Li, Junnan, et al. “Learning to learn from noisy labeled data.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
论文:链接
代码:https://github.com/LiJunnan1992/MLNT
关键词: “synthetic noisy labels” ,“noise-tolerant” , “underlying knowledge”
为了消除noise label的负面影响,本文提出了一种noise-tolerant training algorithm。该算法模拟现实训练通过生成合成噪声label。
Introduction
背景:Deep learning network现今取得重大成果,是因为大量的标注数据集的存在如ImageNet和COCO。然而去搜集高质量的大量标注数据是十分耗时和成本很高的,通过搜索引擎和社交媒体网站可以以很低的成本获得标注的文件,然而这些数据带有大量的noise label。
解决办法:对于每一个小的mini-batch,论文中提出了一个meta-objective去训练模型,在CNN迭代更新之后,model具有更强的鲁棒性而不会过拟合noise label。
Contributions主要分为以下两个部分:
- Propose a noise-tolerant training algorithm, where a meta-objective is optimized before conventional training
- 使用合成noise labels训练模型的输出应该和teacher model的输出保持一致,通过self-ensembling method来构建teacher model使得,使其更可靠不受noise label的影响。**
Methodology
如下图所示,左边:传统的梯度更新会拟合noise label。 右边:预先产生合成的noise label进行meta-learning,使得网络参数更新是noise-tolerant和防止过拟合noise label。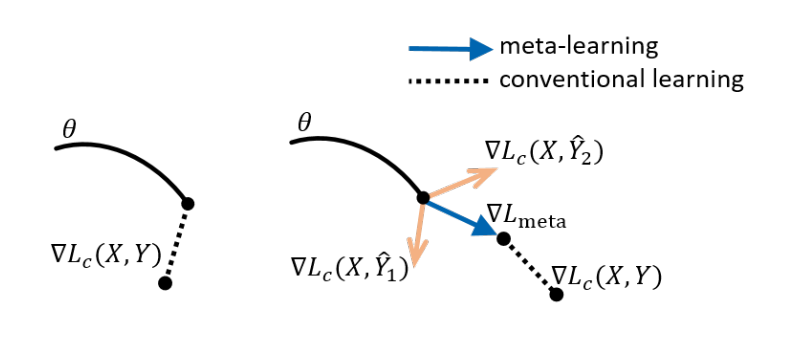
Problem Statement
对于分类问题,首先有个training set: ,
, 指的是第
指的是第 个sample,
个sample, 是一个one-hot vector代表noise label。
是一个one-hot vector代表noise label。 代表特征提取器discriminative feature提取,这个提取器maps 输入到一个c类的softmax 输出。传统的交叉熵loss如下:
代表特征提取器discriminative feature提取,这个提取器maps 输入到一个c类的softmax 输出。传统的交叉熵loss如下: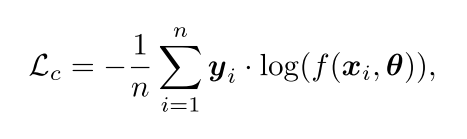
在这个公式中 包含着noise label,因此论文中提出了meta learning去学习一个noise- tolerant parameters。
包含着noise label,因此论文中提出了meta learning去学习一个noise- tolerant parameters。
Meta-Learning based Noise-Tolerant Training
为了去学习一个noise-tolerant parameters,论文中使用一个meta-learning update的方式在一个mini-batch上。具体的,对于每一个mini batch,产生很多synthetic noisy labels在相同的image上,然后更新网络使用这些noise label,最后和一个没有noise label训出来的teacher network进行对齐。
最终网络可以学习到less sensitive to label noise的参数。
Meta-Train
在每个 training step,考虑 来自training set,
来自training set, 来自于 corresponding noisy labels。作者想产生和
来自于 corresponding noisy labels。作者想产生和 同分布的合成噪声
同分布的合成噪声 。
。
具体咋操作?首先从mini batch随机采样 个sample
个sample ,对于每个进行排序,随机取
,对于每个进行排序,随机取 从10个neighbors,然后使用这个neighbor’s label取代替的label作为一个noise label
从10个neighbors,然后使用这个neighbor’s label取代替的label作为一个noise label  。因为transfer labels among neighbors,所以产生的noise label和原数据中的noise是相同分布的。
。因为transfer labels among neighbors,所以产生的noise label和原数据中的noise是相同分布的。
因此对于每一个mini batch,更新参数如下: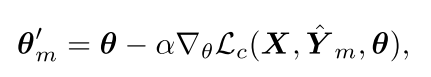
Meta-Test.
为了使得student network更新的参数具有更好的noise-tolerant能力,作者将student的输出和teacher的输出在mini batch上进行强行对齐,如下所示: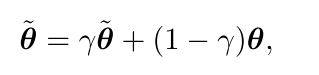
 代表teacher 网络的参数,
代表teacher 网络的参数, 代表student 网络的参数。
代表student 网络的参数。 表示smoothing coefficient hyper-parameter。由于teacher网络没有合成的noise label,因此将student网络和teacher网络进行强行对齐会使得student网络更鲁邦,论文中用Kullback-Leibler (KL) divergence进行对齐:
表示smoothing coefficient hyper-parameter。由于teacher网络没有合成的noise label,因此将student网络和teacher网络进行强行对齐会使得student网络更鲁邦,论文中用Kullback-Leibler (KL) divergence进行对齐: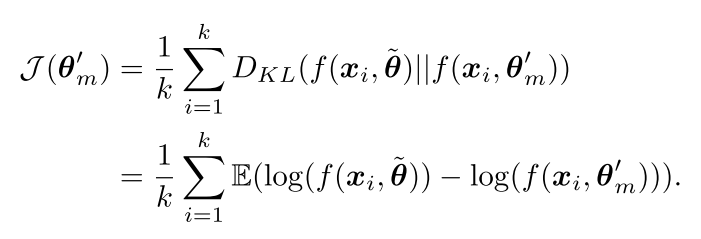
 是teacher网络的softmax的预测输出,
是teacher网络的softmax的预测输出, 是student的softmax的输出,
是student的softmax的输出,
Iterative Training
其次论文中提出了一个迭代训练来达到两个目的:
- Remove掉一些有潜在wrong label的样本从分类loss
- 提升teacher网络的性能,使得consistency loss更高效。
具体实现:
对于第一个目的,从第二个training iteration开始,使用上一个training iteration比较好的表现模型metor对sample进行评估,对于那些loss比较大的the ground-truth class会过滤掉,
对于第二个目的,通过merging mentor模型和teacher模型的预测去产生更合理的预测。实现如下: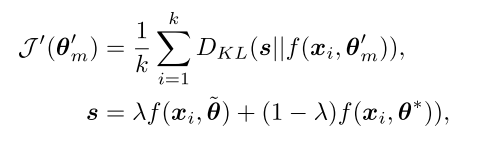
 是一个权重。
是一个权重。
Experiments

若有收获,就点个赞吧
0 人点赞
