4127. 978. 3968. 4143. 6931. 4414. 1452.]
| Backbone | loss | sample number | noise rate(sym) | threshold | ACC(%) |
|---|---|---|---|---|---|
| MobileNet_v2 | CE+penalty | 50000 | 0.3608 | 0 | 60.0% |
| MobileNet_v2 | CE+penalty | 40322 | 0.337 | 0.1 | 71.2% |
| MobileNet_v2 | CE+penalty | 37390 | 0.3287 | 0.2 | |
| MobileNet_v2 | CE+penalty | 35492 | 0.3226 | 0.3 | |
| MobileNet_v2 | CE+penalty | 34116 | 0.3183 | 0.4 | |
| MobileNet_v2 | CE+penalty | 32677 | 0.3139 | 0.5 | |
| MobileNet_v2 | CE+penalty | 31048 | 0.3114 | 0.6 | |
| MobileNet_v2 | CE+penalty | 28944 | 0.3061 | 0.7 | |
| MobileNet_v2 | CE+penalty | 26151 | 0.2993 | 0.8 | |
| MobileNet_v2 | CE+penalty | 21130 | 0.2909 | 0.9 |
clean label
[5000. 5000. 5000. 5000. 5000. 5000. 5000. 5000. 5000. 5000.]
noise label
[5024. 4874. 4944. 5011. 5081. 5062. 5033. 5037. 4948. 4986.]
noise label 0.1 40322
[3376. 2860. 3289. 3261. 3965. 3088. 2746. 3031. 3016. 3167.]
CIFAR-100
[1] Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In NIPS, pp. 1195–1204, 2017
[2] Pereyra, Gabriel, et al. “Regularizing neural networks by penalizing confident output distributions.” arXiv preprint arXiv:1701.06548 (2017).
[3] Pengfei Chen, Benben Liao, Guangyong Chen, and Shengyu Zhang. Understanding and utilizing deep neural networks trained with noisy labels. In ICML, pp. 1062–1070, 2019.

若有收获,就点个赞吧
0 人点赞
